Code Agents are State of the Art Software Testers
2406.12952
0
0

Abstract
Rigorous software testing is crucial for developing and maintaining high-quality code, making automated test generation a promising avenue for both improving software quality and boosting the effectiveness of code generation methods. However, while code generation with Large Language Models (LLMs) is an extraordinarily active research area, test generation remains relatively unexplored. We address this gap and investigate the capability of LLM-based Code Agents for formalizing user issues into test cases. To this end, we propose a novel benchmark based on popular GitHub repositories, containing real-world issues, ground-truth patches, and golden tests. We find that LLMs generally perform surprisingly well at generating relevant test cases with Code Agents designed for code repair exceeding the performance of systems designed specifically for test generation. Further, as test generation is a similar but more structured task than code generation, it allows for a more fine-grained analysis using fail-to-pass rate and coverage metrics, providing a dual metric for analyzing systems designed for code repair. Finally, we find that generated tests are an effective filter for proposed code fixes, doubling the precision of SWE-Agent.
Create account to get full access
Overview
- This paper introduces a new benchmark for evaluating test generation capabilities of software testing systems, with a focus on code agents.
- The benchmark includes a diverse set of programming problems and provides a standardized way to measure the effectiveness of test generation approaches.
- The authors evaluate several state-of-the-art test generation techniques, including large language models as test case generators, test-driven development code generation, and autonomous program improvement.
- The results suggest that code agents can outperform human developers in generating effective test cases, highlighting their potential as a powerful tool for software testing.
Plain English Explanation
The paper discusses a new way to evaluate how well different software testing systems can generate effective test cases. The authors created a diverse set of programming problems that can be used as a benchmark to compare the performance of various test generation approaches, including some state-of-the-art techniques like using large language models for generating test cases and automatically improving code through testing.
The key finding is that code agents, which are AI-powered software testing systems, can outperform human developers in generating effective test cases. This suggests that these code agents could be a powerful tool for improving software quality and catching bugs more efficiently than traditional manual testing methods.
Technical Explanation
The paper introduces a new benchmark for evaluating test generation capabilities, which the authors call the "Code Agent Benchmark". This benchmark includes a diverse set of programming problems that cover a range of complexity and domains, providing a standardized way to measure the effectiveness of different test generation techniques.
The authors evaluate several state-of-the-art approaches, including:
- Large language models as test case generators: Using large pre-trained language models to generate test cases.
- Test-driven development code generation: Generating code and tests simultaneously using a test-driven development approach.
- Autonomous program improvement: Automatically improving code through iterative testing and refactoring.
The results show that code agents, which combine several of these techniques, can outperform human developers in generating effective test cases for the benchmark problems. This suggests that code agents are a promising approach for automating software testing and improving software quality.
Critical Analysis
The paper provides a valuable contribution by introducing a standardized benchmark for evaluating test generation capabilities. This will help advance the field of software testing by enabling more rigorous and comparable evaluation of different techniques.
However, the paper does not address some potential limitations of the code agent approach. For example, the benchmark is focused on a limited set of programming problems, and it's unclear how well the code agents would perform on more complex, real-world software systems. Additionally, the paper does not discuss the potential ethical and societal implications of deploying such powerful testing systems in practice.
Further research is needed to explore the generalizability of the code agent approach, as well as to address potential issues around transparency, accountability, and the impact on software development workflows and human-AI collaboration.
Conclusion
This paper presents a new benchmark for evaluating test generation capabilities and demonstrates that code agents, which combine state-of-the-art techniques like large language models for test case generation and autonomous program improvement, can outperform human developers in this task.
