NExT: Teaching Large Language Models to Reason about Code Execution
2404.14662
4
0
💬
Abstract
A fundamental skill among human developers is the ability to understand and reason about program execution. As an example, a programmer can mentally simulate code execution in natural language to debug and repair code (aka. rubber duck debugging). However, large language models (LLMs) of code are typically trained on the surface textual form of programs, thus may lack a semantic understanding of how programs execute at run-time. To address this issue, we propose NExT, a method to teach LLMs to inspect the execution traces of programs (variable states of executed lines) and reason about their run-time behavior through chain-of-thought (CoT) rationales. Specifically, NExT uses self-training to bootstrap a synthetic training set of execution-aware rationales that lead to correct task solutions (e.g., fixed programs) without laborious manual annotation. Experiments on program repair tasks based on MBPP and HumanEval demonstrate that NExT improves the fix rate of a PaLM 2 model, by 26.1% and 14.3% absolute, respectively, with significantly improved rationale quality as verified by automated metrics and human raters. Our model can also generalize to scenarios where program traces are absent at test-time.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Large language models (LLMs) are typically trained on the surface textual form of programs, which may lack a semantic understanding of how programs execute at run-time.
- The paper proposes NExT, a method to teach LLMs to inspect the execution traces of programs (variable states of executed lines) and reason about their run-time behavior through chain-of-thought (CoT) rationales.
- NExT uses self-training to bootstrap a synthetic training set of execution-aware rationales that lead to correct task solutions (e.g., fixed programs) without laborious manual annotation.
Plain English Explanation
Developers often have a strong intuition for how code will execute, allowing them to mentally simulate the program's behavior and use this understanding to debug and fix issues. However, large language models that are trained to understand and generate code may not naturally develop this semantic understanding of program execution.
To address this, the researchers developed a method called NExT that aims to teach LLMs to reason about the runtime behavior of programs. NExT does this by exposing the models to "execution traces" - detailed information about how variables change as the program runs. With this additional information, the models can learn to explain their thought processes in a step-by-step "chain-of-thought" when solving tasks like program repair.
The key innovation in NExT is that it uses a self-training approach to automatically generate these execution-aware explanations, rather than relying on costly manual annotation. By learning from these synthetic training examples, the LLMs can develop a more nuanced understanding of how programs execute and apply that knowledge to tasks like fixing broken code.
Technical Explanation
The paper proposes NExT, a method to teach large language models (LLMs) to reason about the runtime behavior of programs. NExT does this by exposing the models to "execution traces" - detailed information about how variables change as the program runs.
The core idea is to use self-training to bootstrap a synthetic training set of execution-aware rationales that lead to correct task solutions (e.g., fixed programs). This avoids the need for laborious manual annotation of such rationales.
Specifically, NExT works as follows:
- Train an initial LLM on code and its textual form alone, without execution traces.
- Use this initial model to generate candidate solutions (e.g., program fixes) for a set of training tasks.
- For each candidate solution, generate an execution trace and use it to construct a chain-of-thought (CoT) rationale explaining how the solution was derived.
- Fine-tune the initial LLM on this synthetic dataset of code, execution traces, and CoT rationales.
The paper evaluates NExT on program repair tasks from MBPP and HumanEval. Experiments show that NExT improves the fix rate of a PaLM 2 model by 26.1% and 14.3% absolute, respectively, with significantly improved rationale quality as verified by automated metrics and human raters.
Importantly, the paper also demonstrates that NExT can generalize to scenarios where program traces are absent at test-time, suggesting the models have developed a more semantic understanding of program execution.
Critical Analysis
The NExT approach represents an innovative step towards teaching large language models to reason about the runtime behavior of programs, rather than just their surface textual form. This is an important capability, as it aligns with how human developers often approach programming tasks.
That said, the paper acknowledges several limitations and areas for further research:
- The synthetic training data generated by NExT, while effective, may not fully capture the nuances of real-world program execution. Exploring ways to incorporate actual execution traces could further improve the models' understanding.
- The evaluation is limited to program repair tasks; extending NExT to a broader range of programming activities, such as code generation or program synthesis, would further demonstrate its generalizability.
- The paper does not explore how NExT's execution-aware reasoning could be combined with other techniques, such as program sketching or pseudocode execution, to create more powerful programming assistants.
- The performance improvements, while significant, still leave room for further advancements in program understanding and reasoning capabilities of large language models.
Overall, the NExT approach is a valuable contribution to the ongoing efforts to imbue LLMs with more robust and semantic understanding of code, as demonstrated by the GoEx project and others. Continued research in this direction has the potential to unlock new frontiers in human-AI collaboration for software development.
