CodeJudge-Eval: Can Large Language Models be Good Judges in Code Understanding?

0
💬
Sign in to get full access
Overview
- Powerful large language models (LLMs) have demonstrated impressive code generation capabilities.
- However, the ability to generate correct code does not necessarily imply that a model can accurately judge other codes for the same problem.
- The paper investigates the motivation behind the code judging task, which is an important aspect of evaluating LLM capabilities.
Plain English Explanation
The paper explores the idea that a model's ability to generate correct code does not automatically mean it can accurately evaluate and judge other code written for the same problem. Large language models (LLMs) like GPT-4, Gemini, and Claude have shown impressive skills in generating code. However, the researchers wanted to investigate whether these models can also reliably assess and judge the quality of code written by others. The paper dives into the motivation behind the "code judging" task, which is an important way to evaluate the overall capabilities of these powerful language models.
Technical Explanation
The paper investigates the motivation behind the code judging task, which is an essential aspect of evaluating the capabilities of large language models (LLMs) in software development. The researchers observed that a model's ability to generate correct code does not necessarily imply that it can accurately judge other codes for the same problem. This is an important distinction, as the capacity to generate code and the ability to assess code quality are distinct skills.
The paper explores the importance of the code judging task in assessing the overall capabilities of LLMs, particularly in the context of software development. Evaluating the code judging ability of these models provides insights into their understanding of programming concepts, their ability to assess code complexity, and their potential to assist in tasks such as code review and refactoring.
Critical Analysis
The paper highlights a critical limitation in the current evaluation of LLM capabilities, which is the assumption that a model's ability to generate correct code automatically implies its capacity to accurately judge other codes. The researchers rightly point out that these two skills are distinct and should be evaluated separately.
While the paper does not provide a comprehensive solution to this issue, it raises important questions about the need for more holistic and contamination-free evaluations of LLM capabilities in the context of software development. Further research may be needed to develop robust benchmarks and methodologies that can accurately assess both code generation and code judging abilities.
Conclusion
This paper sheds light on the motivation behind the code judging task, which is an essential component in evaluating the overall capabilities of large language models (LLMs) in software development. The key insight is that a model's ability to generate correct code does not necessarily imply its capacity to accurately judge other codes for the same problem. This distinction highlights the need for more comprehensive and contamination-free evaluations of LLM capabilities, which can provide valuable insights into their potential to assist in various software engineering tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
CodeJudge-Eval: Can Large Language Models be Good Judges in Code Understanding?
Yuwei Zhao, Ziyang Luo, Yuchen Tian, Hongzhan Lin, Weixiang Yan, Annan Li, Jing Ma
Recent advancements in large language models (LLMs) have showcased impressive code generation capabilities, primarily evaluated through language-to-code benchmarks. However, these benchmarks may not fully capture a model's code understanding abilities. We introduce CodeJudge-Eval (CJ-Eval), a novel benchmark designed to assess LLMs' code understanding abilities from the perspective of code judging rather than code generation. CJ-Eval challenges models to determine the correctness of provided code solutions, encompassing various error types and compilation issues. By leveraging a diverse set of problems and a fine-grained judging system, CJ-Eval addresses the limitations of traditional benchmarks, including the potential memorization of solutions. Evaluation of 12 well-known LLMs on CJ-Eval reveals that even state-of-the-art models struggle, highlighting the benchmark's ability to probe deeper into models' code understanding abilities. Our codes and benchmark are available at url{https://github.com/CodeLLM-Research/CodeJudge-Eval}.
Read more9/16/2024
🤷
33
Replacing Judges with Juries: Evaluating LLM Generations with a Panel of Diverse Models
Pat Verga, Sebastian Hofstatter, Sophia Althammer, Yixuan Su, Aleksandra Piktus, Arkady Arkhangorodsky, Minjie Xu, Naomi White, Patrick Lewis
As Large Language Models (LLMs) have become more advanced, they have outpaced our abilities to accurately evaluate their quality. Not only is finding data to adequately probe particular model properties difficult, but evaluating the correctness of a model's freeform generation alone is a challenge. To address this, many evaluations now rely on using LLMs themselves as judges to score the quality of outputs from other LLMs. Evaluations most commonly use a single large model like GPT4. While this method has grown in popularity, it is costly, has been shown to introduce intramodel bias, and in this work, we find that very large models are often unnecessary. We propose instead to evaluate models using a Panel of LLm evaluators (PoLL). Across three distinct judge settings and spanning six different datasets, we find that using a PoLL composed of a larger number of smaller models outperforms a single large judge, exhibits less intra-model bias due to its composition of disjoint model families, and does so while being over seven times less expensive.
Read more5/2/2024

0
Judging the Judges: Evaluating Alignment and Vulnerabilities in LLMs-as-Judges
Aman Singh Thakur, Kartik Choudhary, Venkat Srinik Ramayapally, Sankaran Vaidyanathan, Dieuwke Hupkes
Offering a promising solution to the scalability challenges associated with human evaluation, the LLM-as-a-judge paradigm is rapidly gaining traction as an approach to evaluating large language models (LLMs). However, there are still many open questions about the strengths and weaknesses of this paradigm, and what potential biases it may hold. In this paper, we present a comprehensive study of the performance of various LLMs acting as judges. We leverage TriviaQA as a benchmark for assessing objective knowledge reasoning of LLMs and evaluate them alongside human annotations which we found to have a high inter-annotator agreement. Our study includes 9 judge models and 9 exam taker models -- both base and instruction-tuned. We assess the judge model's alignment across different model sizes, families, and judge prompts. Among other results, our research rediscovers the importance of using Cohen's kappa as a metric of alignment as opposed to simple percent agreement, showing that judges with high percent agreement can still assign vastly different scores. We find that both Llama-3 70B and GPT-4 Turbo have an excellent alignment with humans, but in terms of ranking exam taker models, they are outperformed by both JudgeLM-7B and the lexical judge Contains, which have up to 34 points lower human alignment. Through error analysis and various other studies, including the effects of instruction length and leniency bias, we hope to provide valuable lessons for using LLMs as judges in the future.
