Toward Self-Improvement of LLMs via Imagination, Searching, and Criticizing
2404.12253
3
73
Abstract
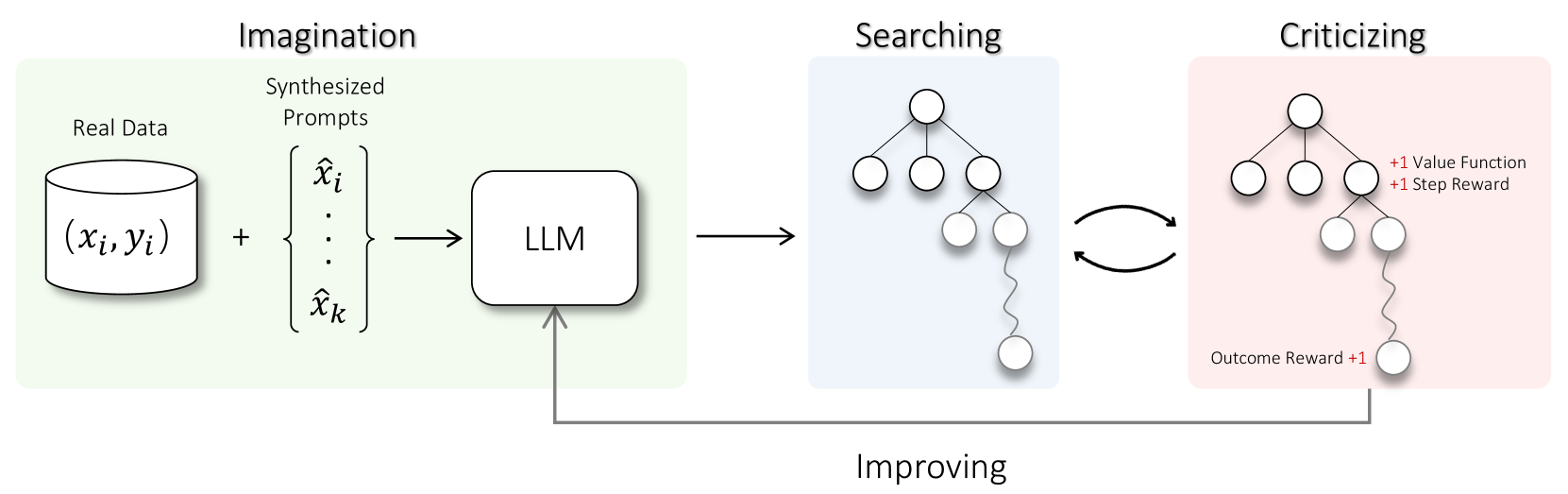
Despite the impressive capabilities of Large Language Models (LLMs) on various tasks, they still struggle with scenarios that involves complex reasoning and planning. Recent work proposed advanced prompting techniques and the necessity of fine-tuning with high-quality data to augment LLMs' reasoning abilities. However, these approaches are inherently constrained by data availability and quality. In light of this, self-correction and self-learning emerge as viable solutions, employing strategies that allow LLMs to refine their outputs and learn from self-assessed rewards. Yet, the efficacy of LLMs in self-refining its response, particularly in complex reasoning and planning task, remains dubious. In this paper, we introduce AlphaLLM for the self-improvements of LLMs, which integrates Monte Carlo Tree Search (MCTS) with LLMs to establish a self-improving loop, thereby enhancing the capabilities of LLMs without additional annotations. Drawing inspiration from the success of AlphaGo, AlphaLLM addresses the unique challenges of combining MCTS with LLM for self-improvement, including data scarcity, the vastness search spaces of language tasks, and the subjective nature of feedback in language tasks. AlphaLLM is comprised of prompt synthesis component, an efficient MCTS approach tailored for language tasks, and a trio of critic models for precise feedback. Our experimental results in mathematical reasoning tasks demonstrate that AlphaLLM significantly enhances the performance of LLMs without additional annotations, showing the potential for self-improvement in LLMs.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper proposes a framework for enabling large language models (LLMs) to self-improve through a process of imagination, searching, and criticizing.
- The authors argue that current LLMs are limited in their ability to refine and improve themselves, and they present a novel approach to address this challenge.
- The key components of the proposed framework include an "imagination" module that generates new ideas, a "searching" module that explores these ideas, and a "criticizing" module that evaluates the quality of the generated content.
