Self-Evolution Fine-Tuning for Policy Optimization
2406.10813
0
0
Abstract
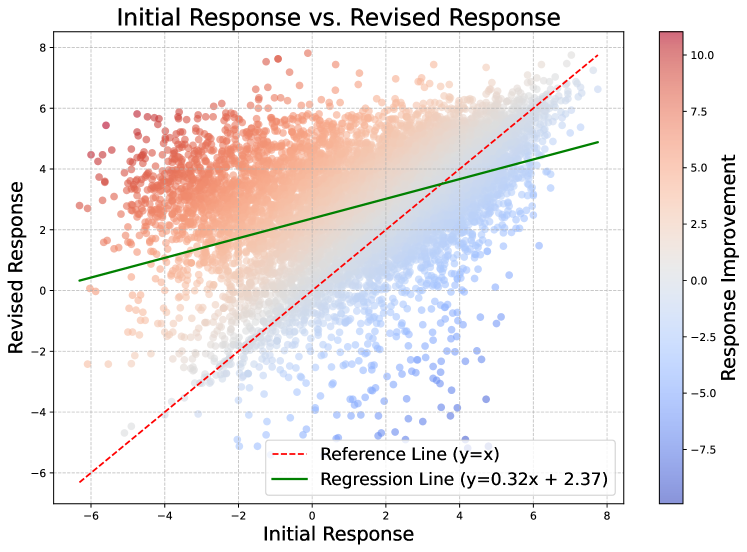
The alignment of large language models (LLMs) is crucial not only for unlocking their potential in specific tasks but also for ensuring that responses meet human expectations and adhere to safety and ethical principles. Current alignment methodologies face considerable challenges. For instance, supervised fine-tuning (SFT) requires extensive, high-quality annotated samples, while reinforcement learning from human feedback (RLHF) is complex and often unstable. In this paper, we introduce self-evolution fine-tuning (SEFT) for policy optimization, with the aim of eliminating the need for annotated samples while retaining the stability and efficiency of SFT. SEFT first trains an adaptive reviser to elevate low-quality responses while maintaining high-quality ones. The reviser then gradually guides the policy's optimization by fine-tuning it with enhanced responses. One of the prominent features of this method is its ability to leverage unlimited amounts of unannotated data for policy optimization through supervised fine-tuning. Our experiments on AlpacaEval 2.0 and MT-Bench demonstrate the effectiveness of SEFT. We also provide a comprehensive analysis of its advantages over existing alignment techniques.
Create account to get full access
Overview
- The paper proposes a novel approach called "Self-Evolution Fine-Tuning" (SEFT) for policy optimization in reinforcement learning.
- SEFT aims to enable agents to autonomously fine-tune their own policies during deployment, without relying on external feedback or rewards.
- The method leverages a self-supervised training process that allows the agent to learn and adapt its behavior based on its own experiences.
Plain English Explanation
In machine learning, reinforcement learning agents are often trained to perform specific tasks by receiving rewards or feedback from their environment. [object Object] and [object Object] have explored ways to improve this training process.
The authors of this paper take a different approach with "Self-Evolution Fine-Tuning" (SEFT). The key idea is to enable the agent to fine-tune its own policy during deployment, without relying on external feedback or rewards. Instead, the agent learns to adapt and improve its behavior based on its own experiences and internal signals.
This self-supervised fine-tuning process allows the agent to continually evolve and optimize its policy, potentially leading to more robust and flexible performance. The method could be particularly useful in situations where external feedback is limited or difficult to obtain, such as in [object Object] or [object Object].
By enabling agents to autonomously fine-tune their policies, the SEFT approach could pave the way for more [object Object], potentially leading to significant performance gains in a wide range of applications.
Technical Explanation
The SEFT approach consists of two key components:
-
Self-Supervised Fine-Tuning: During deployment, the agent continuously collects experiences and uses them to fine-tune its own policy in a self-supervised manner. This allows the agent to adapt its behavior based on its interactions with the environment, without relying on external rewards or feedback.
-
Evolutionary Algorithm: The authors leverage an evolutionary algorithm to guide the self-supervised fine-tuning process. This algorithm introduces controlled mutations to the agent's policy, which are then evaluated and selectively retained based on the agent's own internal signals and performance.
The authors conduct experiments across a variety of reinforcement learning environments, including classical control tasks and complex simulated environments. The results demonstrate that SEFT can outperform standard reinforcement learning approaches, particularly in scenarios where external rewards are sparse or delayed.