Read more6/19/2024
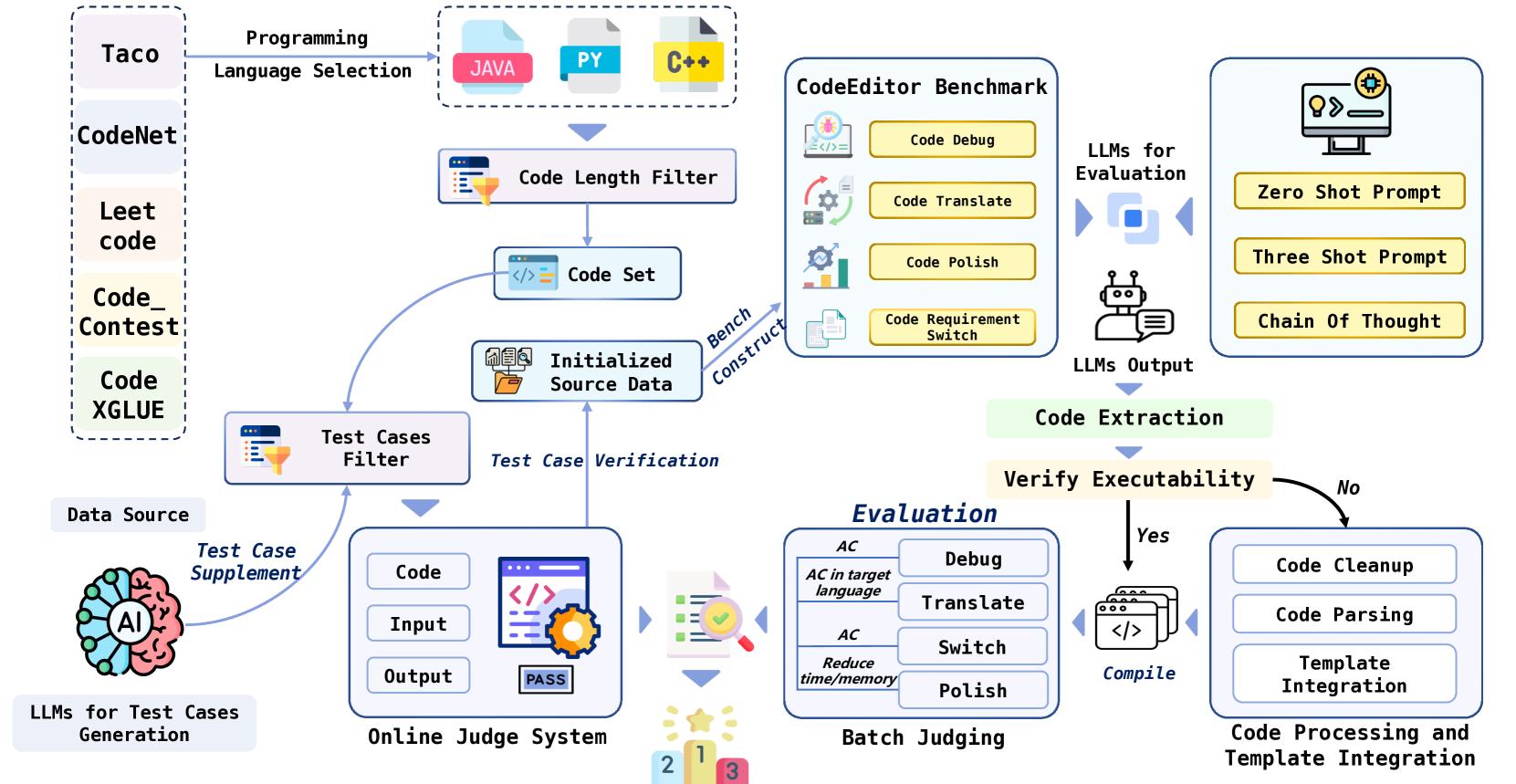
0
CodeEditorBench: Evaluating Code Editing Capability of Large Language Models
Jiawei Guo, Ziming Li, Xueling Liu, Kaijing Ma, Tianyu Zheng, Zhouliang Yu, Ding Pan, Yizhi LI, Ruibo Liu, Yue Wang, Shuyue Guo, Xingwei Qu, Xiang Yue, Ge Zhang, Wenhu Chen, Jie Fu
Large Language Models (LLMs) for code are rapidly evolving, with code editing emerging as a critical capability. We introduce CodeEditorBench, an evaluation framework designed to rigorously assess the performance of LLMs in code editing tasks, including debugging, translating, polishing, and requirement switching. Unlike existing benchmarks focusing solely on code generation, CodeEditorBench emphasizes real-world scenarios and practical aspects of software development. We curate diverse coding challenges and scenarios from five sources, covering various programming languages, complexity levels, and editing tasks. Evaluation of 19 LLMs reveals that closed-source models (particularly Gemini-Ultra and GPT-4), outperform open-source models in CodeEditorBench, highlighting differences in model performance based on problem types and prompt sensitivities. CodeEditorBench aims to catalyze advancements in LLMs by providing a robust platform for assessing code editing capabilities. We will release all prompts and datasets to enable the community to expand the dataset and benchmark emerging LLMs. By introducing CodeEditorBench, we contribute to the advancement of LLMs in code editing and provide a valuable resource for researchers and practitioners.
Read more4/9/2024