Cobra: Extending Mamba to Multi-Modal Large Language Model for Efficient Inference

0
Sign in to get full access
Overview
- Introduces "Cobra", an extension of the Mamba multi-modal large language model (MLLM) for efficient inference
- Focuses on improving the computational efficiency of Mamba while maintaining its multi-modal capabilities
- Proposes a state space model and optimization techniques to achieve this goal
Plain English Explanation
The paper introduces "Cobra", a new model that builds on the capabilities of the existing Mamba multi-modal large language model. Mamba is a powerful AI system that can process and understand information from multiple sources, like text, images, and audio. However, running Mamba can be computationally intensive, which limits its practical applications.
Cobra aims to address this by introducing a new state space model and optimization techniques to make the inference process more efficient. The state space model allows Cobra to better manage the computational resources required to run the model, while the optimization techniques help further reduce the overall computational load.
The key idea is to balance the model's ability to understand diverse inputs with the need for it to run quickly and use less computing power. By achieving this balance, Cobra can bring the benefits of multi-modal language models to a wider range of real-world applications that have strict computational constraints.
Technical Explanation
The paper introduces "Cobra", an extension of the Mamba multi-modal large language model (MLLM) that focuses on improving its computational efficiency. Mamba is a powerful AI system capable of processing and understanding information from multiple modalities, such as text, images, and audio. However, the high computational cost of running Mamba has limited its practical applications.
To address this, the authors propose a state space model and optimization techniques to make the inference process more efficient while maintaining Mamba's multi-modal capabilities. The state space model allows Cobra to better manage the computational resources required to run the model, while the optimization techniques help further reduce the overall computational load.
The key innovation is the introduction of a state space representation that captures the relationships between the different modalities in the MLLM. This state space model is then used to develop efficient inference algorithms that can dynamically allocate computing resources based on the specific input and output requirements of the task at hand. The authors also explore techniques like feature enhancement and attention modeling to further optimize the computational efficiency of the model.
Throughout the paper, the authors draw insights from related work on multi-modal fusion and coupled MLLM architectures to inform the design of Cobra.
Critical Analysis
The paper presents a compelling approach to improving the computational efficiency of multi-modal large language models, which is a crucial challenge in the field. The authors' use of a state space model and optimization techniques is a novel and promising direction, and the connections they make to related work in the area of multi-modal fusion and coupled architectures are insightful.
However, the paper does not provide a detailed evaluation of Cobra's performance compared to Mamba or other state-of-the-art MLLM models. While the authors mention that Cobra maintains Mamba's multi-modal capabilities, more comprehensive experiments and comparisons would be helpful to fully assess the benefits and trade-offs of their approach.
Additionally, the paper could have explored potential limitations or edge cases of the Cobra model, such as its performance on specific types of multi-modal inputs or its scalability to larger-scale models and datasets. Discussing these aspects would help readers gain a more nuanced understanding of the strengths and weaknesses of the proposed approach.
Conclusion
The "Cobra" paper presents a novel extension of the Mamba multi-modal large language model that focuses on improving its computational efficiency. By introducing a state space model and optimization techniques, the authors demonstrate a promising approach to balancing the powerful multi-modal capabilities of Mamba with the need for practical, real-world applications that have strict computational constraints.
