Code Repair with LLMs gives an Exploration-Exploitation Tradeoff
2405.17503
0
0
🔍
Abstract
Iteratively improving and repairing source code with large language models (LLMs), known as refinement, has emerged as a popular way of generating programs that would be too complex to construct in one shot. Given a bank of test cases, together with a candidate program, an LLM can improve that program by being prompted with failed test cases. But it remains an open question how to best iteratively refine code, with prior work employing simple greedy or breadth-first strategies. We show here that refinement exposes an explore-exploit tradeoff: exploit by refining the program that passes the most test cases, or explore by refining a lesser considered program. We frame this as an arm-acquiring bandit problem, which we solve with Thompson Sampling. The resulting LLM-based program synthesis algorithm is broadly applicable: Across loop invariant synthesis, visual reasoning puzzles, and competition programming problems, we find that our new method can solve more problems using fewer language model calls.
Create account to get full access
Overview
- Iterative code refinement using large language models (LLMs) is an effective way to generate complex programs.
- Prior work has used simple strategies, but this paper explores the trade-off between exploiting the best-performing program and exploring less-considered programs.
- The authors frame this as an "arm-acquiring bandit problem" and solve it using Thompson Sampling, resulting in a more effective LLM-based program synthesis algorithm.
Plain English Explanation
Large language models (LLMs) can be used to iteratively improve and repair source code, a process known as "refinement." This is useful for generating programs that would be too complex to create in a single step. The process starts with a bank of test cases and a candidate program, and the LLM is prompted with failed test cases to improve the program.
Previous approaches have used simple strategies, like always focusing on the program that passes the most test cases. However, this paper shows that refinement involves a trade-off between two approaches:
- Exploit: Refine the program that currently passes the most test cases, to maximize the number of passing tests.
- Explore: Refine a less-considered program, to potentially discover a better solution.
The authors frame this as an "arm-acquiring bandit problem", which they solve using a technique called Thompson Sampling. This results in a more effective LLM-based program synthesis algorithm that can solve more problems using fewer language model calls, across tasks like loop invariant synthesis, visual reasoning puzzles, and competition programming problems.
Technical Explanation
The paper presents a new approach to iteratively refining source code using large language models (LLMs). The authors frame this as an "arm-acquiring bandit problem," where the goal is to choose which program to refine in each iteration to maximize the number of passing test cases.
The key insight is that refinement involves an explore-exploit trade-off. The algorithm can either "exploit" by refining the program that currently passes the most test cases, or "explore" by refining a less-considered program, which may lead to a better solution. The authors solve this using Thompson Sampling, a technique from the field of multi-armed bandits.
The resulting LLM-based program synthesis algorithm is evaluated on several tasks, including loop invariant synthesis, visual reasoning puzzles, and competition programming problems. The authors find that their new method can solve more problems using fewer language model calls compared to previous approaches.
Critical Analysis
The paper presents a novel and promising approach to iterative code refinement using LLMs. The authors' framing of the problem as an "arm-acquiring bandit problem" and their use of Thompson Sampling to solve it is a clever and well-justified technique.
One potential limitation of the research is the scope of the evaluated tasks. While the authors demonstrate the effectiveness of their method across several domains, it would be interesting to see how it performs on an even wider range of programming problems, including those with more complex control flow or data structures.
Additionally, the paper does not delve into the potential limitations or failure modes of the LLM-based program synthesis approach. It would be valuable to explore scenarios where the refinement process might struggle, such as when the initial candidate program is too far from the desired solution or when the test cases are not sufficiently informative.
Overall, this research represents an important step forward in the field of program synthesis using large language models. The authors' insights into the explore-exploit trade-off and their solution using Thompson Sampling are likely to inspire further advancements in this area.
Conclusion
This paper presents a novel approach to iteratively refining source code using large language models (LLMs), framing the problem as an "arm-acquiring bandit problem" and solving it with Thompson Sampling. The resulting LLM-based program synthesis algorithm is shown to be more effective than previous methods, solving more problems using fewer language model calls across a range of tasks, including loop invariant synthesis, visual reasoning puzzles, and competition programming problems.
