Cognitive Bias in High-Stakes Decision-Making with LLMs

0

Sign in to get full access
Overview
- The provided paper examines the cognitive biases that can arise when using large language models (LLMs) for high-stakes decision-making.
- The research investigates how LLMs may exhibit similar biases to humans and the potential consequences in critical applications.
- Key insights and limitations of the research are discussed to encourage critical thinking.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. These models are increasingly being used to assist with important decisions, such as in healthcare or finance. However, the provided paper suggests that LLMs may exhibit similar cognitive biases as humans, which could lead to problematic outcomes in high-stakes scenarios.
Cognitive biases are tendencies in our thinking that can cause us to make irrational or suboptimal decisions. For example, the "anchoring bias" leads us to overly rely on the first piece of information we receive. Researchers found that LLMs can demonstrate these same biases, which could cause them to make flawed recommendations when used for critical applications.
The paper explores specific examples of how LLMs may be affected by biases like anchoring, confirmation, and availability. These biases could lead an LLM to make poor choices in high-stakes scenarios, with potentially serious consequences for human lives and wellbeing.
The researchers emphasize the importance of understanding and mitigating these biases, especially as LLMs become more widely adopted. Ongoing work is exploring ways to make LLMs less susceptible to cognitive biases and ensure their fairness in critical applications.
Technical Explanation
The paper investigates the potential for cognitive biases to arise in large language models (LLMs) when used for high-stakes decision-making. The researchers conducted experiments to test whether LLMs exhibit biases similar to those observed in human decision-making.
The experimental design involved presenting LLMs with scenarios that are known to trigger specific cognitive biases, such as the anchoring bias, confirmation bias, and availability bias. The researchers then analyzed the LLMs' responses to assess whether they demonstrated these biases.
The results showed that LLMs can indeed display cognitive biases, with the models making decisions that are influenced by the initial information provided, their existing beliefs, and the salience of certain pieces of information. These biases could lead LLMs to make flawed recommendations in critical applications, with potentially serious consequences.
The paper discusses the implications of these findings, highlighting the need for a deeper understanding of how LLMs process information and make decisions. The researchers also suggest potential mitigation strategies, such as incorporating debiasing techniques into the model training process or developing methods to detect and correct for biases in the LLM's outputs.
Critical Analysis
The paper provides valuable insights into the potential cognitive biases that can arise in large language models (LLMs) used for high-stakes decision-making. By demonstrating that LLMs can exhibit biases similar to those observed in humans, the research highlights an important consideration for the deployment of these models in critical applications.
However, the paper also acknowledges several limitations and areas for future research. For instance, the experiments were conducted using a limited set of scenarios and biases, and it remains to be seen how these findings scale to more complex, real-world decision-making contexts. Additionally, the researchers note that the specific mechanisms underlying the LLMs' biases are not fully understood and require further investigation.
Moreover, the paper does not address the potential impact of model architecture, training data, or fine-tuning on the emergence of cognitive biases. It would be valuable to explore how these factors may influence the susceptibility of LLMs to biases and the effectiveness of debiasing strategies.
Overall, the research raises important questions about the reliability and trustworthiness of LLMs in high-stakes decision-making. It underscores the need for continued scrutiny and mitigation efforts to ensure that these powerful AI systems are deployed responsibly and equitably, particularly in domains where their decisions can have significant consequences for human lives and wellbeing.
Conclusion
The paper's findings highlight the critical importance of understanding and addressing the cognitive biases that can arise in large language models (LLMs) used for high-stakes decision-making. As these models become more widely adopted, it is essential to develop robust strategies to detect, mitigate, and correct for biases to ensure their reliable and equitable deployment in crucial applications.