Plain English Explanation
The paper discusses a way to help large language models (LLMs) get better at improving themselves. Currently, LLMs have a hard time refining and improving their own abilities, which limits their growth and capabilities.
The researchers suggest a new approach that involves three main steps:
- Imagination: The LLM generates new ideas and content on its own, without being prompted by a user.
- Searching: The LLM explores and investigates these self-generated ideas, looking for ways to improve them.
- Criticizing: The LLM evaluates the quality of its self-generated content, identifying strengths and weaknesses.
By going through this cycle of imagination, searching, and criticizing, the LLM can gradually learn to refine and enhance its own capabilities, becoming more self-improving over time. This could help address the challenges faced by self-incorrect LLMs that struggle to improve themselves.
The authors believe this approach could be a significant step forward in developing more capable and self-aware AI systems that can assist researchers and potentially lead to transformative breakthroughs in AI.
Technical Explanation
The paper proposes a framework for enabling large language models (LLMs) to self-improve through a process of imagination, searching, and criticizing. The key components of this framework include:
-
Imagination Module: This module generates new ideas, content, or tasks for the LLM to explore, without being prompted by a human user. This allows the LLM to generate novel content on its own.
-
Searching Module: This module takes the self-generated ideas from the imagination module and explores them in depth, looking for ways to improve or refine the content.
-
Criticizing Module: This module evaluates the quality and potential of the self-generated content, identifying both strengths and weaknesses. The criticizing module provides feedback to guide the LLM's future self-improvement efforts.
By cycling through these three steps, the LLM can gradually learn to refine and enhance its own capabilities, becoming more self-improving over time. The authors argue that this approach can help address the challenges faced by self-incorrect LLMs that struggle to improve themselves.
The authors test their framework through a series of experiments, demonstrating its ability to enable LLMs to generate novel content, search for improvements, and critically evaluate their own work. The results suggest that this approach could be a significant step forward in developing more capable and self-aware AI systems that can assist researchers and potentially lead to transformative breakthroughs in AI.
Critical Analysis
The paper presents a promising framework for enabling LLMs to become more self-improving, but it also acknowledges several limitations and areas for further research:
-
Scalability: The authors note that the computational and memory requirements of the proposed framework may be challenging to scale to larger, more complex LLMs. Addressing this scalability issue will be crucial for the practical deployment of the framework.
-
Robustness: The paper does not fully address the potential risks and challenges associated with LLMs generating and evaluating their own content, which could lead to self-reinforcing biases or unintended consequences. Ensuring the robustness and safety of the self-improvement process will be a critical area for future research.
-
Alignment with Human Values: The paper does not discuss how the self-improvement process can be aligned with human values and ethical principles. Developing mechanisms to ensure the self-improvement of LLMs is consistent with societal well-being will be an important consideration.
-
Evaluation Metrics: The paper relies on qualitative assessments of the self-generated content, but more rigorous and quantitative evaluation metrics may be needed to fully assess the efficacy of the proposed framework.
Overall, the paper presents an innovative approach to enabling LLMs to become more self-improving, but further research is needed to address the scalability, robustness, and alignment challenges associated with this framework.
Conclusion
This paper proposes a novel framework for enabling large language models (LLMs) to self-improve through a process of imagination, searching, and criticizing. By cycling through these three steps, the LLM can gradually learn to refine and enhance its own capabilities, becoming more self-improving over time.
The authors demonstrate the potential of this approach through a series of experiments, suggesting that it could be a significant step forward in developing more capable and self-aware AI systems. However, the paper also acknowledges several limitations and areas for further research, such as scalability, robustness, and alignment with human values.
Overall, the ideas presented in this paper represent an important and promising direction for the field of AI, as researchers continue to explore ways to create self-improving systems that can assist researchers and potentially lead to transformative breakthroughs in the future.