The authors' insights into the explore-exploit trade-off inherent in code refinement and their innovative solution using techniques from the field of multi-armed bandits represent an important contribution to the growing body of research on program synthesis with large language models. This work paves the way for further advancements in this area, with potential applications in areas like automated software development, educational tools, and AI-assisted programming.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Training LLMs to Better Self-Debug and Explain Code
Nan Jiang, Xiaopeng Li, Shiqi Wang, Qiang Zhou, Soneya Binta Hossain, Baishakhi Ray, Varun Kumar, Xiaofei Ma, Anoop Deoras
0
0
In the domain of code generation, self-debugging is crucial. It allows LLMs to refine their generated code based on execution feedback. This is particularly important because generating correct solutions in one attempt proves challenging for complex tasks. Prior works on self-debugging mostly focus on prompting methods by providing LLMs with few-shot examples, which work poorly on small open-sourced LLMs. In this work, we propose a training framework that significantly improves self-debugging capability of LLMs. Intuitively, we observe that a chain of explanations on the wrong code followed by code refinement helps LLMs better analyze the wrong code and do refinement. We thus propose an automated pipeline to collect a high-quality dataset for code explanation and refinement by generating a number of explanations and refinement trajectories and filtering via execution verification. We perform supervised fine-tuning (SFT) and further reinforcement learning (RL) on both success and failure trajectories with a novel reward design considering code explanation and refinement quality. SFT improves the pass@1 by up to 15.92% and pass@10 by 9.30% over four benchmarks. RL training brings additional up to 3.54% improvement on pass@1 and 2.55% improvement on pass@10. The trained LLMs show iterative refinement ability, and can keep refining code continuously. Lastly, our human evaluation shows that the LLMs trained with our framework generate more useful code explanations and help developers better understand bugs in source code.
5/30/2024

AutoCodeRover: Autonomous Program Improvement
Yuntong Zhang, Haifeng Ruan, Zhiyu Fan, Abhik Roychoudhury
0
0
Researchers have made significant progress in automating the software development process in the past decades. Recent progress in Large Language Models (LLMs) has significantly impacted the development process, where developers can use LLM-based programming assistants to achieve automated coding. Nevertheless software engineering involves the process of program improvement apart from coding, specifically to enable software maintenance (e.g. bug fixing) and software evolution (e.g. feature additions). In this paper, we propose an automated approach for solving GitHub issues to autonomously achieve program improvement. In our approach called AutoCodeRover, LLMs are combined with sophisticated code search capabilities, ultimately leading to a program modification or patch. In contrast to recent LLM agent approaches from AI researchers and practitioners, our outlook is more software engineering oriented. We work on a program representation (abstract syntax tree) as opposed to viewing a software project as a mere collection of files. Our code search exploits the program structure in the form of classes/methods to enhance LLM's understanding of the issue's root cause, and effectively retrieve a context via iterative search. The use of spectrum based fault localization using tests, further sharpens the context, as long as a test-suite is available. Experiments on SWE-bench-lite which consists of 300 real-life GitHub issues show increased efficacy in solving GitHub issues (22-23% on SWE-bench-lite). On the full SWE-bench consisting of 2294 GitHub issues, AutoCodeRover solved around 16% of issues, which is higher than the efficacy of the recently reported AI software engineer Devin from Cognition Labs, while taking time comparable to Devin. We posit that our workflow enables autonomous software engineering, where, in future, auto-generated code from LLMs can be autonomously improved.
4/16/2024
🔮
Learning Performance-Improving Code Edits
Alexander Shypula, Aman Madaan, Yimeng Zeng, Uri Alon, Jacob Gardner, Milad Hashemi, Graham Neubig, Parthasarathy Ranganathan, Osbert Bastani, Amir Yazdanbakhsh
0
0
With the decline of Moore's law, optimizing program performance has become a major focus of software research. However, high-level optimizations such as API and algorithm changes remain elusive due to the difficulty of understanding the semantics of code. Simultaneously, pretrained large language models (LLMs) have demonstrated strong capabilities at solving a wide range of programming tasks. To that end, we introduce a framework for adapting LLMs to high-level program optimization. First, we curate a dataset of performance-improving edits made by human programmers of over 77,000 competitive C++ programming submission pairs, accompanied by extensive unit tests. A major challenge is the significant variability of measuring performance on commodity hardware, which can lead to spurious improvements. To isolate and reliably evaluate the impact of program optimizations, we design an environment based on the gem5 full system simulator, the de facto simulator used in academia and industry. Next, we propose a broad range of adaptation strategies for code optimization; for prompting, these include retrieval-based few-shot prompting and chain-of-thought, and for finetuning, these include performance-conditioned generation and synthetic data augmentation based on self-play. A combination of these techniques achieves a mean speedup of 6.86 with eight generations, higher than average optimizations from individual programmers (3.66). Using our model's fastest generations, we set a new upper limit on the fastest speedup possible for our dataset at 9.64 compared to using the fastest human submissions available (9.56).
