MATEval: A Multi-Agent Discussion Framework for Advancing Open-Ended Text Evaluation
2403.19305
0
0
Abstract
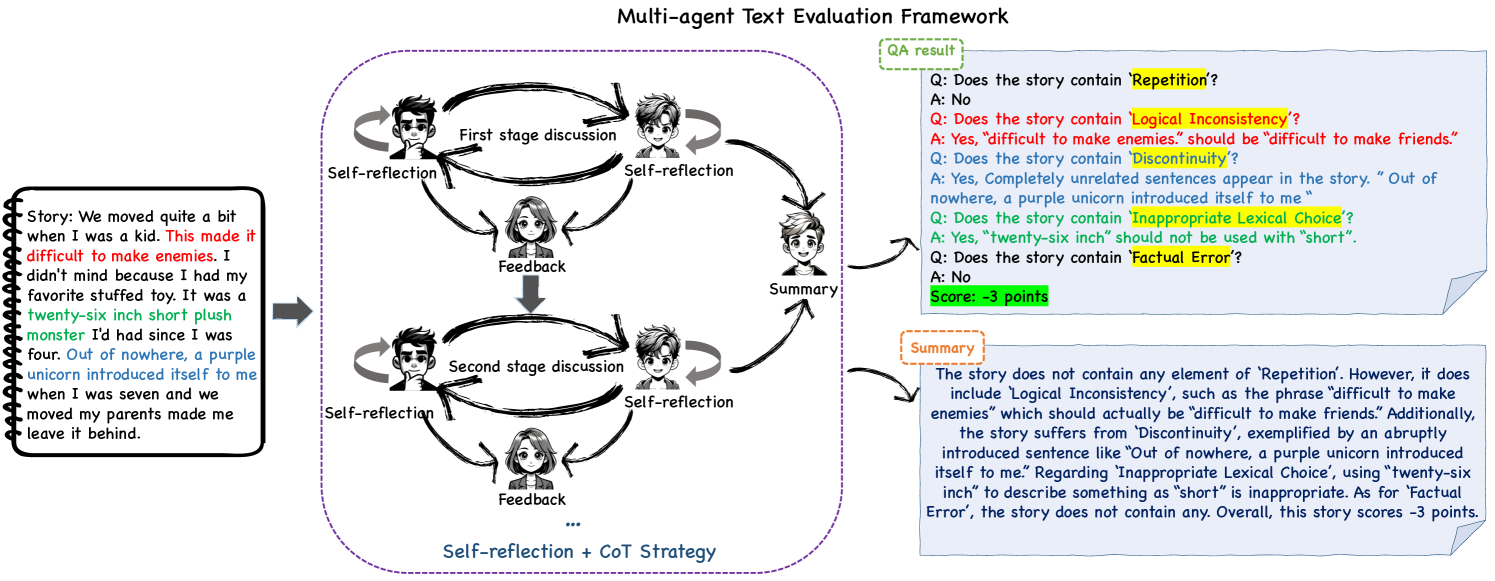
Recent advancements in generative Large Language Models(LLMs) have been remarkable, however, the quality of the text generated by these models often reveals persistent issues. Evaluating the quality of text generated by these models, especially in open-ended text, has consistently presented a significant challenge. Addressing this, recent work has explored the possibility of using LLMs as evaluators. While using a single LLM as an evaluation agent shows potential, it is filled with significant uncertainty and instability. To address these issues, we propose the MATEval: A Multi-Agent Text Evaluation framework where all agents are played by LLMs like GPT-4. The MATEval framework emulates human collaborative discussion methods, integrating multiple agents' interactions to evaluate open-ended text. Our framework incorporates self-reflection and Chain-of-Thought (CoT) strategies, along with feedback mechanisms, enhancing the depth and breadth of the evaluation process and guiding discussions towards consensus, while the framework generates comprehensive evaluation reports, including error localization, error types and scoring. Experimental results show that our framework outperforms existing open-ended text evaluation methods and achieves the highest correlation with human evaluation, which confirms the effectiveness and advancement of our framework in addressing the uncertainties and instabilities in evaluating LLMs-generated text. Furthermore, our framework significantly improves the efficiency of text evaluation and model iteration in industrial scenarios.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- MATEval is a new framework for evaluating open-ended text generation using a multi-agent discussion model.
