CodeMind: A Framework to Challenge Large Language Models for Code Reasoning
2402.09664
0
0
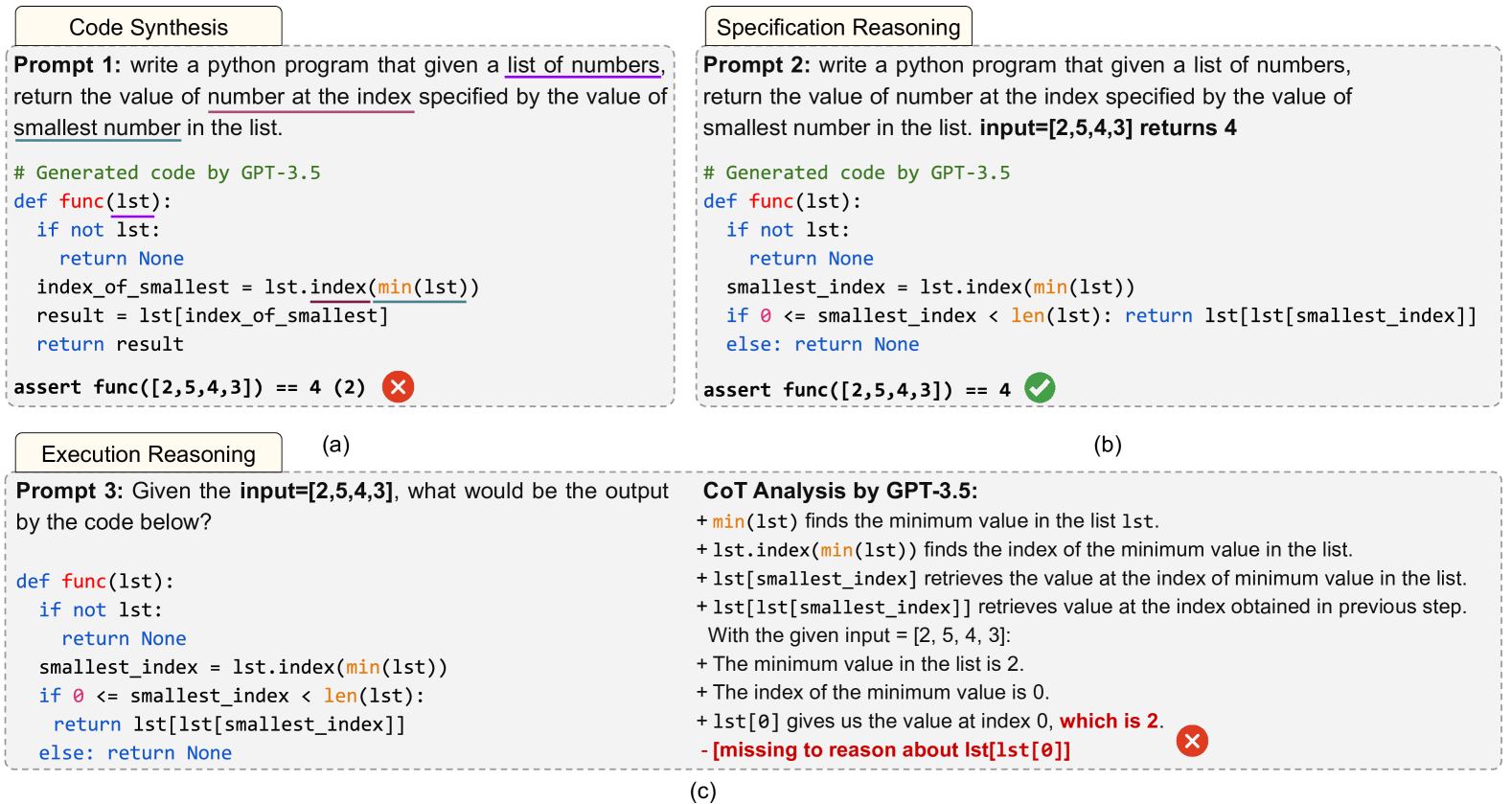
Abstract
Solely relying on test passing to evaluate Large Language Models (LLMs) for code synthesis may result in unfair assessment or promoting models with data leakage. As an alternative, we introduce CodeMind, a framework designed to gauge the code reasoning abilities of LLMs. CodeMind currently supports three code reasoning tasks: Independent Execution Reasoning (IER), Dependent Execution Reasoning (DER), and Specification Reasoning (SR). The first two evaluate models to predict the execution output of an arbitrary code or code the model could correctly synthesize. The third one evaluates the extent to which LLMs implement the specified expected behavior. Our extensive evaluation of nine LLMs across five benchmarks in two different programming languages using CodeMind shows that LLMs fairly follow control flow constructs and, in general, explain how inputs evolve to output, specifically for simple programs and the ones they can correctly synthesize. However, their performance drops for code with higher complexity, non-trivial logical and arithmetic operators, non-primitive types, and API calls. Furthermore, we observe that, while correlated, specification reasoning (essential for code synthesis) does not imply execution reasoning (essential for broader programming tasks such as testing and debugging): ranking LLMs based on test passing can be different compared to code reasoning.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- CodeMind is a framework designed to challenge large language models (LLMs) on their code reasoning capabilities.