Related Papers
AlphaMath Almost Zero: process Supervision without process
Guoxin Chen, Minpeng Liao, Chengxi Li, Kai Fan
0
0
Recent advancements in large language models (LLMs) have substantially enhanced their mathematical reasoning abilities. However, these models still struggle with complex problems that require multiple reasoning steps, frequently leading to logical or numerical errors. While numerical mistakes can largely be addressed by integrating a code interpreter, identifying logical errors within intermediate steps is more challenging. Moreover, manually annotating these steps for training is not only expensive but also demands specialized expertise. In this study, we introduce an innovative approach that eliminates the need for manual annotation by leveraging the Monte Carlo Tree Search (MCTS) framework to generate both the process supervision and evaluation signals automatically. Essentially, when a LLM is well pre-trained, only the mathematical questions and their final answers are required to generate our training data, without requiring the solutions. We proceed to train a step-level value model designed to improve the LLM's inference process in mathematical domains. Our experiments indicate that using automatically generated solutions by LLMs enhanced with MCTS significantly improves the model's proficiency in dealing with intricate mathematical reasoning tasks.
5/7/2024
💬
Small Language Models Need Strong Verifiers to Self-Correct Reasoning
Yunxiang Zhang, Muhammad Khalifa, Lajanugen Logeswaran, Jaekyeom Kim, Moontae Lee, Honglak Lee, Lu Wang
0
0
Self-correction has emerged as a promising solution to boost the reasoning performance of large language models (LLMs), where LLMs refine their solutions using self-generated critiques that pinpoint the errors. This work explores whether smaller-size (<= 13B) language models (LMs) have the ability of self-correction on reasoning tasks with minimal inputs from stronger LMs. We propose a novel pipeline that prompts smaller LMs to collect self-correction data that supports the training of self-refinement abilities. First, we leverage correct solutions to guide the model in critiquing their incorrect responses. Second, the generated critiques, after filtering, are used for supervised fine-tuning of the self-correcting reasoner through solution refinement. Our experimental results show improved self-correction abilities of two models on five datasets spanning math and commonsense reasoning, with notable performance gains when paired with a strong GPT-4-based verifier, though limitations are identified when using a weak self-verifier for determining when to correct.
4/29/2024
Enhancing the General Agent Capabilities of Low-Parameter LLMs through Tuning and Multi-Branch Reasoning
Qinhao Zhou, Zihan Zhang, Xiang Xiang, Ke Wang, Yuchuan Wu, Yongbin Li
0
0
Open-source pre-trained Large Language Models (LLMs) exhibit strong language understanding and generation capabilities, making them highly successful in a variety of tasks. However, when used as agents for dealing with complex problems in the real world, their performance is far inferior to large commercial models such as ChatGPT and GPT-4. As intelligent agents, LLMs need to have the capabilities of task planning, long-term memory, and the ability to leverage external tools to achieve satisfactory performance. Various methods have been proposed to enhance the agent capabilities of LLMs. On the one hand, methods involve constructing agent-specific data and fine-tuning the models. On the other hand, some methods focus on designing prompts that effectively activate the reasoning abilities of the LLMs. We explore both strategies on the 7B and 13B models. We propose a comprehensive method for constructing agent-specific data using GPT-4. Through supervised fine-tuning with constructed data, we find that for these models with a relatively small number of parameters, supervised fine-tuning can significantly reduce hallucination outputs and formatting errors in agent tasks. Furthermore, techniques such as multi-path reasoning and task decomposition can effectively decrease problem complexity and enhance the performance of LLMs as agents. We evaluate our method on five agent tasks of AgentBench and achieve satisfactory results.
4/1/2024
💬
Mind's Mirror: Distilling Self-Evaluation Capability and Comprehensive Thinking from Large Language Models
Weize Liu, Guocong Li, Kai Zhang, Bang Du, Qiyuan Chen, Xuming Hu, Hongxia Xu, Jintai Chen, Jian Wu
0
0
Large language models (LLMs) have achieved remarkable advancements in natural language processing. However, the massive scale and computational demands of these models present formidable challenges when considering their practical deployment in resource-constrained environments. While techniques such as chain-of-thought (CoT) distillation have displayed promise in distilling LLMs into small language models (SLMs), there is a risk that distilled SLMs may still inherit flawed reasoning and hallucinations from LLMs. To address these issues, we propose a twofold methodology: First, we introduce a novel method for distilling the self-evaluation capability from LLMs into SLMs, aiming to mitigate the adverse effects of flawed reasoning and hallucinations inherited from LLMs. Second, we advocate for distilling more comprehensive thinking by incorporating multiple distinct CoTs and self-evaluation outputs, to ensure a more thorough and robust knowledge transfer into SLMs. Experiments on three NLP benchmarks demonstrate that our method significantly improves the performance of distilled SLMs, offering a new perspective for developing more effective and efficient SLMs in resource-constrained environments.
4/9/2024