- The goal is to improve the evaluation of large language models (LLMs) by having them engage in multi-agent dialogues, rather than relying on single-agent prompts.
- This allows for more nuanced and contextual evaluation of LLM capabilities, such as coherence, logical reasoning, and social awareness.
Plain English Explanation
MATEval is a new way to evaluate how well large language models (LLMs) can engage in open-ended discussions. Instead of just asking the model to respond to a single prompt, MATEval sets up a multi-agent conversation where the LLM has to interact with other "agents" in a back-and-forth dialogue.
This allows for a more realistic and comprehensive assessment of the LLM's abilities. Rather than just seeing how the model responds to one isolated prompt, researchers can evaluate things like the model's coherence, its ability to reason logically, and how socially aware it is during the conversation.
The key idea is that having multiple agents participate in a discussion creates a more complex and contextual environment, which better reflects how language is used in the real world. This can provide deeper insights into the strengths and limitations of LLMs compared to traditional single-prompt evaluations.
Technical Explanation
MATEval is a framework that uses a multi-agent setup to evaluate the performance of large language models (LLMs) on open-ended text generation tasks. Rather than relying on single-agent prompts, MATEval creates a conversational environment where multiple agents exchange messages, allowing for a more nuanced assessment of LLM capabilities.
The core of the MATEval methodology is a multi-agent discussion model, where each agent is an instance of the LLM being evaluated. These agents take turns generating responses, with the goal of engaging in a coherent and meaningful dialogue. Researchers can then analyze various aspects of the conversation, such as the logical flow of ideas, the social awareness displayed by the agents, and the overall quality and consistency of the generated text.
By embedding the LLM in a multi-agent setting, MATEval aims to capture a more realistic representation of how language is used in the real world, where individuals engage in back-and-forth exchanges and must consider the context and nuances of the conversation. This approach contrasts with traditional single-prompt evaluations, which may not fully reflect the LLM's ability to handle the complexity and dynamics of open-ended discussions.
The MATEval framework also includes mechanisms for collecting human feedback and ratings on the generated dialogues, allowing researchers to compare the performance of LLMs against human-level benchmarks. This can provide valuable insights into the strengths and limitations of current LLM technology, and help guide future advancements in open-ended text generation.
Critical Analysis
The MATEval framework represents an important step forward in the evaluation of large language models, as it addresses some of the limitations of traditional single-prompt approaches. By incorporating a multi-agent setup, the researchers are able to assess LLM capabilities in a more contextual and realistic setting.
However, the MATEval approach also faces some potential challenges. Ensuring coherence and logical consistency across a multi-agent dialogue can be a highly complex task, and the researchers may need to carefully design the interaction protocols and evaluation metrics to avoid biases or oversimplifications.
Additionally, the reliance on human feedback and ratings for benchmarking raises questions about the scalability and objectivity of the approach. Gathering high-quality human judgments on open-ended dialogues can be resource-intensive, and there may be inherent biases or subjectivity in these assessments.
Further research would be needed to explore the robustness and generalizability of the MATEval framework, as well as to investigate potential ways to automate or streamline the evaluation process. Comparisons to other multi-agent or dialogue-focused evaluation frameworks, such as METAL, FreeEval, or CMaT, could also provide useful insights.
Conclusion
The MATEval framework represents an important step forward in the evaluation of large language models, moving beyond traditional single-prompt assessments to a more contextual, multi-agent approach. By embedding LLMs in a conversational environment, researchers can gain deeper insights into the models' capabilities, such as coherence, logical reasoning, and social awareness.
While the MATEval approach faces some potential challenges, such as ensuring the scalability and objectivity of the human feedback process, it holds promise as a valuable tool for advancing the state of the art in open-ended text generation. As the field of natural language processing continues to evolve, frameworks like MATEval will be essential for driving progress and ensuring that large language models can reliably and safely interact with humans in real-world settings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

METAL: Towards Multilingual Meta-Evaluation
Rishav Hada, Varun Gumma, Mohamed Ahmed, Kalika Bali, Sunayana Sitaram
0
0
With the rising human-like precision of Large Language Models (LLMs) in numerous tasks, their utilization in a variety of real-world applications is becoming more prevalent. Several studies have shown that LLMs excel on many standard NLP benchmarks. However, it is challenging to evaluate LLMs due to test dataset contamination and the limitations of traditional metrics. Since human evaluations are difficult to collect, there is a growing interest in the community to use LLMs themselves as reference-free evaluators for subjective metrics. However, past work has shown that LLM-based evaluators can exhibit bias and have poor alignment with human judgments. In this study, we propose a framework for an end-to-end assessment of LLMs as evaluators in multilingual scenarios. We create a carefully curated dataset, covering 10 languages containing native speaker judgments for the task of summarization. This dataset is created specifically to evaluate LLM-based evaluators, which we refer to as meta-evaluation (METAL). We compare the performance of LLM-based evaluators created using GPT-3.5-Turbo, GPT-4, and PaLM2. Our results indicate that LLM-based evaluators based on GPT-4 perform the best across languages, while GPT-3.5-Turbo performs poorly. Additionally, we perform an analysis of the reasoning provided by LLM-based evaluators and find that it often does not match the reasoning provided by human judges.
