CoEvol: Constructing Better Responses for Instruction Finetuning through Multi-Agent Cooperation
2406.07054
0
0

Abstract
In recent years, instruction fine-tuning (IFT) on large language models (LLMs) has garnered considerable attention to enhance model performance on unseen tasks. Attempts have been made on automatic construction and effective selection for IFT data. However, we posit that previous methods have not fully harnessed the potential of LLMs for enhancing data quality. The responses within IFT data could be further enhanced by leveraging the capabilities of LLMs themselves. In this paper, we propose CoEvol, an LLM-based multi-agent cooperation framework for the improvement of responses to instructions. To effectively refine the responses, we develop an iterative framework following a debate-advise-edit-judge paradigm. A two-stage multi-agent debate strategy is further devised to ensure the diversity and reliability of editing suggestions within the framework. Empirically, models equipped with CoEvol outperform competitive baselines evaluated by MT-Bench and AlpacaEval, demonstrating its effectiveness in enhancing instruction-following capabilities for LLMs.
Create account to get full access
Overview
- This paper introduces CoEvol, a method for constructing better responses for instruction finetuning through multi-agent cooperation.
- The key idea is to have multiple agents work together to generate high-quality responses, with each agent specializing in different aspects of the task.
- The agents learn to cooperate and improve their responses through an iterative process, similar to experiential co-learning and language model evolution.
Plain English Explanation
The paper proposes a new way to train AI systems to follow instructions better. The idea is to have multiple AI agents work together, with each agent focusing on a different part of the task. For example, one agent might specialize in understanding the instructions, while another focuses on generating a good response.
The agents learn to cooperate and improve their responses through an iterative process, similar to how humans learn new skills by practicing and getting feedback. Over time, the agents get better at working together to produce high-quality responses to instructions.
This approach builds on ideas from experiential co-learning, where multiple agents learn by interacting with each other, and language model evolution, where language models improve through an iterative process of training and refinement.
The key advantage of this approach is that it can lead to better responses to instructions, which is important for applications like automatic instruction finetuning and self-evolution of large language models.
Technical Explanation
The CoEvol method involves training multiple agents, each with a specialized role, to work together to generate high-quality responses to instructions. The agents' roles include:
- Instruction Encoder: This agent is responsible for understanding the instructions and extracting the key information needed to generate a response.
- Response Generator: This agent generates the actual response based on the extracted information from the Instruction Encoder.
- Evaluator: This agent assesses the quality of the generated response and provides feedback to the other agents.
The agents learn to cooperate and improve their responses through an iterative process. In each iteration, the agents take turns playing their respective roles, with the Evaluator providing feedback to the other agents. Over time, the agents learn to work together more effectively, leading to better responses.
The paper presents experiments demonstrating the effectiveness of the CoEvol approach compared to a baseline system that does not use multi-agent cooperation. The results show that the CoEvol method can generate higher-quality responses, particularly for more complex instructions.
Critical Analysis
The paper presents a promising approach to improving the quality of responses generated for instruction finetuning. The use of multiple, specialized agents working together is an interesting idea that builds on relevant research in areas like experiential co-learning and language model evolution.
One potential limitation of the approach is the complexity of training and coordinating multiple agents. The authors acknowledge that this could be a challenge, and further research may be needed to streamline the training process and ensure stable and reliable cooperation between the agents.
Additionally, the paper focuses on a specific task of responding to instructions, and it's unclear how well the CoEvol method would generalize to other types of language tasks or real-world applications. Further testing and evaluation would be needed to assess the broader applicability of the approach.
Overall, the CoEvol method represents an interesting and potentially valuable contribution to the field of instruction finetuning and language model improvement. The multi-agent cooperation approach is a novel idea that warrants further investigation and development.
Conclusion
The CoEvol method presented in this paper offers a novel approach to improving the quality of responses generated for instruction finetuning tasks. By having multiple specialized agents work together through an iterative learning process, the system can construct better responses than a single agent working alone.
This research builds on relevant work in areas like experiential co-learning and language model evolution, and it has the potential to enhance the performance of automatic instruction finetuning and self-evolution of large language models.