The research presented in this paper is an important step towards a deeper understanding of the limitations and potential risks associated with using LLMs in critical decision-making contexts. By encouraging further investigation and the development of effective debiasing techniques, this work contributes to the ongoing efforts to create AI systems that are trustworthy, fair, and aligned with human values.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Cognitive Bias in High-Stakes Decision-Making with LLMs
Jessica Echterhoff, Yao Liu, Abeer Alessa, Julian McAuley, Zexue He
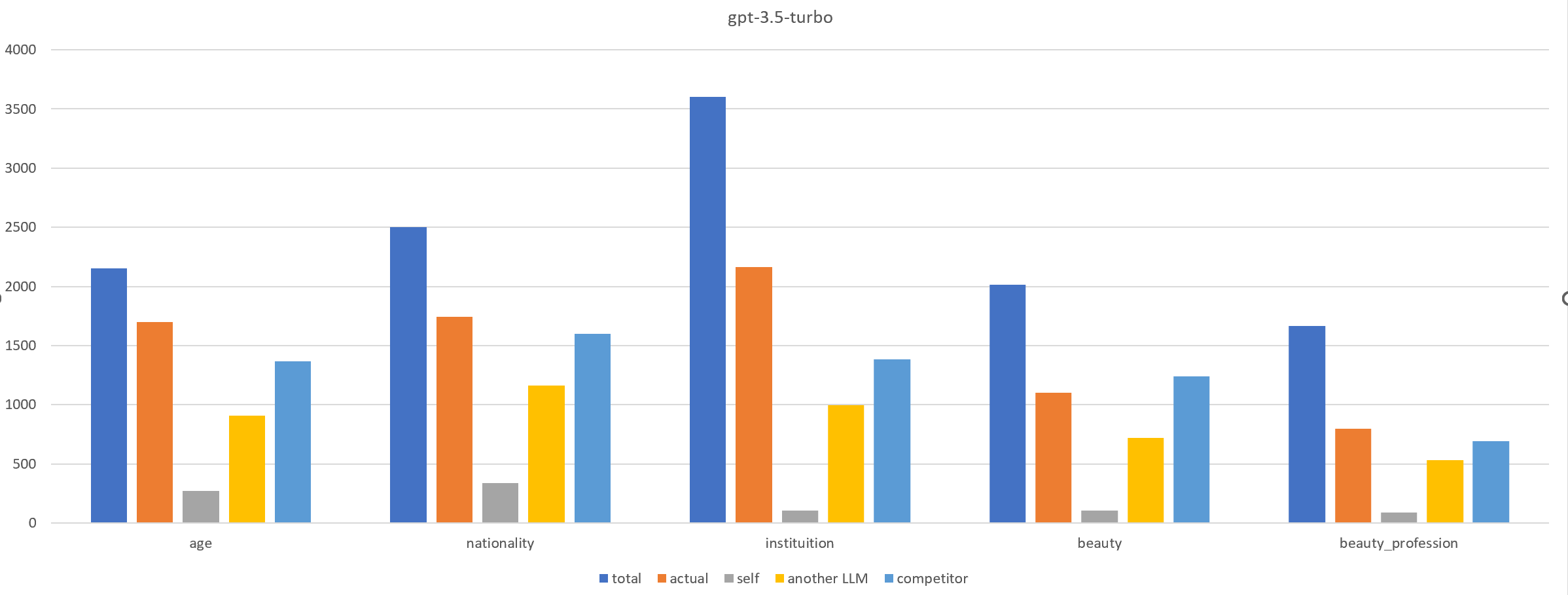
Large language models (LLMs) offer significant potential as tools to support an expanding range of decision-making tasks. Given their training on human (created) data, LLMs have been shown to inherit societal biases against protected groups, as well as be subject to bias functionally resembling cognitive bias. Human-like bias can impede fair and explainable decisions made with LLM assistance. Our work introduces BiasBuster, a framework designed to uncover, evaluate, and mitigate cognitive bias in LLMs, particularly in high-stakes decision-making tasks. Inspired by prior research in psychology and cognitive science, we develop a dataset containing 16,800 prompts to evaluate different cognitive biases (e.g., prompt-induced, sequential, inherent). We test various bias mitigation strategies, amidst proposing a novel method utilising LLMs to debias their own prompts. Our analysis provides a comprehensive picture of the presence and effects of cognitive bias across commercial and open-source models. We demonstrate that our self-help debiasing effectively mitigates model answers that display patterns akin to human cognitive bias without having to manually craft examples for each bias.