Conclusion
The paper proposes NExT, a method to teach large language models to reason about the runtime behavior of programs, rather than just their surface textual form. By exposing the models to execution traces and using self-training to generate execution-aware rationales, NExT enables LLMs to develop a more semantic understanding of how code behaves at runtime.
Experiments on program repair tasks show that NExT can significantly improve the performance and explainability of LLMs in these domains. While the approach has limitations and areas for further research, it represents an important step towards bridging the gap between how human developers and language models reason about code, with potential implications for a wide range of programming-related applications.
Related Papers
💬
Language Models as Compilers: Simulating Pseudocode Execution Improves Algorithmic Reasoning in Language Models
Hyungjoo Chae, Yeonghyeon Kim, Seungone Kim, Kai Tzu-iunn Ong, Beong-woo Kwak, Moohyeon Kim, Seonghwan Kim, Taeyoon Kwon, Jiwan Chung, Youngjae Yu, Jinyoung Yeo
0
0
Algorithmic reasoning refers to the ability to understand the complex patterns behind the problem and decompose them into a sequence of reasoning steps towards the solution. Such nature of algorithmic reasoning makes it a challenge for large language models (LLMs), even though they have demonstrated promising performance in other reasoning tasks. Within this context, some recent studies use programming languages (e.g., Python) to express the necessary logic for solving a given instance/question (e.g., Program-of-Thought) as inspired by their strict and precise syntaxes. However, it is non-trivial to write an executable code that expresses the correct logic on the fly within a single inference call. Also, the code generated specifically for an instance cannot be reused for others, even if they are from the same task and might require identical logic to solve. This paper presents Think-and-Execute, a novel framework that decomposes the reasoning process of language models into two steps. (1) In Think, we discover a task-level logic that is shared across all instances for solving a given task and then express the logic with pseudocode; (2) In Execute, we further tailor the generated pseudocode to each instance and simulate the execution of the code. With extensive experiments on seven algorithmic reasoning tasks, we demonstrate the effectiveness of Think-and-Execute. Our approach better improves LMs' reasoning compared to several strong baselines performing instance-specific reasoning (e.g., CoT and PoT), suggesting the helpfulness of discovering task-level logic. Also, we show that compared to natural language, pseudocode can better guide the reasoning of LMs, even though they are trained to follow natural language instructions.
4/4/2024
GoEX: Perspectives and Designs Towards a Runtime for Autonomous LLM Applications
Shishir G. Patil, Tianjun Zhang, Vivian Fang, Noppapon C., Roy Huang, Aaron Hao, Martin Casado, Joseph E. Gonzalez, Raluca Ada Popa, Ion Stoica
0
0
Large Language Models (LLMs) are evolving beyond their classical role of providing information within dialogue systems to actively engaging with tools and performing actions on real-world applications and services. Today, humans verify the correctness and appropriateness of the LLM-generated outputs (e.g., code, functions, or actions) before putting them into real-world execution. This poses significant challenges as code comprehension is well known to be notoriously difficult. In this paper, we study how humans can efficiently collaborate with, delegate to, and supervise autonomous LLMs in the future. We argue that in many cases, post-facto validation - verifying the correctness of a proposed action after seeing the output - is much easier than the aforementioned pre-facto validation setting. The core concept behind enabling a post-facto validation system is the integration of an intuitive undo feature, and establishing a damage confinement for the LLM-generated actions as effective strategies to mitigate the associated risks. Using this, a human can now either revert the effect of an LLM-generated output or be confident that the potential risk is bounded. We believe this is critical to unlock the potential for LLM agents to interact with applications and services with limited (post-facto) human involvement. We describe the design and implementation of our open-source runtime for executing LLM actions, Gorilla Execution Engine (GoEX), and present open research questions towards realizing the goal of LLMs and applications interacting with each other with minimal human supervision. We release GoEX at https://github.com/ShishirPatil/gorilla/.