The paper's insights into the role of state space representations and optimization in MLLM models, as well as its connections to related work in multi-modal fusion and coupled architectures, make it a valuable contribution to the ongoing research in this field. While the paper could have provided more comprehensive evaluations and discussions of potential limitations, the Cobra model represents an important step forward in making advanced multi-modal AI systems more accessible and deployable in a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Cobra: Extending Mamba to Multi-Modal Large Language Model for Efficient Inference
Han Zhao, Min Zhang, Wei Zhao, Pengxiang Ding, Siteng Huang, Donglin Wang
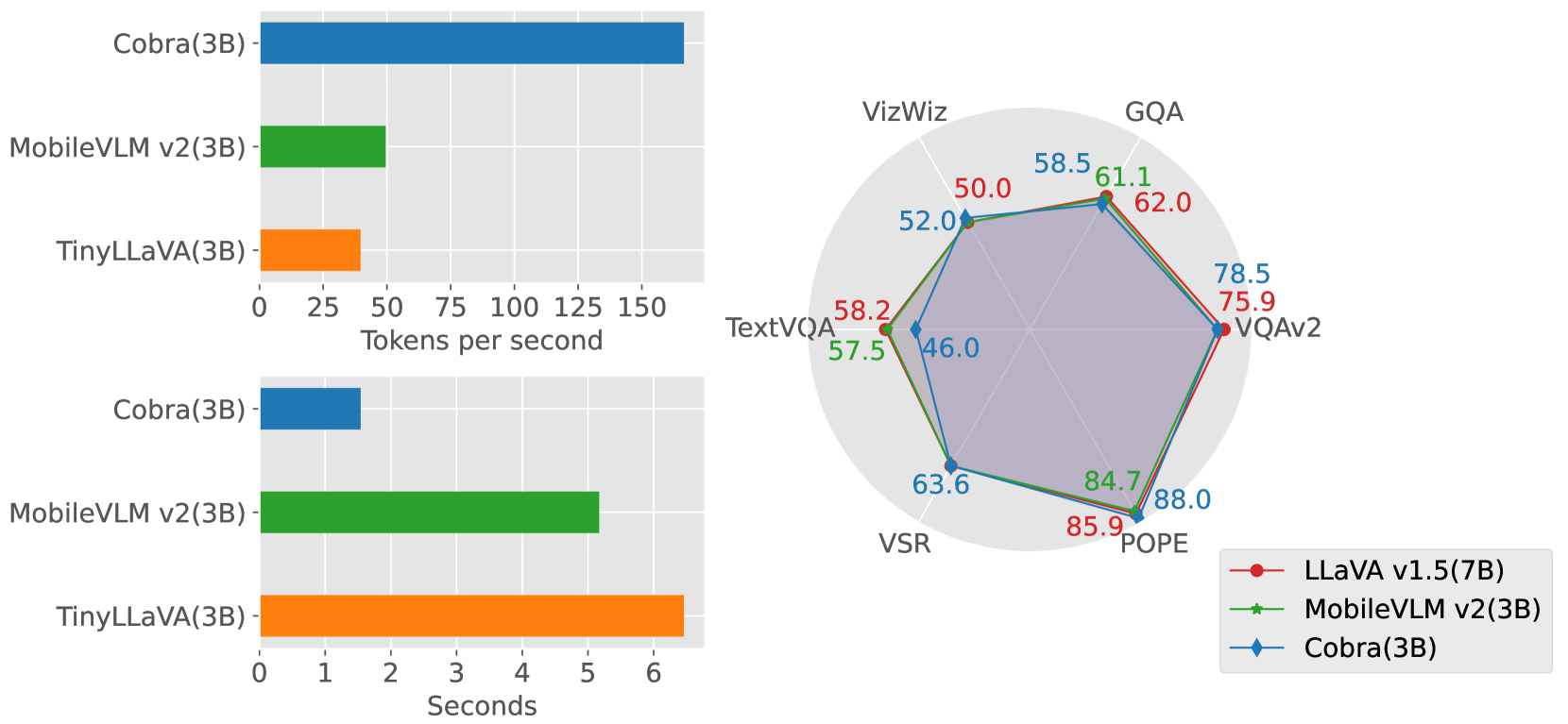
In recent years, the application of multimodal large language models (MLLM) in various fields has achieved remarkable success. However, as the foundation model for many downstream tasks, current MLLMs are composed of the well-known Transformer network, which has a less efficient quadratic computation complexity. To improve the efficiency of such basic models, we propose Cobra, a linear computational complexity MLLM. Specifically, Cobra integrates the efficient Mamba language model into the visual modality. Moreover, we explore and study various modal fusion schemes to create an effective multi-modal Mamba. Extensive experiments demonstrate that (1) Cobra achieves extremely competitive performance with current computationally efficient state-of-the-art methods, e.g., LLaVA-Phi, TinyLLaVA, and MobileVLM v2, and has faster speed due to Cobra's linear sequential modeling. (2) Interestingly, the results of closed-set challenging prediction benchmarks show that Cobra performs well in overcoming visual illusions and spatial relationship judgments. (3) Notably, Cobra even achieves comparable performance to LLaVA with about 43% of the number of parameters. We will make all codes of Cobra open-source and hope that the proposed method can facilitate future research on complexity problems in MLLM. Our project page is available at: https://sites.google.com/view/cobravlm.