Read more7/22/2024
🌀
0
Bias patterns in the application of LLMs for clinical decision support: A comprehensive study
Raphael Poulain, Hamed Fayyaz, Rahmatollah Beheshti
Large Language Models (LLMs) have emerged as powerful candidates to inform clinical decision-making processes. While these models play an increasingly prominent role in shaping the digital landscape, two growing concerns emerge in healthcare applications: 1) to what extent do LLMs exhibit social bias based on patients' protected attributes (like race), and 2) how do design choices (like architecture design and prompting strategies) influence the observed biases? To answer these questions rigorously, we evaluated eight popular LLMs across three question-answering (QA) datasets using clinical vignettes (patient descriptions) standardized for bias evaluations. We employ red-teaming strategies to analyze how demographics affect LLM outputs, comparing both general-purpose and clinically-trained models. Our extensive experiments reveal various disparities (some significant) across protected groups. We also observe several counter-intuitive patterns such as larger models not being necessarily less biased and fined-tuned models on medical data not being necessarily better than the general-purpose models. Furthermore, our study demonstrates the impact of prompt design on bias patterns and shows that specific phrasing can influence bias patterns and reflection-type approaches (like Chain of Thought) can reduce biased outcomes effectively. Consistent with prior studies, we call on additional evaluations, scrutiny, and enhancement of LLMs used in clinical decision support applications.
Read more4/24/2024
0
Deceiving to Enlighten: Coaxing LLMs to Self-Reflection for Enhanced Bias Detection and Mitigation
Ruoxi Cheng, Haoxuan Ma, Shuirong Cao, Jiaqi Li, Aihua Pei, Zhiqiang Wang, Pengliang Ji, Haoyu Wang, Jiaqi Huo
Bias in LLMs can harm user experience and societal outcomes. However, current bias mitigation methods often require intensive human feedback, lack transferability to other topics or yield overconfident and random outputs. We find that involving LLMs in role-playing scenario boosts their ability to recognize and mitigate biases. Based on this, we propose Reinforcement Learning from Multi-role Debates as Feedback (RLDF), a novel approach for bias mitigation replacing human feedback in traditional RLHF. We utilize LLMs in multi-role debates to create a dataset that includes both high-bias and low-bias instances for training the reward model in reinforcement learning. Our approach comprises two modes: (1) self-reflection, where the same LLM participates in multi-role debates, and (2) teacher-student, where a more advanced LLM like GPT-3.5-turbo guides the LLM to perform this task. Experimental results across different LLMs demonstrate the effectiveness of our approach in bias mitigation.
Read more6/19/2024

0
Predicting and Understanding Human Action Decisions: Insights from Large Language Models and Cognitive Instance-Based Learning
Thuy Ngoc Nguyen, Kasturi Jamale, Cleotilde Gonzalez
Large Language Models (LLMs) have demonstrated their capabilities across various tasks, from language translation to complex reasoning. Understanding and predicting human behavior and biases are crucial for artificial intelligence (AI) assisted systems to provide useful assistance, yet it remains an open question whether these models can achieve this. This paper addresses this gap by leveraging the reasoning and generative capabilities of the LLMs to predict human behavior in two sequential decision-making tasks. These tasks involve balancing between exploitative and exploratory actions and handling delayed feedback, both essential for simulating real-life decision processes. We compare the performance of LLMs with a cognitive instance-based learning (IBL) model, which imitates human experiential decision-making. Our findings indicate that LLMs excel at rapidly incorporating feedback to enhance prediction accuracy. In contrast, the cognitive IBL model better accounts for human exploratory behaviors and effectively captures loss aversion bias, i.e., the tendency to choose a sub-optimal goal with fewer step-cost penalties rather than exploring to find the optimal choice, even with limited experience. The results highlight the benefits of integrating LLMs with cognitive architectures, suggesting that this synergy could enhance the modeling and understanding of complex human decision-making patterns.
Read more7/15/2024