These findings suggest that code agents have the potential to revolutionize software testing, improving quality and efficiency in ways that were previously not possible. As the technology continues to evolve, it will be important to address the limitations and potential risks, but the overall impact of this research could be significant for the software industry and the broader field of AI-powered automation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
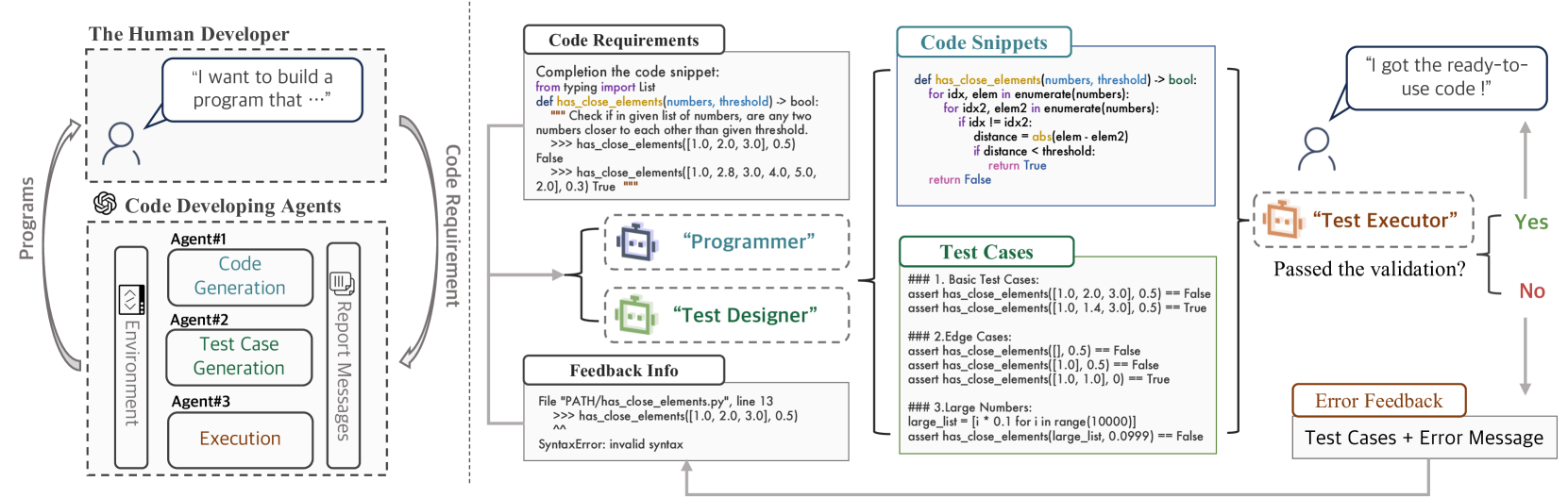
AgentCoder: Multi-Agent-based Code Generation with Iterative Testing and Optimisation
Dong Huang, Jie M. Zhang, Michael Luck, Qingwen Bu, Yuhao Qing, Heming Cui
0
0
The advancement of natural language processing (NLP) has been significantly boosted by the development of transformer-based large language models (LLMs). These models have revolutionized NLP tasks, particularly in code generation, aiding developers in creating software with enhanced efficiency. Despite their advancements, challenges in balancing code snippet generation with effective test case generation and execution persist. To address these issues, this paper introduces Multi-Agent Assistant Code Generation (AgentCoder), a novel solution comprising a multi-agent framework with specialized agents: the programmer agent, the test designer agent, and the test executor agent. During the coding procedure, the programmer agent will focus on the code generation and refinement based on the test executor agent's feedback. The test designer agent will generate test cases for the generated code, and the test executor agent will run the code with the test cases and write the feedback to the programmer. This collaborative system ensures robust code generation, surpassing the limitations of single-agent models and traditional methodologies. Our extensive experiments on 9 code generation models and 12 enhancement approaches showcase AgentCoder's superior performance over existing code generation models and prompt engineering techniques across various benchmarks. For example, AgentCoder (GPT-4) achieves 96.3% and 91.8% pass@1 in HumanEval and MBPP datasets with an overall token overhead of 56.9K and 66.3K, while state-of-the-art obtains only 90.2% and 78.9% pass@1 with an overall token overhead of 138.2K and 206.5K.