While the complexity of training and coordinating multiple agents may present some challenges, the CoEvol method represents an interesting and promising direction for further research and development in the field of language model improvement and instruction-following AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Automatic Instruction Evolving for Large Language Models
Weihao Zeng, Can Xu, Yingxiu Zhao, Jian-Guang Lou, Weizhu Chen
0
0
Fine-tuning large pre-trained language models with Evol-Instruct has achieved encouraging results across a wide range of tasks. However, designing effective evolving methods for instruction evolution requires substantial human expertise. This paper proposes Auto Evol-Instruct, an end-to-end framework that evolves instruction datasets using large language models without any human effort. The framework automatically analyzes and summarizes suitable evolutionary strategies for the given instruction data and iteratively improves the evolving method based on issues exposed during the instruction evolution process. Our extensive experiments demonstrate that the best method optimized by Auto Evol-Instruct outperforms human-designed methods on various benchmarks, including MT-Bench, AlpacaEval, GSM8K, and HumanEval.
6/4/2024
Instruction Fusion: Advancing Prompt Evolution through Hybridization
Weidong Guo, Jiuding Yang, Kaitong Yang, Xiangyang Li, Zhuwei Rao, Yu Xu, Di Niu
0
0
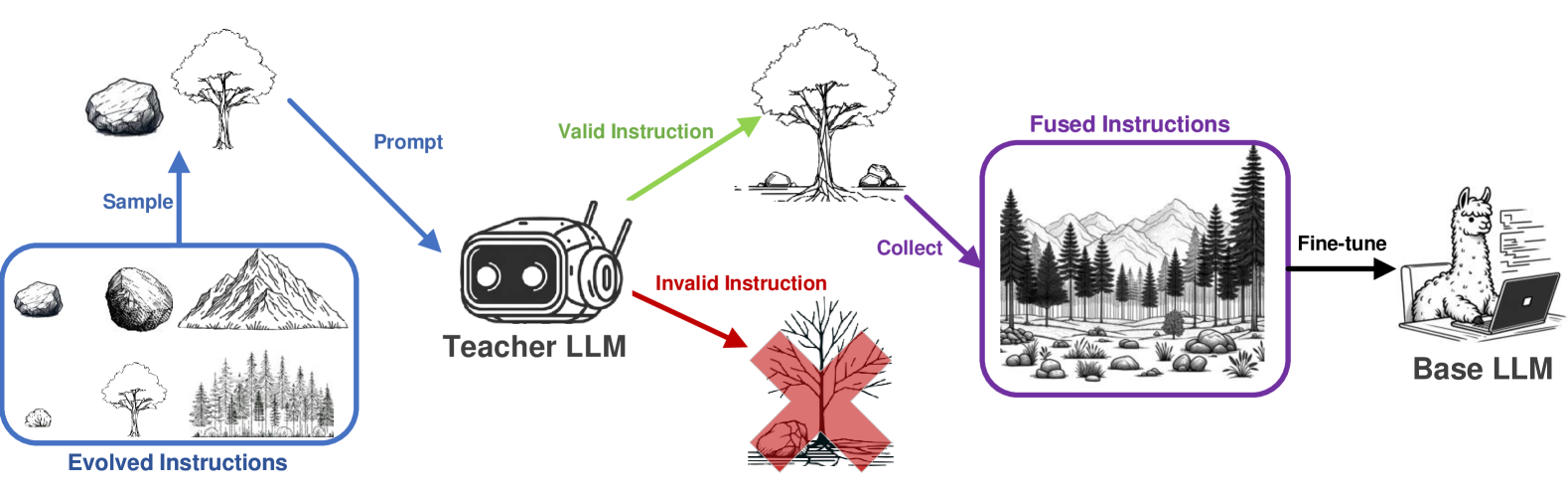
The fine-tuning of Large Language Models (LLMs) specialized in code generation has seen notable advancements through the use of open-domain coding queries. Despite the successes, existing methodologies like Evol-Instruct encounter performance limitations, impeding further enhancements in code generation tasks. This paper examines the constraints of existing prompt evolution techniques and introduces a novel approach, Instruction Fusion (IF). IF innovatively combines two distinct prompts through a hybridization process, thereby enhancing the evolution of training prompts for code LLMs. Our experimental results reveal that the proposed novel method effectively addresses the shortcomings of prior methods, significantly improving the performance of Code LLMs across five code generation benchmarks, namely HumanEval, HumanEval+, MBPP, MBPP+ and MultiPL-E, which underscore the effectiveness of Instruction Fusion in advancing the capabilities of LLMs in code generation.