4/11/2024
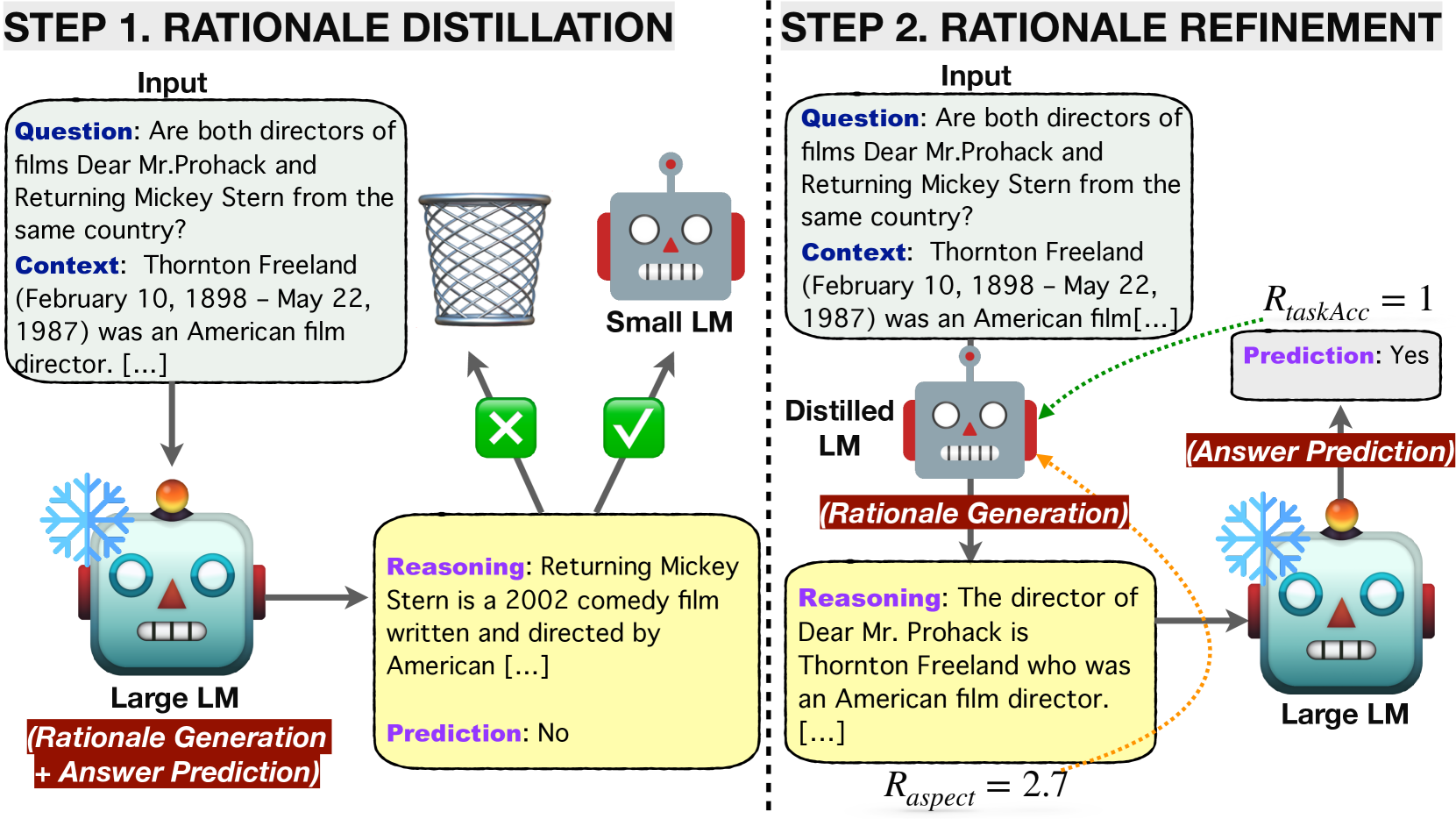
Can Small Language Models Help Large Language Models Reason Better?: LM-Guided Chain-of-Thought
Jooyoung Lee, Fan Yang, Thanh Tran, Qian Hu, Emre Barut, Kai-Wei Chang, Chengwei Su
0
0
We introduce a novel framework, LM-Guided CoT, that leverages a lightweight (i.e., 10B) LM in reasoning tasks. Specifically, the lightweight LM first generates a rationale for each input instance. The Frozen large LM is then prompted to predict a task output based on the rationale generated by the lightweight LM. Our approach is resource-efficient in the sense that it only requires training the lightweight LM. We optimize the model through 1) knowledge distillation and 2) reinforcement learning from rationale-oriented and task-oriented reward signals. We assess our method with multi-hop extractive question answering (QA) benchmarks, HotpotQA, and 2WikiMultiHopQA. Experimental results show that our approach outperforms all baselines regarding answer prediction accuracy. We also find that reinforcement learning helps the model to produce higher-quality rationales with improved QA performance.
4/5/2024
💬
Using Large Language Models for (De-)Formalization and Natural Argumentation Exercises for Beginner's Students
Merlin Carl (Europa-Universitat Flensburg)
0
0
We describe two systems currently being developed that use large language models for the automatized correction of (i) exercises in translating back and forth between natural language and the languages of propositional logic and first-order predicate logic and (ii) exercises in writing simple arguments in natural language in non-mathematical scenarios.
4/11/2024