4/3/2024
FreeEval: A Modular Framework for Trustworthy and Efficient Evaluation of Large Language Models
Zhuohao Yu, Chang Gao, Wenjin Yao, Yidong Wang, Zhengran Zeng, Wei Ye, Jindong Wang, Yue Zhang, Shikun Zhang
0
0
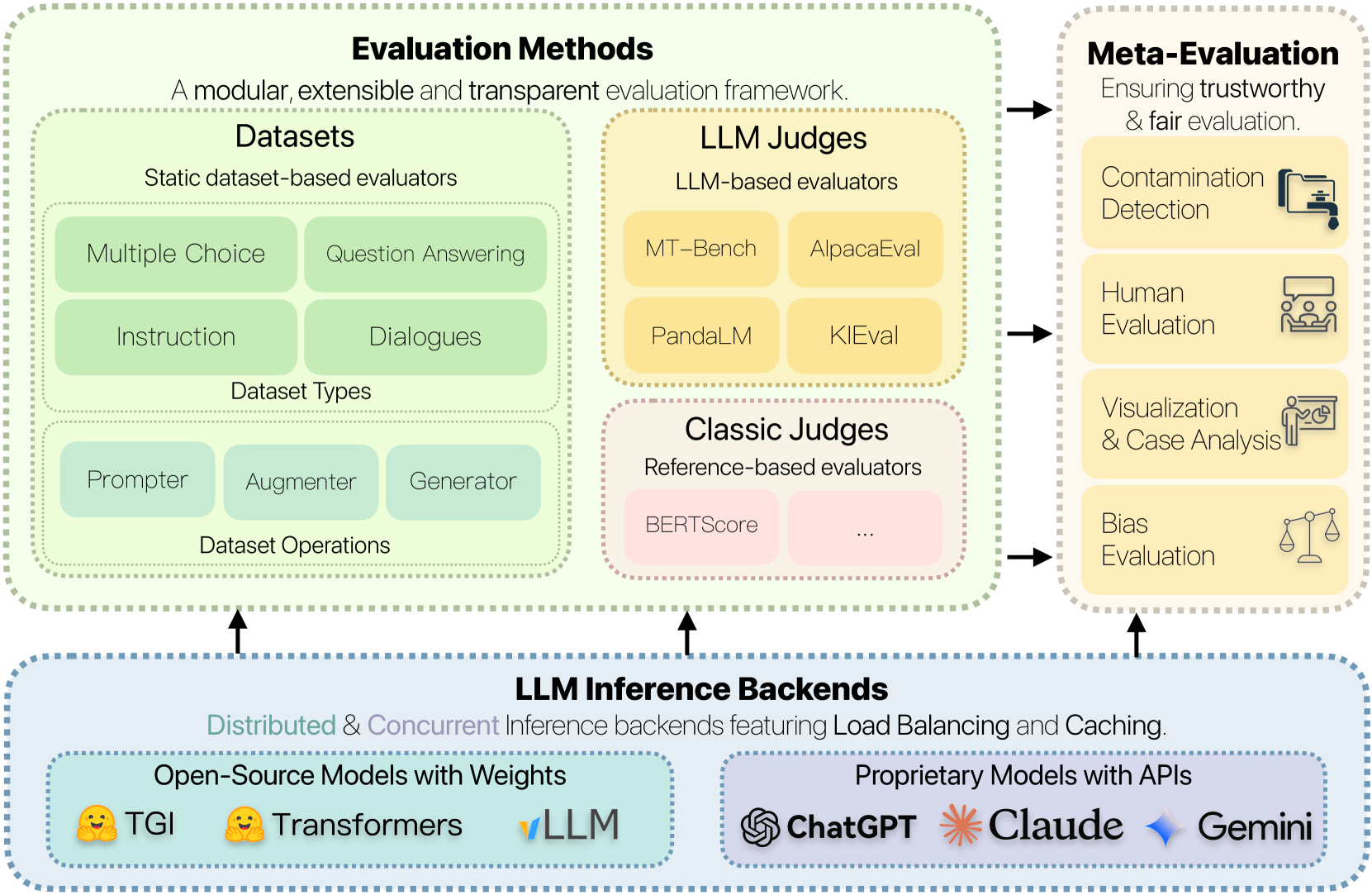
The rapid development of large language model (LLM) evaluation methodologies and datasets has led to a profound challenge: integrating state-of-the-art evaluation techniques cost-effectively while ensuring reliability, reproducibility, and efficiency. Currently, there is a notable absence of a unified and adaptable framework that seamlessly integrates various evaluation approaches. Moreover, the reliability of evaluation findings is often questionable due to potential data contamination, with the evaluation efficiency commonly overlooked when facing the substantial costs associated with LLM inference. In response to these challenges, we introduce FreeEval, a modular and scalable framework crafted to enable trustworthy and efficient automatic evaluations of LLMs. Firstly, FreeEval's unified abstractions simplify the integration and improve the transparency of diverse evaluation methodologies, encompassing dynamic evaluation that demand sophisticated LLM interactions. Secondly, the framework integrates meta-evaluation techniques like human evaluation and data contamination detection, which, along with dynamic evaluation modules in the platform, enhance the fairness of the evaluation outcomes. Lastly, FreeEval is designed with a high-performance infrastructure, including distributed computation and caching strategies, enabling extensive evaluations across multi-node, multi-GPU clusters for open-source and proprietary LLMs.
4/10/2024
New!DEBATE: Devil's Advocate-Based Assessment and Text Evaluation
Alex Kim, Keonwoo Kim, Sangwon Yoon
0
0
As natural language generation (NLG) models have become prevalent, systematically assessing the quality of machine-generated texts has become increasingly important. Recent studies introduce LLM-based evaluators that operate as reference-free metrics, demonstrating their capability to adeptly handle novel tasks. However, these models generally rely on a single-agent approach, which, we argue, introduces an inherent limit to their