Automatic Instruction Evolving for Large Language Models
2406.00770
0
0

Abstract
Fine-tuning large pre-trained language models with Evol-Instruct has achieved encouraging results across a wide range of tasks. However, designing effective evolving methods for instruction evolution requires substantial human expertise. This paper proposes Auto Evol-Instruct, an end-to-end framework that evolves instruction datasets using large language models without any human effort. The framework automatically analyzes and summarizes suitable evolutionary strategies for the given instruction data and iteratively improves the evolving method based on issues exposed during the instruction evolution process. Our extensive experiments demonstrate that the best method optimized by Auto Evol-Instruct outperforms human-designed methods on various benchmarks, including MT-Bench, AlpacaEval, GSM8K, and HumanEval.
Create account to get full access
Overview
- This paper explores a novel approach called Automatic Instruction Evolving (AIE) for improving the performance of large language models (LLMs) on various tasks.
- The key idea is to automatically generate and refine instruction prompts to optimize the model's behavior, rather than relying on manually curated instructions.
- The authors demonstrate the effectiveness of AIE on several benchmark tasks, showing significant improvements over standard fine-tuning approaches.
- The work has implications for enhancing code generation with large language models, instruction-based knowledge editing, and simulator-augmented instruction alignment.
Plain English Explanation
Large language models (LLMs) like GPT-3 have shown remarkable capabilities in generating human-like text, answering questions, and even completing coding tasks. However, their performance can be inconsistent and depend heavily on the instructions or prompts given to them.
The researchers in this paper developed a new approach called Automatic Instruction Evolving (AIE) to address this issue. The key idea is to automatically generate and refine the instructions or "prompts" used to guide the LLM, rather than relying on manually curated prompts.
Imagine you're training a language model to write movie reviews. Instead of providing a fixed set of instructions, the AIE approach would automatically generate and test different prompts, such as "Analyze the character development in the film" or "Describe the cinematic style and its impact on the story." The model would then learn which prompts work best and refine them over time to improve its movie review writing abilities.
By automating this process, the researchers found that the LLM could perform significantly better on a variety of tasks compared to standard fine-tuning approaches that use manually created prompts. This could have important implications for enhancing code generation, knowledge editing, and simulator-based instruction alignment - areas where the ability to provide effective instructions to an LLM is crucial.
Technical Explanation
The core of the Automatic Instruction Evolving (AIE) approach is an optimization process that automatically generates and refines instruction prompts to improve a large language model's (LLM) performance on a given task.
The authors first define a set of parameterized instruction templates, which serve as the building blocks for the generated prompts. These templates can include placeholders for task-specific information, such as the desired output format or the scope of the analysis.
The optimization process then iteratively generates prompt candidates by sampling from the template space, evaluates the LLM's performance on a validation set using these prompts, and updates the prompt parameters to maximize the model's performance. This cycle continues until a satisfactory prompt is found.
The authors demonstrate the effectiveness of AIE on several benchmark tasks, including text summarization, question answering, and code generation. Compared to standard fine-tuning approaches that use manually curated prompts, the AIE-optimized prompts lead to significant improvements in the LLM's performance across these tasks.
The authors also discuss the potential applications of AIE, such as enhancing code generation, instruction-based knowledge editing, and simulator-augmented instruction alignment. In these areas, the ability to automatically generate effective instructions can be a game-changer, as it reduces the reliance on manual prompt engineering and enables more flexible and robust model behavior.
Critical Analysis
The Automatic Instruction Evolving (AIE) approach presented in the paper is a promising step towards improving the performance and reliability of large language models (LLMs) on a wide range of tasks. By automatically generating and refining instruction prompts, the authors demonstrate significant improvements over standard fine-tuning methods that rely on manually curated prompts.
One potential limitation of the current work is the dependence on a predefined set of instruction templates. While the authors show that this template-based approach can be effective, it may not capture the full diversity of prompts that could potentially benefit the LLM. Exploring more open-ended prompt generation methods, perhaps using generative models, could further enhance the capabilities of the AIE approach.
