CodeEditorBench: Evaluating Code Editing Capability of Large Language Models
2404.03543
0
0
Abstract
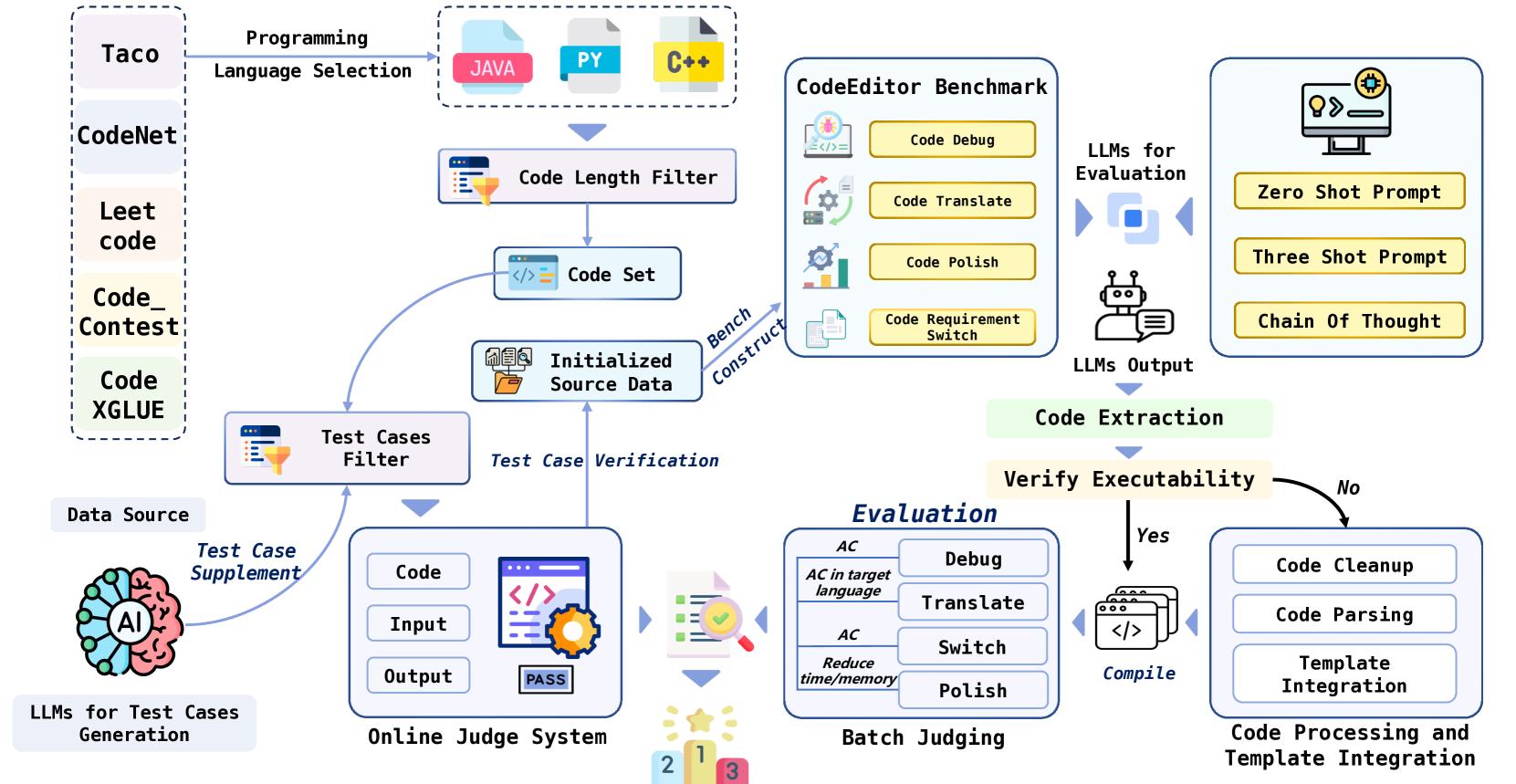
Large Language Models (LLMs) for code are rapidly evolving, with code editing emerging as a critical capability. We introduce CodeEditorBench, an evaluation framework designed to rigorously assess the performance of LLMs in code editing tasks, including debugging, translating, polishing, and requirement switching. Unlike existing benchmarks focusing solely on code generation, CodeEditorBench emphasizes real-world scenarios and practical aspects of software development. We curate diverse coding challenges and scenarios from five sources, covering various programming languages, complexity levels, and editing tasks. Evaluation of 19 LLMs reveals that closed-source models (particularly Gemini-Ultra and GPT-4), outperform open-source models in CodeEditorBench, highlighting differences in model performance based on problem types and prompt sensitivities. CodeEditorBench aims to catalyze advancements in LLMs by providing a robust platform for assessing code editing capabilities. We will release all prompts and datasets to enable the community to expand the dataset and benchmark emerging LLMs. By introducing CodeEditorBench, we contribute to the advancement of LLMs in code editing and provide a valuable resource for researchers and practitioners.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces CodeEditorBench, a benchmark for evaluating the code editing capabilities of large language models (LLMs).