- It includes a diverse set of programming tasks that test different aspects of code understanding and generation.
- The framework aims to provide a comprehensive evaluation of LLMs' performance on code-related tasks.
Plain English Explanation
CodeMind is a new tool that helps researchers and developers understand how well large language models (LLMs) can work with code. LLMs are powerful AI systems that can generate human-like text, but it's not always clear how well they can understand and reason about programming code.
CodeMind contains a variety of programming tasks that are designed to test different aspects of an LLM's code skills. For example, some tasks might ask the model to explain the purpose of a piece of code, while others might ask it to generate new code to solve a problem. By having LLMs complete these diverse tasks, researchers can get a more comprehensive understanding of their code-related capabilities.
The goal of CodeMind is to provide a standardized way to evaluate and compare the performance of different LLMs on code-related tasks. This can help researchers and developers choose the right LLM for their specific needs, whether that's building AI-powered coding assistants, generating code automatically, or other applications.
Technical Explanation
The core of CodeMind is a diverse set of programming tasks that cover various aspects of code reasoning, including code understanding, generation, and analysis. The tasks are designed to challenge LLMs in areas such as:
- Explaining the purpose and functionality of code snippets
- Generating code to solve programming problems
- Identifying and fixing bugs in code
- Recognizing and using appropriate programming concepts and constructs
To evaluate LLM performance, the authors propose several metrics, such as accuracy, fluency, and contextual relevance. These metrics are applied to the model's outputs on the CodeMind tasks, allowing for a comprehensive assessment of the LLM's code reasoning capabilities.
The paper also presents an initial evaluation of several prominent LLMs, including GPT-3 and CodeT5, on the CodeMind tasks. The results highlight the strengths and weaknesses of these models, providing insights into their current capabilities and limitations in code-related reasoning.
Critical Analysis
The CodeMind framework represents a valuable contribution to the field of AI-driven code reasoning. By providing a standardized set of tasks and evaluation metrics, it enables a more rigorous and comprehensive assessment of LLM performance on code-related problems.
However, the authors acknowledge that CodeMind is not a complete solution and that there are still many challenges to be addressed. For example, the current tasks may not fully capture the nuances and complexities of real-world programming, and the evaluation metrics may not always align with the needs of specific applications.
Additionally, the authors note that the performance of LLMs on CodeMind tasks may be influenced by factors such as the models' training data, architecture, and fine-tuning approaches. Further research is needed to understand the interplay between these factors and the models' code reasoning abilities.
Conclusion
CodeMind is a promising framework that can help advance the state of the art in AI-driven code reasoning. By providing a standardized benchmark for evaluating LLM performance on a diverse set of programming tasks, it can support the development of more capable and reliable AI systems for various code-related applications.
As the field of AI and programming continues to evolve, tools like CodeMind will become increasingly valuable in ensuring that large language models can effectively understand, reason about, and generate code to support the growing needs of software development and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Language Models as Compilers: Simulating Pseudocode Execution Improves Algorithmic Reasoning in Language Models
Hyungjoo Chae, Yeonghyeon Kim, Seungone Kim, Kai Tzu-iunn Ong, Beong-woo Kwak, Moohyeon Kim, Seonghwan Kim, Taeyoon Kwon, Jiwan Chung, Youngjae Yu, Jinyoung Yeo
0
0
Algorithmic reasoning refers to the ability to understand the complex patterns behind the problem and decompose them into a sequence of reasoning steps towards the solution. Such nature of algorithmic reasoning makes it a challenge for large language models (LLMs), even though they have demonstrated promising performance in other reasoning tasks. Within this context, some recent studies use programming languages (e.g., Python) to express the necessary logic for solving a given instance/question (e.g., Program-of-Thought) as inspired by their strict and precise syntaxes. However, it is non-trivial to write an executable code that expresses the correct logic on the fly within a single inference call. Also, the code generated specifically for an instance cannot be reused for others, even if they are from the same task and might require identical logic to solve. This paper presents Think-and-Execute, a novel framework that decomposes the reasoning process of language models into two steps. (1) In Think, we discover a task-level logic that is shared across all instances for solving a given task and then express the logic with pseudocode; (2) In Execute, we further tailor the generated pseudocode to each instance and simulate the execution of the code. With extensive experiments on seven algorithmic reasoning tasks, we demonstrate the effectiveness of Think-and-Execute. Our approach better improves LMs' reasoning compared to several strong baselines performing instance-specific reasoning (e.g., CoT and PoT), suggesting the helpfulness of discovering task-level logic. Also, we show that compared to natural language, pseudocode can better guide the reasoning of LMs, even though they are trained to follow natural language instructions.