5/27/2024

Large Language Models as Test Case Generators: Performance Evaluation and Enhancement
Kefan Li, Yuan Yuan
0
0
Code generation with Large Language Models (LLMs) has been extensively studied and achieved remarkable progress. As a complementary aspect to code generation, test case generation is of crucial importance in ensuring the quality and reliability of code. However, using LLMs as test case generators has been much less explored. Current research along this line primarily focuses on enhancing code generation with assistance from test cases generated by LLMs, while the performance of LLMs in test case generation alone has not been comprehensively examined. To bridge this gap, we conduct extensive experiments to study how well LLMs can generate high-quality test cases. We find that as the problem difficulty increases, state-of-the-art LLMs struggle to generate correct test cases, largely due to their inherent limitations in computation and reasoning. To mitigate this issue, we further propose a multi-agent framework called emph{TestChain} that decouples the generation of test inputs and test outputs. Notably, TestChain uses a ReAct format conversation chain for LLMs to interact with a Python interpreter in order to provide more accurate test outputs. Our results indicate that TestChain outperforms the baseline by a large margin. Particularly, in terms of the accuracy of test cases, TestChain using GPT-4 as the backbone achieves a 13.84% improvement over the baseline on the LeetCode-hard dataset.
4/23/2024
Test-Driven Development for Code Generation
Noble Saji Mathews, Meiyappan Nagappan
0
0
Recent Large Language Models (LLMs) have demonstrated significant capabilities in generating code snippets directly from problem statements. This increasingly automated process mirrors traditional human-led software development, where code is often written in response to a requirement. Historically, Test-Driven Development (TDD) has proven its merit, requiring developers to write tests before the functional code, ensuring alignment with the initial problem statements. Applying TDD principles to LLM-based code generation offers one distinct benefit: it enables developers to verify the correctness of generated code against predefined tests. This paper investigates if and how TDD can be incorporated into AI-assisted code-generation processes. We experimentally evaluate our hypothesis that providing LLMs like GPT-4 and Llama 3 with tests in addition to the problem statements enhances code generation outcomes. We experimented with established function-level code generation benchmarks such as MBPP and HumanEval. Our results consistently demonstrate that including test cases leads to higher success in solving programming challenges. We assert that TDD is a promising paradigm for helping ensure that the code generated by LLMs effectively captures the requirements.
6/12/2024

AutoCodeRover: Autonomous Program Improvement
Yuntong Zhang, Haifeng Ruan, Zhiyu Fan, Abhik Roychoudhury
0
0
Researchers have made significant progress in automating the software development process in the past decades. Recent progress in Large Language Models (LLMs) has significantly impacted the development process, where developers can use LLM-based programming assistants to achieve automated coding. Nevertheless software engineering involves the process of program improvement apart from coding, specifically to enable software maintenance (e.g. bug fixing) and software evolution (e.g. feature additions). In this paper, we propose an automated approach for solving GitHub issues to autonomously achieve program improvement. In our approach called AutoCodeRover, LLMs are combined with sophisticated code search capabilities, ultimately leading to a program modification or patch. In contrast to recent LLM agent approaches from AI researchers and practitioners, our outlook is more software engineering oriented. We work on a program representation (abstract syntax tree) as opposed to viewing a software project as a mere collection of files. Our code search exploits the program structure in the form of classes/methods to enhance LLM's understanding of the issue's root cause, and effectively retrieve a context via iterative search. The use of spectrum based fault localization using tests, further sharpens the context, as long as a test-suite is available. Experiments on SWE-bench-lite which consists of 300 real-life GitHub issues show increased efficacy in solving GitHub issues (22-23% on SWE-bench-lite). On the full SWE-bench consisting of 2294 GitHub issues, AutoCodeRover solved around 16% of issues, which is higher than the efficacy of the recently reported AI software engineer Devin from Cognition Labs, while taking time comparable to Devin. We posit that our workflow enables autonomous software engineering, where, in future, auto-generated code from LLMs can be autonomously improved.
4/16/2024