Additionally, the paper primarily focuses on evaluating the AIE approach on benchmark tasks, such as text summarization and question answering. While these tasks are valuable for assessing the model's capabilities, it would be interesting to see how the AIE-optimized prompts perform on more open-ended or creative tasks, such as text-to-music generation or self-evolution of language models. Expanding the evaluation to a broader range of applications could further demonstrate the versatility and potential impact of the AIE approach.
Nonetheless, the Automatic Instruction Evolving method presented in this paper represents an important step forward in enhancing the capabilities and reliability of large language models. By automatically generating effective instructions, the approach could have far-reaching implications for numerous AI applications that rely on these powerful language models.
Conclusion
The Automatic Instruction Evolving (AIE) approach described in this paper offers a novel and effective way to improve the performance of large language models (LLMs) on a variety of tasks. By automatically generating and refining instruction prompts, the method reduces the reliance on manually curated prompts and enables the LLM to adapt more flexibly to the given task.
The authors demonstrate the effectiveness of AIE on several benchmark tasks, showing significant improvements over standard fine-tuning approaches. This has important implications for enhancing code generation, instruction-based knowledge editing, and simulator-augmented instruction alignment - areas where the ability to provide effective instructions to an LLM is crucial.
While the current work relies on a predefined set of instruction templates, future research could explore more open-ended prompt generation methods to further expand the capabilities of the AIE approach. Applying the method to a broader range of applications, including text-to-music generation and self-evolution of language models, could also yield valuable insights and broaden the impact of this innovative technique.
Overall, the Automatic Instruction Evolving approach represents an important advancement in the field of large language model optimization, with the potential to significantly enhance the reliability and versatility of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
⚙️
EasyInstruct: An Easy-to-use Instruction Processing Framework for Large Language Models
Yixin Ou, Ningyu Zhang, Honghao Gui, Ziwen Xu, Shuofei Qiao, Yida Xue, Runnan Fang, Kangwei Liu, Lei Li, Zhen Bi, Guozhou Zheng, Huajun Chen
0
0
In recent years, instruction tuning has gained increasing attention and emerged as a crucial technique to enhance the capabilities of Large Language Models (LLMs). To construct high-quality instruction datasets, many instruction processing approaches have been proposed, aiming to achieve a delicate balance between data quantity and data quality. Nevertheless, due to inconsistencies that persist among various instruction processing methods, there is no standard open-source instruction processing implementation framework available for the community, which hinders practitioners from further developing and advancing. To facilitate instruction processing research and development, we present EasyInstruct, an easy-to-use instruction processing framework for LLMs, which modularizes instruction generation, selection, and prompting, while also considering their combination and interaction. EasyInstruct is publicly released and actively maintained at https://github.com/zjunlp/EasyInstruct, along with an online demo app and a demo video for quick-start, calling for broader research centered on instruction data and synthetic data.
6/26/2024

CoEvol: Constructing Better Responses for Instruction Finetuning through Multi-Agent Cooperation
Renhao Li, Minghuan Tan, Derek F. Wong, Min Yang
0
0
In recent years, instruction fine-tuning (IFT) on large language models (LLMs) has garnered considerable attention to enhance model performance on unseen tasks. Attempts have been made on automatic construction and effective selection for IFT data. However, we posit that previous methods have not fully harnessed the potential of LLMs for enhancing data quality. The responses within IFT data could be further enhanced by leveraging the capabilities of LLMs themselves. In this paper, we propose CoEvol, an LLM-based multi-agent cooperation framework for the improvement of responses to instructions. To effectively refine the responses, we develop an iterative framework following a debate-advise-edit-judge paradigm. A two-stage multi-agent debate strategy is further devised to ensure the diversity and reliability of editing suggestions within the framework. Empirically, models equipped with CoEvol outperform competitive baselines evaluated by MT-Bench and AlpacaEval, demonstrating its effectiveness in enhancing instruction-following capabilities for LLMs.