- The benchmark consists of a dataset of coding tasks and a suite of metrics to assess an LLM's ability to understand, modify, and generate code.
- The authors evaluate several state-of-the-art LLMs on CodeEditorBench and provide insights into their strengths and limitations in code editing.
Plain English Explanation
The paper presents a new way to test the coding abilities of powerful AI language models. These models, called large language models (LLMs), have shown impressive performance on a variety of language tasks. However, their ability to actually write and edit code has not been well-studied.
To address this, the researchers created CodeEditorBench, a benchmark that includes a set of coding tasks and metrics to evaluate how well LLMs can understand, modify, and generate code. They then tested several state-of-the-art LLMs on this benchmark to see how they performed.
The goal is to better understand the strengths and limitations of these powerful language models when it comes to the important real-world task of coding. This could help guide the development of LLMs that are more capable of assisting humans with programming and software development.
Technical Explanation
The paper introduces CodeEditorBench, a new benchmark for evaluating the code editing capabilities of large language models (LLMs). The benchmark consists of a dataset of coding tasks, including code understanding, code modification, and code generation.
To assess an LLM's performance, the authors define several metrics, such as:
- Code Understanding: Measuring how well the model can comprehend the meaning and intent of existing code.
- Code Modification: Evaluating the model's ability to make targeted changes to code to implement new functionalities.
- Code Generation: Assessing the model's capacity to generate new, working code from scratch.
The authors then evaluate the performance of several state-of-the-art LLMs, including GPT-3, InstructGPT, and ChatGPT, on the CodeEditorBench tasks. The results provide insights into the strengths and limitations of these models in the context of code editing, which can inform future research and development of LLMs for programming and software development tasks.
Critical Analysis
The paper presents a comprehensive and well-designed benchmark for evaluating the code editing capabilities of LLMs. The authors have thoughtfully constructed a dataset of coding tasks and defined relevant metrics to assess key aspects of code understanding, modification, and generation.
However, the authors acknowledge several limitations of their study. For instance, the benchmark focuses on a limited set of programming languages and task types, which may not fully capture the diverse requirements of real-world software development. Additionally, the authors note that the performance of LLMs on the benchmark may not directly translate to their effectiveness in assisting human programmers in a collaborative setting.
Furthermore, the paper does not delve deeply into the underlying reasons for the observed strengths and weaknesses of the evaluated LLMs. A more detailed analysis of the models' architectures, training data, and learning capabilities could provide valuable insights to guide future improvements in this area.
Nevertheless, the CodeEditorBench represents an important step towards a more comprehensive understanding of LLMs' abilities in the realm of code editing, which is a crucial skill for many real-world applications. The authors' work lays the groundwork for further research and development in this emerging field.
Conclusion
The paper introduces CodeEditorBench, a benchmark for evaluating the code editing capabilities of large language models (LLMs). The authors demonstrate the use of this benchmark by assessing the performance of several state-of-the-art LLMs, providing valuable insights into the strengths and limitations of these models in understanding, modifying, and generating code.
The findings from this study can inform the ongoing development of LLMs for programming and software engineering tasks, ultimately leading to more capable and collaborative AI assistants for human developers. While the benchmark has some limitations, it represents a significant step forward in the quest to harness the power of advanced language models for real-world coding applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
The RealHumanEval: Evaluating Large Language Models' Abilities to Support Programmers
Hussein Mozannar, Valerie Chen, Mohammed Alsobay, Subhro Das, Sebastian Zhao, Dennis Wei, Manish Nagireddy, Prasanna Sattigeri, Ameet Talwalkar, David Sontag
0
0
Evaluation of large language models (LLMs) for code has primarily relied on static benchmarks, including HumanEval (Chen et al., 2021), which measure the ability of LLMs to generate complete code that passes unit tests. As LLMs are increasingly used as programmer assistants, we study whether gains on existing benchmarks translate to gains in programmer productivity when coding with LLMs, including time spent coding. In addition to static benchmarks, we investigate the utility of preference metrics that might be used as proxies to measure LLM helpfulness, such as code acceptance or copy rates. To do so, we introduce RealHumanEval, a web interface to measure the ability of LLMs to assist programmers, through either autocomplete or chat support. We conducted a user study (N=213) using RealHumanEval in which users interacted with six LLMs of varying base model performance. Despite static benchmarks not incorporating humans-in-the-loop, we find that improvements in benchmark performance lead to increased programmer productivity; however gaps in benchmark versus human performance are not proportional -- a trend that holds across both forms of LLM support. In contrast, we find that programmer preferences do not correlate with their actual performance, motivating the need for better, human-centric proxy signals. We also open-source RealHumanEval to enable human-centric evaluation of new models and the study data to facilitate efforts to improve code models.