Critical Analysis
The paper presents a novel and promising approach to policy optimization, but it also acknowledges several limitations and areas for further research:
- The self-supervised fine-tuning process relies on the agent's ability to accurately assess its own performance and generate meaningful internal signals. In complex or partially observable environments, this may be a significant challenge.
- The evolutionary algorithm used in SEFT may be computationally expensive, especially as the policy complexity increases. Exploring more efficient optimization techniques could be an area for further investigation.
- The paper focuses on single-agent scenarios, but extending the SEFT approach to multi-agent settings could be an interesting direction for future research.
Additionally, while the experimental results are promising, it would be valuable to see more extensive evaluations, including comparisons to a broader range of state-of-the-art methods and exploration of the approach's scalability and robustness in larger-scale, real-world applications.
Conclusion
The "Self-Evolution Fine-Tuning" (SEFT) approach proposed in this paper represents a novel and potentially impactful advancement in reinforcement learning policy optimization. By enabling agents to autonomously fine-tune their own policies during deployment, SEFT could lead to more adaptive, self-improving systems that can thrive in complex, dynamic environments.
The self-supervised fine-tuning process and evolutionary optimization algorithm at the core of SEFT offer a promising direction for overcoming the limitations of traditional reinforcement learning approaches, particularly in scenarios where external rewards or feedback are scarce or difficult to obtain.
While the paper acknowledges several areas for further research and improvement, the SEFT method shows significant potential to drive progress in the field of reinforcement learning and open up new avenues for the development of more capable and versatile AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
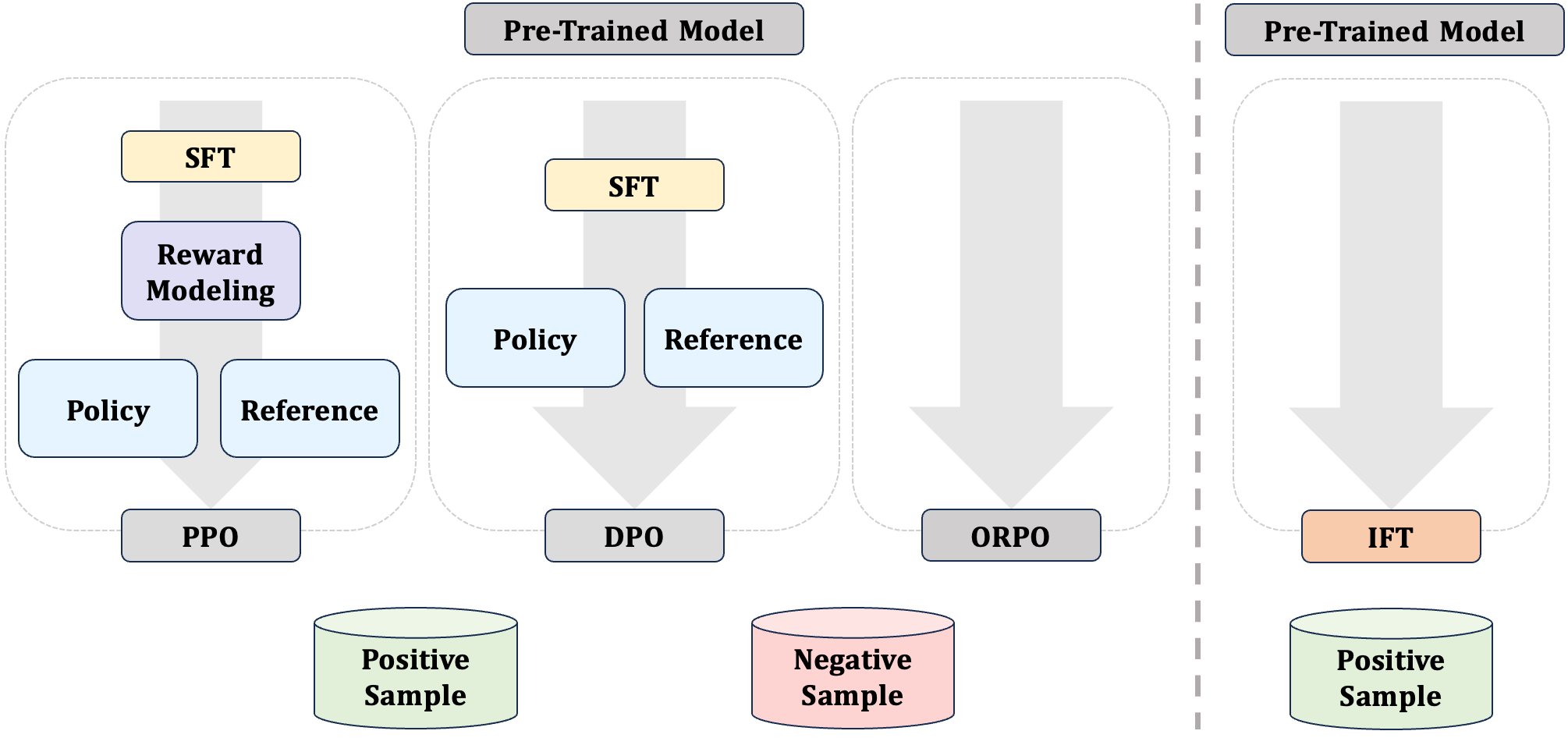
Intuitive Fine-Tuning: Towards Unifying SFT and RLHF into a Single Process
Ermo Hua, Biqing Qi, Kaiyan Zhang, Yue Yu, Ning Ding, Xingtai Lv, Kai Tian, Bowen Zhou
0
0
