Training LLMs to Better Self-Debug and Explain Code
2405.18649
0
0

Abstract
In the domain of code generation, self-debugging is crucial. It allows LLMs to refine their generated code based on execution feedback. This is particularly important because generating correct solutions in one attempt proves challenging for complex tasks. Prior works on self-debugging mostly focus on prompting methods by providing LLMs with few-shot examples, which work poorly on small open-sourced LLMs. In this work, we propose a training framework that significantly improves self-debugging capability of LLMs. Intuitively, we observe that a chain of explanations on the wrong code followed by code refinement helps LLMs better analyze the wrong code and do refinement. We thus propose an automated pipeline to collect a high-quality dataset for code explanation and refinement by generating a number of explanations and refinement trajectories and filtering via execution verification. We perform supervised fine-tuning (SFT) and further reinforcement learning (RL) on both success and failure trajectories with a novel reward design considering code explanation and refinement quality. SFT improves the pass@1 by up to 15.92% and pass@10 by 9.30% over four benchmarks. RL training brings additional up to 3.54% improvement on pass@1 and 2.55% improvement on pass@10. The trained LLMs show iterative refinement ability, and can keep refining code continuously. Lastly, our human evaluation shows that the LLMs trained with our framework generate more useful code explanations and help developers better understand bugs in source code.
Create account to get full access
Overview
• The paper explores training large language models (LLMs) to better self-debug and explain code, which could improve their usefulness for programming tasks.
• The researchers propose an approach involving feedback loops, iterative refinement, and the use of prompts to encourage LLMs to engage in self-debugging and explanation.
• The findings suggest this approach can lead to LLMs that are more reliable, transparent, and helpful when working with code.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text, including code. However, these models can sometimes make mistakes or struggle to explain their reasoning. <a href="https://aimodels.fyi/papers/arxiv/code-repair-llms-gives-exploration-exploitation-tradeoff">Previous research</a> has shown that LLMs can be trained to self-debug and explain their code, which could make them more useful for programming tasks.
The researchers in this paper propose an approach to train LLMs to be better at self-debugging and explaining code. The key ideas are:
- Providing the LLM with feedback loops, where it generates code, receives feedback on any issues, and then refines its output. This helps the model learn from its mistakes.
- Using prompts that encourage the LLM to explain its reasoning and identify potential problems in the code it generates. <a href="https://aimodels.fyi/papers/arxiv/chain-targeted-verification-questions-to-improve-reliability">Similar techniques</a> have been used to improve the reliability of LLMs in other contexts.
- Iteratively refining the model's capabilities through repeated training on diverse code-related tasks, allowing it to gradually become more adept at self-debugging and explanation.
The researchers found that LLMs trained with this approach were better able to identify and fix issues in their own code, as well as provide clear explanations of their reasoning. This could make them more useful for tasks like software development, where being able to understand and correct code is essential.
Technical Explanation
The researchers propose a training approach to improve LLMs' ability to self-debug and explain their code. The key elements of their approach include:
-
Feedback Loops: The LLM generates code, which is then evaluated for issues. The model receives feedback on these issues and uses that to refine its output in an iterative process. This helps the LLM learn from its mistakes and improve over time.
-
Prompts for Self-Debugging and Explanation: The researchers use prompts that encourage the LLM to engage in self-debugging and code explanation. For example, the model might be asked to "Identify any potential issues in the code you just generated and explain your reasoning." <a href="https://aimodels.fyi/papers/arxiv/teams-rl-teaching-llms-to-teach-themselves">Similar prompting techniques</a> have been used to improve LLM capabilities in other domains.
-
Iterative Training: The model is trained on a diverse set of code-related tasks, with the training gradually becoming more complex over time. This allows the LLM to progressively develop its self-debugging and explanation skills.
The researchers evaluated their approach by having the trained LLMs generate code, identify issues, and explain their reasoning. They found that the LLMs were better able to detect and fix problems in their own code, as well as provide clear and informative explanations, compared to baseline models.
Critical Analysis
The paper presents a promising approach to improving LLMs' abilities in self-debugging and code explanation, which could have significant benefits for their use in programming and software development tasks.
However, the researchers acknowledge that their approach has some limitations. For example, the training data and tasks used may not fully capture the diversity and complexity of real-world programming scenarios. <a href="https://aimodels.fyi/papers/arxiv/performance-aligned-llms-generating-fast-code">Further research</a> is needed to understand how well the trained LLMs would perform in more realistic and challenging settings.