6/12/2024
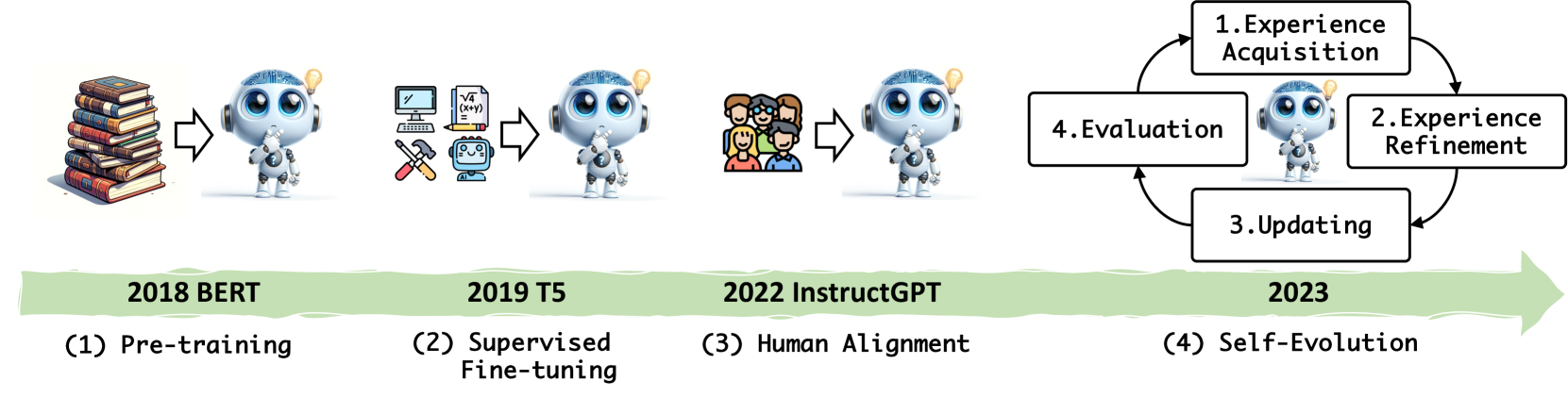
A Survey on Self-Evolution of Large Language Models
Zhengwei Tao, Ting-En Lin, Xiancai Chen, Hangyu Li, Yuchuan Wu, Yongbin Li, Zhi Jin, Fei Huang, Dacheng Tao, Jingren Zhou
0
0
Large language models (LLMs) have significantly advanced in various fields and intelligent agent applications. However, current LLMs that learn from human or external model supervision are costly and may face performance ceilings as task complexity and diversity increase. To address this issue, self-evolution approaches that enable LLM to autonomously acquire, refine, and learn from experiences generated by the model itself are rapidly growing. This new training paradigm inspired by the human experiential learning process offers the potential to scale LLMs towards superintelligence. In this work, we present a comprehensive survey of self-evolution approaches in LLMs. We first propose a conceptual framework for self-evolution and outline the evolving process as iterative cycles composed of four phases: experience acquisition, experience refinement, updating, and evaluation. Second, we categorize the evolution objectives of LLMs and LLM-based agents; then, we summarize the literature and provide taxonomy and insights for each module. Lastly, we pinpoint existing challenges and propose future directions to improve self-evolution frameworks, equipping researchers with critical insights to fast-track the development of self-evolving LLMs. Our corresponding GitHub repository is available at https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/Awesome-Self-Evolution-of-LLM
6/4/2024

Self-play with Execution Feedback: Improving Instruction-following Capabilities of Large Language Models
Guanting Dong, Keming Lu, Chengpeng Li, Tingyu Xia, Bowen Yu, Chang Zhou, Jingren Zhou
0
0
One core capability of large language models (LLMs) is to follow natural language instructions. However, the issue of automatically constructing high-quality training data to enhance the complex instruction-following abilities of LLMs without manual annotation remains unresolved. In this paper, we introduce AutoIF, the first scalable and reliable method for automatically generating instruction-following training data. AutoIF transforms the validation of instruction-following data quality into code verification, requiring LLMs to generate instructions, the corresponding code to check the correctness of the instruction responses, and unit test samples to verify the code's correctness. Then, execution feedback-based rejection sampling can generate data for Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF) training. AutoIF achieves significant improvements across three training algorithms, SFT, Offline DPO, and Online DPO, when applied to the top open-source LLMs, Qwen2 and LLaMA3, in self-alignment and strong-to-weak distillation settings. Our code is publicly available at https://github.com/QwenLM/AutoIF.
6/21/2024