Supervised Fine-Tuning (SFT) and Preference Optimization (PO) are two fundamental processes for enhancing the capabilities of Language Models (LMs) post pre-training, aligning them better with human preferences. Although SFT advances in training efficiency, PO delivers better alignment, thus they are often combined. However, common practices simply apply them sequentially without integrating their optimization objectives, ignoring the opportunities to bridge their paradigm gap and take the strengths from both. To obtain a unified understanding, we interpret SFT and PO with two sub-processes -- Preference Estimation and Transition Optimization -- defined at token level within the Markov Decision Process (MDP) framework. This modeling shows that SFT is only a specialized case of PO with inferior estimation and optimization. PO evaluates the quality of model's entire generated answer, whereas SFT only scores predicted tokens based on preceding tokens from target answers. Therefore, SFT overestimates the ability of model, leading to inferior optimization. Building on this view, we introduce Intuitive Fine-Tuning (IFT) to integrate SFT and Preference Optimization into a single process. IFT captures LMs' intuitive sense of the entire answers through a temporal residual connection, but it solely relies on a single policy and the same volume of non-preference-labeled data as SFT. Our experiments show that IFT performs comparably or even superiorly to sequential recipes of SFT and some typical Preference Optimization methods across several tasks, particularly those requires generation, reasoning, and fact-following abilities. An explainable Frozen Lake game further validates the effectiveness of IFT for getting competitive policy.
5/29/2024
🏋️
Beyond Imitation: Leveraging Fine-grained Quality Signals for Alignment
Geyang Guo, Ranchi Zhao, Tianyi Tang, Wayne Xin Zhao, Ji-Rong Wen
0
0
Alignment with human preference is a desired property of large language models (LLMs). Currently, the main alignment approach is based on reinforcement learning from human feedback (RLHF). Despite the effectiveness of RLHF, it is intricate to implement and train, thus recent studies explore how to develop alternative alignment approaches based on supervised fine-tuning (SFT). A major limitation of SFT is that it essentially does imitation learning, which cannot fully understand what are the expected behaviors. To address this issue, we propose an improved alignment approach named FIGA. Different from prior methods, we incorporate fine-grained (i.e., token or phrase level) quality signals that are derived by contrasting good and bad responses. Our approach has made two major contributions. Firstly, we curate a refined alignment dataset that pairs initial responses and the corresponding revised ones. Secondly, we devise a new loss function can leverage fine-grained quality signals to instruct the learning of LLMs for alignment. Extensive experiments have demonstrated the effectiveness of our approaches by comparing a number of competitive baselines.