6/18/2024
A Survey on Self-Evolution of Large Language Models
Zhengwei Tao, Ting-En Lin, Xiancai Chen, Hangyu Li, Yuchuan Wu, Yongbin Li, Zhi Jin, Fei Huang, Dacheng Tao, Jingren Zhou
0
0
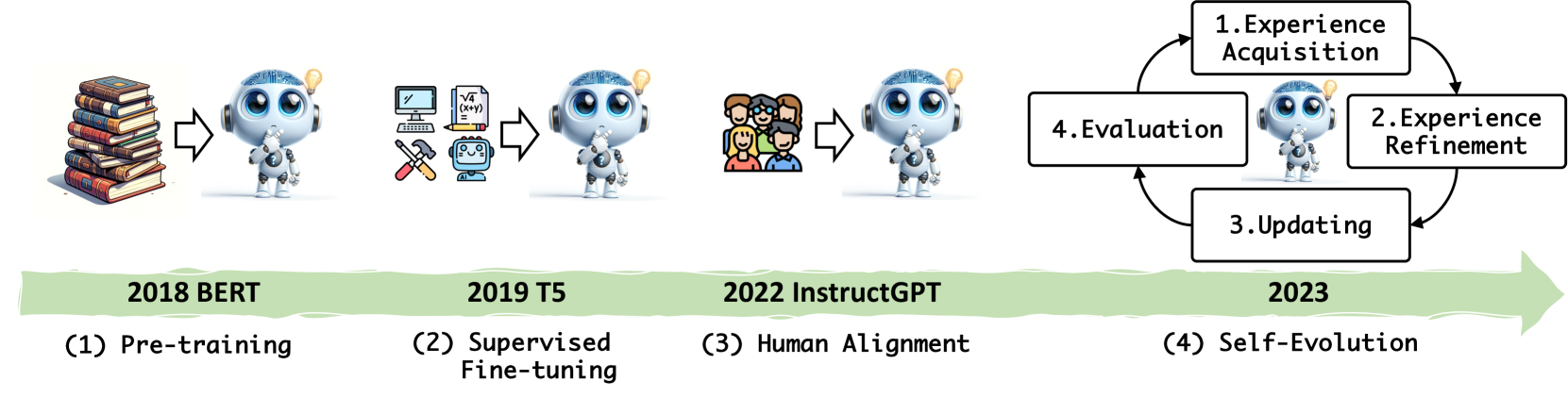
Large language models (LLMs) have significantly advanced in various fields and intelligent agent applications. However, current LLMs that learn from human or external model supervision are costly and may face performance ceilings as task complexity and diversity increase. To address this issue, self-evolution approaches that enable LLM to autonomously acquire, refine, and learn from experiences generated by the model itself are rapidly growing. This new training paradigm inspired by the human experiential learning process offers the potential to scale LLMs towards superintelligence. In this work, we present a comprehensive survey of self-evolution approaches in LLMs. We first propose a conceptual framework for self-evolution and outline the evolving process as iterative cycles composed of four phases: experience acquisition, experience refinement, updating, and evaluation. Second, we categorize the evolution objectives of LLMs and LLM-based agents; then, we summarize the literature and provide taxonomy and insights for each module. Lastly, we pinpoint existing challenges and propose future directions to improve self-evolution frameworks, equipping researchers with critical insights to fast-track the development of self-evolving LLMs. Our corresponding GitHub repository is available at https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/Awesome-Self-Evolution-of-LLM
6/4/2024
Self-Evolution Fine-Tuning for Policy Optimization
Ruijun Chen, Jiehao Liang, Shiping Gao, Fanqi Wan, Xiaojun Quan
0
0
The alignment of large language models (LLMs) is crucial not only for unlocking their potential in specific tasks but also for ensuring that responses meet human expectations and adhere to safety and ethical principles. Current alignment methodologies face considerable challenges. For instance, supervised fine-tuning (SFT) requires extensive, high-quality annotated samples, while reinforcement learning from human feedback (RLHF) is complex and often unstable. In this paper, we introduce self-evolution fine-tuning (SEFT) for policy optimization, with the aim of eliminating the need for annotated samples while retaining the stability and efficiency of SFT. SEFT first trains an adaptive reviser to elevate low-quality responses while maintaining high-quality ones. The reviser then gradually guides the policy's optimization by fine-tuning it with enhanced responses. One of the prominent features of this method is its ability to leverage unlimited amounts of unannotated data for policy optimization through supervised fine-tuning. Our experiments on AlpacaEval 2.0 and MT-Bench demonstrate the effectiveness of SEFT. We also provide a comprehensive analysis of its advantages over existing alignment techniques.
6/18/2024