Additionally, the paper does not explore the potential pitfalls or unintended consequences of LLMs becoming more adept at self-debugging and explanation. There may be concerns about the reliability and trustworthiness of these systems, especially if they are deployed in high-stakes applications. <a href="https://aimodels.fyi/papers/arxiv/toward-self-improvement-llms-via-imagination-searching">Ongoing work</a> on improving the transparency and reliability of LLMs will be crucial in addressing these issues.
Overall, the researchers have presented a thoughtful and well-designed approach to training LLMs to be more self-aware and capable when working with code. However, continued research and careful consideration of the implications of these advancements will be necessary to ensure they are developed and deployed responsibly.
Conclusion
This paper explores a training approach to improve large language models' (LLMs') ability to self-debug and explain their code. By incorporating feedback loops, prompts for self-debugging and explanation, and iterative training, the researchers were able to develop LLMs that were better able to identify and fix issues in their own code, as well as provide clear and informative explanations of their reasoning.
These advancements could make LLMs more reliable and useful for a variety of programming and software development tasks, where the ability to understand and correct code is essential. However, further research is needed to fully understand the limitations and potential risks of these systems, as well as how they can be developed and deployed responsibly to maximize their benefits while minimizing potential harms.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
➖
Performance-Aligned LLMs for Generating Fast Code
Daniel Nichols, Pranav Polasam, Harshitha Menon, Aniruddha Marathe, Todd Gamblin, Abhinav Bhatele
0
0
Optimizing scientific software is a difficult task because codebases are often large and complex, and performance can depend upon several factors including the algorithm, its implementation, and hardware among others. Causes of poor performance can originate from disparate sources and be difficult to diagnose. Recent years have seen a multitude of work that use large language models (LLMs) to assist in software development tasks. However, these tools are trained to model the distribution of code as text, and are not specifically designed to understand performance aspects of code. In this work, we introduce a reinforcement learning based methodology to align the outputs of code LLMs with performance. This allows us to build upon the current code modeling capabilities of LLMs and extend them to generate better performing code. We demonstrate that our fine-tuned model improves the expected speedup of generated code over base models for a set of benchmark tasks from 0.9 to 1.6 for serial code and 1.9 to 4.5 for OpenMP code.
4/30/2024
🔍
Code Repair with LLMs gives an Exploration-Exploitation Tradeoff
Hao Tang, Keya Hu, Jin Peng Zhou, Sicheng Zhong, Wei-Long Zheng, Xujie Si, Kevin Ellis
0
0
Iteratively improving and repairing source code with large language models (LLMs), known as refinement, has emerged as a popular way of generating programs that would be too complex to construct in one shot. Given a bank of test cases, together with a candidate program, an LLM can improve that program by being prompted with failed test cases. But it remains an open question how to best iteratively refine code, with prior work employing simple greedy or breadth-first strategies. We show here that refinement exposes an explore-exploit tradeoff: exploit by refining the program that passes the most test cases, or explore by refining a lesser considered program. We frame this as an arm-acquiring bandit problem, which we solve with Thompson Sampling. The resulting LLM-based program synthesis algorithm is broadly applicable: Across loop invariant synthesis, visual reasoning puzzles, and competition programming problems, we find that our new method can solve more problems using fewer language model calls.
5/31/2024
🌀
Chain of Targeted Verification Questions to Improve the Reliability of Code Generated by LLMs
Sylvain Kouemo Ngassom, Arghavan Moradi Dakhel, Florian Tambon, Foutse Khomh
0
0
LLM-based assistants, such as GitHub Copilot and ChatGPT, have the potential to generate code that fulfills a programming task described in a natural language description, referred to as a prompt. The widespread accessibility of these assistants enables users with diverse backgrounds to generate code and integrate it into software projects. However, studies show that code generated by LLMs is prone to bugs and may miss various corner cases in task specifications. Presenting such buggy code to users can impact their reliability and trust in LLM-based assistants. Moreover, significant efforts are required by the user to detect and repair any bug present in the code, especially if no test cases are available. In this study, we propose a self-refinement method aimed at improving the reliability of code generated by LLMs by minimizing the number of bugs before execution, without human intervention, and in the absence of test cases. Our approach is based on targeted Verification Questions (VQs) to identify potential bugs within the initial code. These VQs target various nodes within the Abstract Syntax Tree (AST) of the initial code, which have the potential to trigger specific types of bug patterns commonly found in LLM-generated code. Finally, our method attempts to repair these potential bugs by re-prompting the LLM with the targeted VQs and the initial code. Our evaluation, based on programming tasks in the CoderEval dataset, demonstrates that our proposed method outperforms state-of-the-art methods by decreasing the number of targeted errors in the code between 21% to 62% and improving the number of executable code instances to 13%.