4/16/2024
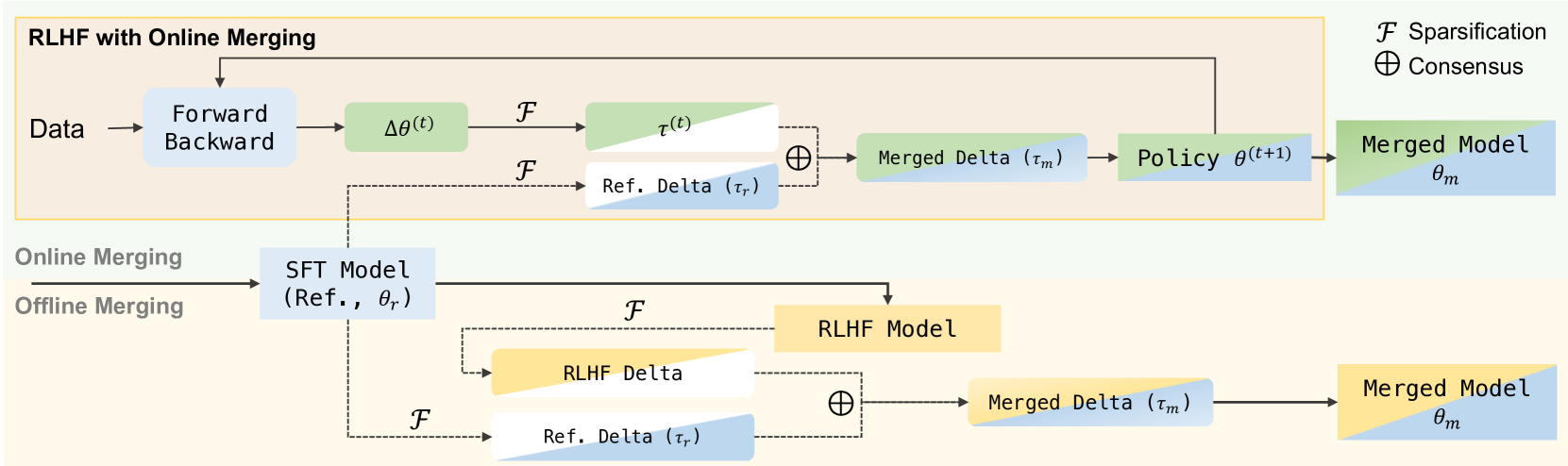
Online Merging Optimizers for Boosting Rewards and Mitigating Tax in Alignment
Keming Lu, Bowen Yu, Fei Huang, Yang Fan, Runji Lin, Chang Zhou
0
0
Effectively aligning Large Language Models (LLMs) with human-centric values while preventing the degradation of abilities acquired through Pre-training and Supervised Fine-tuning (SFT) poses a central challenge in Reinforcement Learning from Human Feedback (RLHF). In this paper, we first discover that interpolating RLHF and SFT model parameters can adjust the trade-off between human preference and basic capabilities, thereby reducing the alignment tax at the cost of alignment reward. Inspired by this, we propose integrating the RL policy and SFT models at each optimization step in RLHF to continuously regulate the training direction, introducing the Online Merging Optimizer. Specifically, we merge gradients with the parameter differences between SFT and pretrained models, effectively steering the gradient towards maximizing rewards in the direction of SFT optimization. We demonstrate that our optimizer works well with different LLM families, such as Qwen and LLaMA, across various model sizes ranging from 1.8B to 8B, various RLHF algorithms like DPO and KTO, and existing model merging methods. It significantly enhances alignment reward while mitigating alignment tax, achieving higher overall performance across 14 benchmarks.
5/29/2024

Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models
Zixiang Chen, Yihe Deng, Huizhuo Yuan, Kaixuan Ji, Quanquan Gu
0
0
Harnessing the power of human-annotated data through Supervised Fine-Tuning (SFT) is pivotal for advancing Large Language Models (LLMs). In this paper, we delve into the prospect of growing a strong LLM out of a weak one without the need for acquiring additional human-annotated data. We propose a new fine-tuning method called Self-Play fIne-tuNing (SPIN), which starts from a supervised fine-tuned model. At the heart of SPIN lies a self-play mechanism, where the LLM refines its capability by playing against instances of itself. More specifically, the LLM generates its own training data from its previous iterations, refining its policy by discerning these self-generated responses from those obtained from human-annotated data. Our method progressively elevates the LLM from a nascent model to a formidable one, unlocking the full potential of human-annotated demonstration data for SFT. Theoretically, we prove that the global optimum to the training objective function of our method is achieved only when the LLM policy aligns with the target data distribution. Empirically, we evaluate our method on several benchmark datasets including the HuggingFace Open LLM Leaderboard, MT-Bench, and datasets from Big-Bench. Our results show that SPIN can significantly improve the LLM's performance across a variety of benchmarks and even outperform models trained through direct preference optimization (DPO) supplemented with extra GPT-4 preference data. This sheds light on the promise of self-play, enabling the achievement of human-level performance in LLMs without the need for expert opponents. Codes are available at https://github.com/uclaml/SPIN.
6/18/2024