4/4/2024

InfiCoder-Eval: Systematically Evaluating the Question-Answering Capabilities of Code Large Language Models
Linyi Li, Shijie Geng, Zhenwen Li, Yibo He, Hao Yu, Ziyue Hua, Guanghan Ning, Siwei Wang, Tao Xie, Hongxia Yang
0
0
Large Language Models for understanding and generating code (code LLMs) have witnessed tremendous progress in recent years. With the rapid development of code LLMs, many popular evaluation benchmarks, such as HumanEval, DS-1000, and MBPP, have emerged to measure the performance of code LLMs with a particular focus on code generation tasks. However, they are insufficient to cover the full range of expected capabilities of code LLMs, which span beyond code generation to answering diverse coding-related questions. To fill this gap, we propose InfiCoder-Eval, a large-scale freeform question-answering (QA) benchmark for code, comprising 234 carefully selected high-quality Stack Overflow questions that span across 15 programming languages. To evaluate the response correctness, InfiCoder-Eval supports four types of model-free metrics and domain experts carefully choose and concretize the criterion for each question. We conduct a systematic evaluation for more than 80 code LLMs on InfiCoder-Eval, leading to a series of insightful findings. Furthermore, our detailed analyses showcase possible directions for further improvement of code LLMs. InfiCoder-Eval is fully open source at https://infi-coder.github.io/inficoder-eval/ and continuously maintaining and expanding to foster more scientific and systematic practices for evaluating code LLMs.
4/12/2024
💬
Can We Edit Multimodal Large Language Models?
Siyuan Cheng, Bozhong Tian, Qingbin Liu, Xi Chen, Yongheng Wang, Huajun Chen, Ningyu Zhang
0
0
In this paper, we focus on editing Multimodal Large Language Models (MLLMs). Compared to editing single-modal LLMs, multimodal model editing is more challenging, which demands a higher level of scrutiny and careful consideration in the editing process. To facilitate research in this area, we construct a new benchmark, dubbed MMEdit, for editing multimodal LLMs and establishing a suite of innovative metrics for evaluation. We conduct comprehensive experiments involving various model editing baselines and analyze the impact of editing different components for multimodal LLMs. Empirically, we notice that previous baselines can implement editing multimodal LLMs to some extent, but the effect is still barely satisfactory, indicating the potential difficulty of this task. We hope that our work can provide the NLP community with insights. Code and dataset are available in https://github.com/zjunlp/EasyEdit.
4/19/2024
🔮
Learning Performance-Improving Code Edits
Alexander Shypula, Aman Madaan, Yimeng Zeng, Uri Alon, Jacob Gardner, Milad Hashemi, Graham Neubig, Parthasarathy Ranganathan, Osbert Bastani, Amir Yazdanbakhsh
0
0
With the decline of Moore's law, optimizing program performance has become a major focus of software research. However, high-level optimizations such as API and algorithm changes remain elusive due to the difficulty of understanding the semantics of code. Simultaneously, pretrained large language models (LLMs) have demonstrated strong capabilities at solving a wide range of programming tasks. To that end, we introduce a framework for adapting LLMs to high-level program optimization. First, we curate a dataset of performance-improving edits made by human programmers of over 77,000 competitive C++ programming submission pairs, accompanied by extensive unit tests. A major challenge is the significant variability of measuring performance on commodity hardware, which can lead to spurious improvements. To isolate and reliably evaluate the impact of program optimizations, we design an environment based on the gem5 full system simulator, the de facto simulator used in academia and industry. Next, we propose a broad range of adaptation strategies for code optimization; for prompting, these include retrieval-based few-shot prompting and chain-of-thought, and for finetuning, these include performance-conditioned generation and synthetic data augmentation based on self-play. A combination of these techniques achieves a mean speedup of 6.86 with eight generations, higher than average optimizations from individual programmers (3.66). Using our model's fastest generations, we set a new upper limit on the fastest speedup possible for our dataset at 9.64 compared to using the fastest human submissions available (9.56).
4/29/2024