Read more6/6/2024

0
ML-Mamba: Efficient Multi-Modal Large Language Model Utilizing Mamba-2
Wenjun Huang, Jiakai Pan, Jiahao Tang, Yanyu Ding, Yifei Xing, Yuhe Wang, Zhengzhuo Wang, Jianguo Hu
Multimodal Large Language Models (MLLMs) have attracted much attention for their multifunctionality. However, traditional Transformer architectures incur significant overhead due to their secondary computational complexity. To address this issue, we introduce ML-Mamba, a multimodal language model, which utilizes the latest and efficient Mamba-2 model for inference. Mamba-2 is known for its linear scalability and fast processing of long sequences. We replace the Transformer-based backbone with a pre-trained Mamba-2 model and explore methods for integrating 2D visual selective scanning mechanisms into multimodal learning while also trying various visual encoders and Mamba-2 model variants. Our extensive experiments in various multimodal benchmark tests demonstrate the competitive performance of ML-Mamba and highlight the potential of state space models in multimodal tasks. The experimental results show that: (1) we empirically explore how to effectively apply the 2D vision selective scan mechanism for multimodal learning. We propose a novel multimodal connector called the Mamba-2 Scan Connector (MSC), which enhances representational capabilities. (2) ML-Mamba achieves performance comparable to state-of-the-art methods such as TinyLaVA and MobileVLM v2 through its linear sequential modeling while faster inference speed; (3) Compared to multimodal models utilizing Mamba-1, the Mamba-2-based ML-Mamba exhibits superior inference performance and effectiveness.
Read more8/22/2024

0
RoboMamba: Multimodal State Space Model for Efficient Robot Reasoning and Manipulation
Jiaming Liu, Mengzhen Liu, Zhenyu Wang, Lily Lee, Kaichen Zhou, Pengju An, Senqiao Yang, Renrui Zhang, Yandong Guo, Shanghang Zhang
A fundamental objective in robot manipulation is to enable models to comprehend visual scenes and execute actions. Although existing robot Multimodal Large Language Models (MLLMs) can handle a range of basic tasks, they still face challenges in two areas: 1) inadequate reasoning ability to tackle complex tasks, and 2) high computational costs for MLLM fine-tuning and inference. The recently proposed state space model (SSM) known as Mamba demonstrates promising capabilities in non-trivial sequence modeling with linear inference complexity. Inspired by this, we introduce RoboMamba, an end-to-end robotic MLLM that leverages the Mamba model to deliver both robotic reasoning and action capabilities, while maintaining efficient fine-tuning and inference. Specifically, we first integrate the vision encoder with Mamba, aligning visual data with language embedding through co-training, empowering our model with visual common sense and robot-related reasoning. To further equip RoboMamba with action pose prediction abilities, we explore an efficient fine-tuning strategy with a simple policy head. We find that once RoboMamba possesses sufficient reasoning capability, it can acquire manipulation skills with minimal fine-tuning parameters (0.1% of the model) and time (20 minutes). In experiments, RoboMamba demonstrates outstanding reasoning capabilities on general and robotic evaluation benchmarks. Meanwhile, our model showcases impressive pose prediction results in both simulation and real-world experiments, achieving inference speeds 7 times faster than existing robot MLLMs. Our project web page: https://sites.google.com/view/robomamba-web
Read more6/7/2024

0
Why mamba is effective? Exploit Linear Transformer-Mamba Network for Multi-Modality Image Fusion
Chenguang Zhu, Shan Gao, Huafeng Chen, Guangqian Guo, Chaowei Wang, Yaoxing Wang, Chen Shu Lei, Quanjiang Fan
Multi-modality image fusion aims to integrate the merits of images from different sources and render high-quality fusion images. However, existing feature extraction and fusion methods are either constrained by inherent local reduction bias and static parameters during inference (CNN) or limited by quadratic computational complexity (Transformers), and cannot effectively extract and fuse features. To solve this problem, we propose a dual-branch image fusion network called Tmamba. It consists of linear Transformer and Mamba, which has global modeling capabilities while maintaining linear complexity. Due to the difference between the Transformer and Mamba structures, the features extracted by the two branches carry channel and position information respectively. T-M interaction structure is designed between the two branches, using global learnable parameters and convolutional layers to transfer position and channel information respectively. We further propose cross-modal interaction at the attention level to obtain cross-modal attention. Experiments show that our Tmamba achieves promising results in multiple fusion tasks, including infrared-visible image fusion and medical image fusion. Code with checkpoints will be available after the peer-review process.
Read more9/6/2024