performance. This is because there exist biases in LLM agent's responses, including preferences for certain text structure or content. In this work, we propose DEBATE, an NLG evaluation framework based on multi-agent scoring system augmented with a concept of Devil's Advocate. Within the framework, one agent is instructed to criticize other agents' arguments, potentially resolving the bias in LLM agent's answers. DEBATE substantially outperforms the previous state-of-the-art methods in two meta-evaluation benchmarks in NLG evaluation, SummEval and TopicalChat. We also show that the extensiveness of debates among agents and the persona of an agent can influence the performance of evaluators.
5/17/2024
🏋️
Evaluating Students' Open-ended Written Responses with LLMs: Using the RAG Framework for GPT-3.5, GPT-4, Claude-3, and Mistral-Large
Jussi S. Jauhiainen, Agust'in Garagorry Guerra
0
0
Evaluating open-ended written examination responses from students is an essential yet time-intensive task for educators, requiring a high degree of effort, consistency, and precision. Recent developments in Large Language Models (LLMs) present a promising opportunity to balance the need for thorough evaluation with efficient use of educators' time. In our study, we explore the effectiveness of LLMs ChatGPT-3.5, ChatGPT-4, Claude-3, and Mistral-Large in assessing university students' open-ended answers to questions made about reference material they have studied. Each model was instructed to evaluate 54 answers repeatedly under two conditions: 10 times (10-shot) with a temperature setting of 0.0 and 10 times with a temperature of 0.5, expecting a total of 1,080 evaluations per model and 4,320 evaluations across all models. The RAG (Retrieval Augmented Generation) framework was used as the framework to make the LLMs to process the evaluation of the answers. As of spring 2024, our analysis revealed notable variations in consistency and the grading outcomes provided by studied LLMs. There is a need to comprehend strengths and weaknesses of LLMs in educational settings for evaluating open-ended written responses. Further comparative research is essential to determine the accuracy and cost-effectiveness of using LLMs for educational assessments.
5/10/2024