4/29/2024
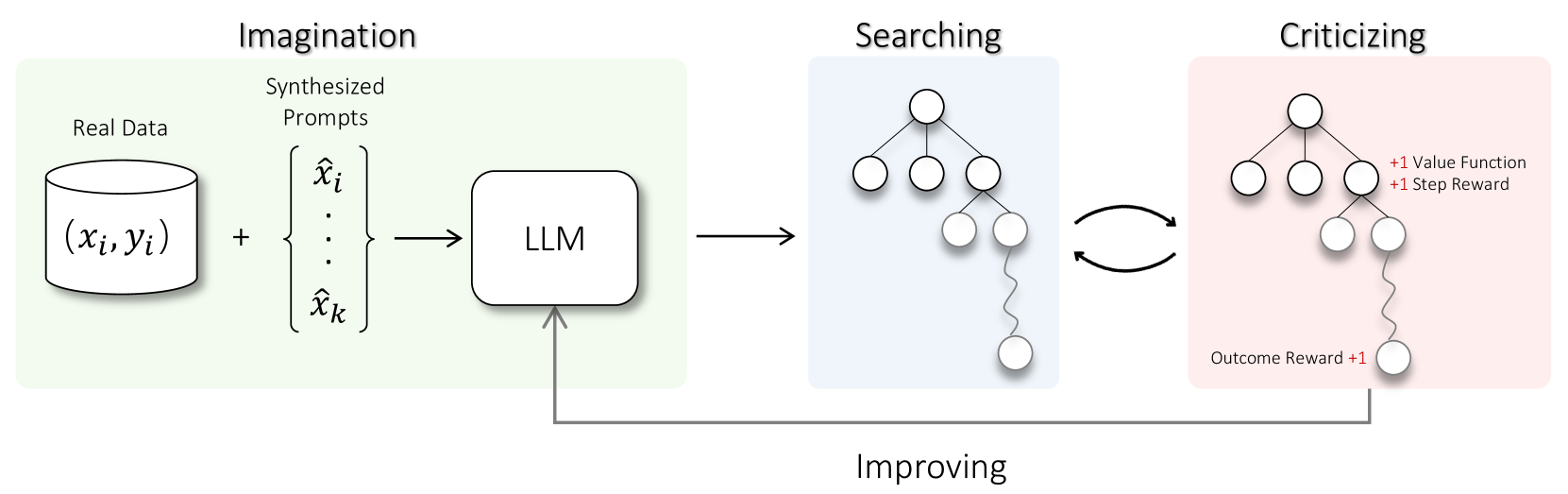
Toward Self-Improvement of LLMs via Imagination, Searching, and Criticizing
Ye Tian, Baolin Peng, Linfeng Song, Lifeng Jin, Dian Yu, Haitao Mi, Dong Yu
0
0
Despite the impressive capabilities of Large Language Models (LLMs) on various tasks, they still struggle with scenarios that involves complex reasoning and planning. Recent work proposed advanced prompting techniques and the necessity of fine-tuning with high-quality data to augment LLMs' reasoning abilities. However, these approaches are inherently constrained by data availability and quality. In light of this, self-correction and self-learning emerge as viable solutions, employing strategies that allow LLMs to refine their outputs and learn from self-assessed rewards. Yet, the efficacy of LLMs in self-refining its response, particularly in complex reasoning and planning task, remains dubious. In this paper, we introduce AlphaLLM for the self-improvements of LLMs, which integrates Monte Carlo Tree Search (MCTS) with LLMs to establish a self-improving loop, thereby enhancing the capabilities of LLMs without additional annotations. Drawing inspiration from the success of AlphaGo, AlphaLLM addresses the unique challenges of combining MCTS with LLM for self-improvement, including data scarcity, the vastness search spaces of language tasks, and the subjective nature of feedback in language tasks. AlphaLLM is comprised of prompt synthesis component, an efficient MCTS approach tailored for language tasks, and a trio of critic models for precise feedback. Our experimental results in mathematical reasoning tasks demonstrate that AlphaLLM significantly enhances the performance of LLMs without additional annotations, showing the potential for self-improvement in LLMs.
4/19/2024