4/4/2024

Beyond Accuracy: Evaluating the Reasoning Behavior of Large Language Models -- A Survey
Philipp Mondorf, Barbara Plank
0
0
Large language models (LLMs) have recently shown impressive performance on tasks involving reasoning, leading to a lively debate on whether these models possess reasoning capabilities similar to humans. However, despite these successes, the depth of LLMs' reasoning abilities remains uncertain. This uncertainty partly stems from the predominant focus on task performance, measured through shallow accuracy metrics, rather than a thorough investigation of the models' reasoning behavior. This paper seeks to address this gap by providing a comprehensive review of studies that go beyond task accuracy, offering deeper insights into the models' reasoning processes. Furthermore, we survey prevalent methodologies to evaluate the reasoning behavior of LLMs, emphasizing current trends and efforts towards more nuanced reasoning analyses. Our review suggests that LLMs tend to rely on surface-level patterns and correlations in their training data, rather than on genuine reasoning abilities. Additionally, we identify the need for further research that delineates the key differences between human and LLM-based reasoning. Through this survey, we aim to shed light on the complex reasoning processes within LLMs.
4/3/2024
💬
NExT: Teaching Large Language Models to Reason about Code Execution
Ansong Ni, Miltiadis Allamanis, Arman Cohan, Yinlin Deng, Kensen Shi, Charles Sutton, Pengcheng Yin
0
0
A fundamental skill among human developers is the ability to understand and reason about program execution. As an example, a programmer can mentally simulate code execution in natural language to debug and repair code (aka. rubber duck debugging). However, large language models (LLMs) of code are typically trained on the surface textual form of programs, thus may lack a semantic understanding of how programs execute at run-time. To address this issue, we propose NExT, a method to teach LLMs to inspect the execution traces of programs (variable states of executed lines) and reason about their run-time behavior through chain-of-thought (CoT) rationales. Specifically, NExT uses self-training to bootstrap a synthetic training set of execution-aware rationales that lead to correct task solutions (e.g., fixed programs) without laborious manual annotation. Experiments on program repair tasks based on MBPP and HumanEval demonstrate that NExT improves the fix rate of a PaLM 2 model, by 26.1% and 14.3% absolute, respectively, with significantly improved rationale quality as verified by automated metrics and human raters. Our model can also generalize to scenarios where program traces are absent at test-time.
4/24/2024

InfiCoder-Eval: Systematically Evaluating the Question-Answering Capabilities of Code Large Language Models
Linyi Li, Shijie Geng, Zhenwen Li, Yibo He, Hao Yu, Ziyue Hua, Guanghan Ning, Siwei Wang, Tao Xie, Hongxia Yang
0
0
Large Language Models for understanding and generating code (code LLMs) have witnessed tremendous progress in recent years. With the rapid development of code LLMs, many popular evaluation benchmarks, such as HumanEval, DS-1000, and MBPP, have emerged to measure the performance of code LLMs with a particular focus on code generation tasks. However, they are insufficient to cover the full range of expected capabilities of code LLMs, which span beyond code generation to answering diverse coding-related questions. To fill this gap, we propose InfiCoder-Eval, a large-scale freeform question-answering (QA) benchmark for code, comprising 234 carefully selected high-quality Stack Overflow questions that span across 15 programming languages. To evaluate the response correctness, InfiCoder-Eval supports four types of model-free metrics and domain experts carefully choose and concretize the criterion for each question. We conduct a systematic evaluation for more than 80 code LLMs on InfiCoder-Eval, leading to a series of insightful findings. Furthermore, our detailed analyses showcase possible directions for further improvement of code LLMs. InfiCoder-Eval is fully open source at https://infi-coder.github.io/inficoder-eval/ and continuously maintaining and expanding to foster more scientific and systematic practices for evaluating code LLMs.
4/12/2024