5/24/2024
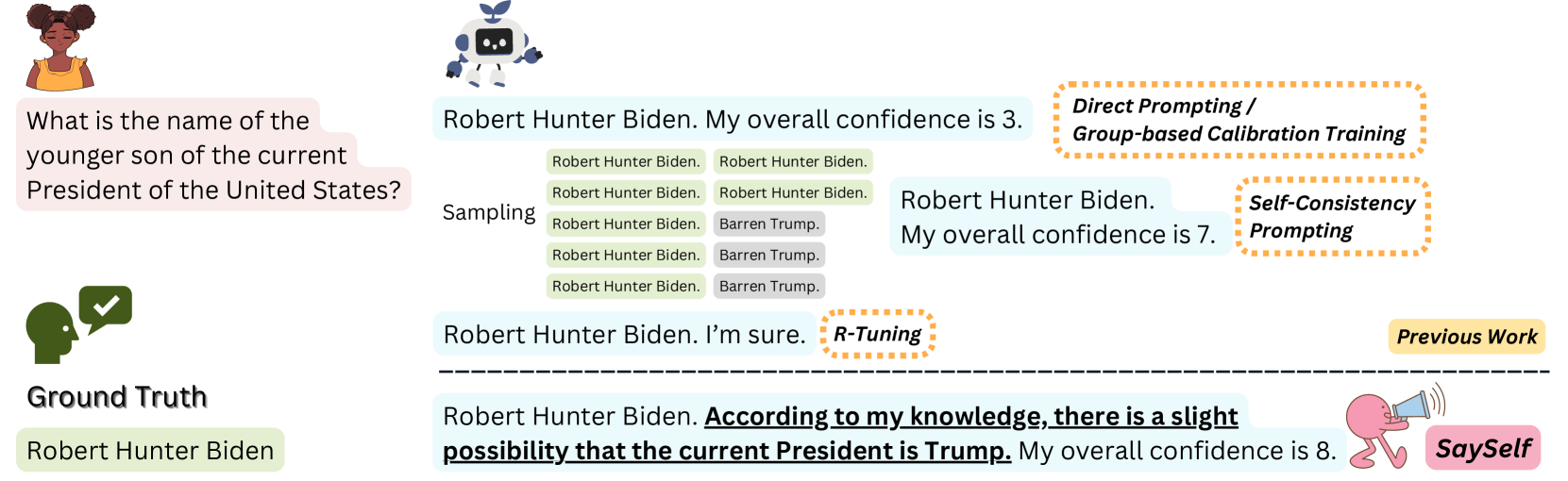
SaySelf: Teaching LLMs to Express Confidence with Self-Reflective Rationales
Tianyang Xu, Shujin Wu, Shizhe Diao, Xiaoze Liu, Xingyao Wang, Yangyi Chen, Jing Gao
0
0
Large language models (LLMs) often generate inaccurate or fabricated information and generally fail to indicate their confidence, which limits their broader applications. Previous work elicits confidence from LLMs by direct or self-consistency prompting, or constructing specific datasets for supervised finetuning. The prompting-based approaches have inferior performance, and the training-based approaches are limited to binary or inaccurate group-level confidence estimates. In this work, we present the advanced SaySelf, a training framework that teaches LLMs to express more accurate fine-grained confidence estimates. In addition, beyond the confidence scores, SaySelf initiates the process of directing LLMs to produce self-reflective rationales that clearly identify gaps in their parametric knowledge and explain their uncertainty. This is achieved by using an LLM to automatically summarize the uncertainties in specific knowledge via natural language. The summarization is based on the analysis of the inconsistency in multiple sampled reasoning chains, and the resulting data is utilized for supervised fine-tuning. Moreover, we utilize reinforcement learning with a meticulously crafted reward function to calibrate the confidence estimates, motivating LLMs to deliver accurate, high-confidence predictions and to penalize overconfidence in erroneous outputs. Experimental results in both in-distribution and out-of-distribution datasets demonstrate the effectiveness of SaySelf in reducing the confidence calibration error and maintaining the task performance. We show that the generated self-reflective rationales are reasonable and can further contribute to the calibration. The code is made public at https://github.com/xu1868/SaySelf.
6/6/2024