A Collaborative PIM Computing Optimization Framework for Multi-Tenant DNN

0

Sign in to get full access
Overview
- This paper presents a collaborative PIM (Processing-in-Memory) computing optimization framework for multi-tenant deep neural networks (DNNs).
- The framework aims to efficiently utilize PIM resources and optimize performance for multiple DNN models running concurrently on the same hardware.
- Key aspects include resource allocation, task scheduling, and energy-efficient execution.
Plain English Explanation
The paper discusses a new way to run multiple deep learning models on the same specialized hardware called Processing-in-Memory (PIM). PIM allows computation to happen directly within the memory, improving efficiency.
The challenge is that when you run multiple deep learning models at the same time on the same PIM hardware, you need to carefully manage the resources to make sure each model gets what it needs without slowing down the others. The researchers developed a framework to do this optimization automatically.
The framework has a few key parts:
- Resource Allocation: It figures out how to divide up the limited PIM resources (memory, compute, etc.) between the different models in the best way.
- Task Scheduling: It schedules the execution of the different models' tasks to run efficiently on the shared PIM hardware.
- Energy Optimization: It finds ways to run the models in the most energy-efficient manner.
The goal is to allow multiple deep learning models to run concurrently on PIM hardware in a way that is fast and power-efficient, without one model interfering with the others.
Technical Explanation
The paper presents a collaborative PIM computing optimization framework for running multiple deep neural network (DNN) models on the same PIM hardware.
The key components of the framework include:
-
Resource Allocation: The framework uses a multi-dimensional resource allocation algorithm to efficiently partition the limited PIM resources (e.g., memory, compute units) among the co-located DNN models. This ensures fair and optimal utilization of the PIM resources.
-
Task Scheduling: A priority-based task scheduling mechanism is used to coordinate the execution of DNN tasks from different models on the shared PIM hardware. This minimizes interference and improves overall throughput.
-
Energy Optimization: An energy-aware execution strategy is employed to minimize the overall energy consumption of the system. This involves techniques like task batching, DVFS, and dynamic resource right-sizing.
The framework is designed to work with heterogeneous PIM hardware and supports various DNN models with different resource requirements. Extensive experiments are conducted to evaluate the framework's performance, resource efficiency, and energy savings compared to baseline approaches.
Critical Analysis
The paper presents a comprehensive framework for optimizing the execution of multi-tenant DNN models on PIM hardware. The proposed techniques for resource allocation, task scheduling, and energy optimization appear well-designed and grounded in previous research.
However, the paper does not fully address potential challenges that may arise in real-world deployments. For example, it does not explore the impact of dynamic workload changes or the ability to handle unexpected failures or faults in the PIM hardware. Additionally, the evaluation is limited to simulations and does not include any real-world deployments or user studies to assess the practical implications of the framework.
Further research could investigate the framework's robustness and adaptability to more complex, dynamic scenarios. Incorporating feedback from actual users and system administrators could also help identify additional requirements and refine the optimization strategies.
Conclusion
This paper presents a collaborative PIM computing optimization framework that enables efficient, energy-aware execution of multiple DNN models on shared PIM hardware. By addressing resource allocation, task scheduling, and energy optimization, the framework aims to maximize the utilization and performance of PIM systems running diverse DNN workloads.
While the proposed techniques appear promising, further exploration of real-world deployment challenges and user feedback could help strengthen the framework and its practical application in the field of AI model acceleration.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Collaborative PIM Computing Optimization Framework for Multi-Tenant DNN
Bojing Li, Duo Zhong, Xiang Chen, Chenchen Liu
Modern Artificial Intelligence (AI) applications are increasingly utilizing multi-tenant deep neural networks (DNNs), which lead to a significant rise in computing complexity and the need for computing parallelism. ReRAM-based processing-in-memory (PIM) computing, with its high density and low power consumption characteristics, holds promising potential for supporting the deployment of multi-tenant DNNs. However, direct deployment of complex multi-tenant DNNs on exsiting ReRAM-based PIM designs poses challenges. Resource contention among different tenants can result in sever under-utilization of on-chip computing resources. Moreover, area-intensive operators and computation-intensive operators require excessively large on-chip areas and long processing times, leading to high overall latency during parallel computing. To address these challenges, we propose a novel ReRAM-based in-memory computing framework that enables efficient deployment of multi-tenant DNNs on ReRAM-based PIM designs. Our approach tackles the resource contention problems by iteratively partitioning the PIM hardware at tenant level. In addition, we construct a fine-grained reconstructed processing pipeline at the operator level to handle area-intensive operators. Compared to the direct deployments on traditional ReRAM-based PIM designs, our proposed PIM computing framework achieves significant improvements in speed (ranges from 1.75x to 60.43x) and energy(up to 1.89x).
Read more8/12/2024
0
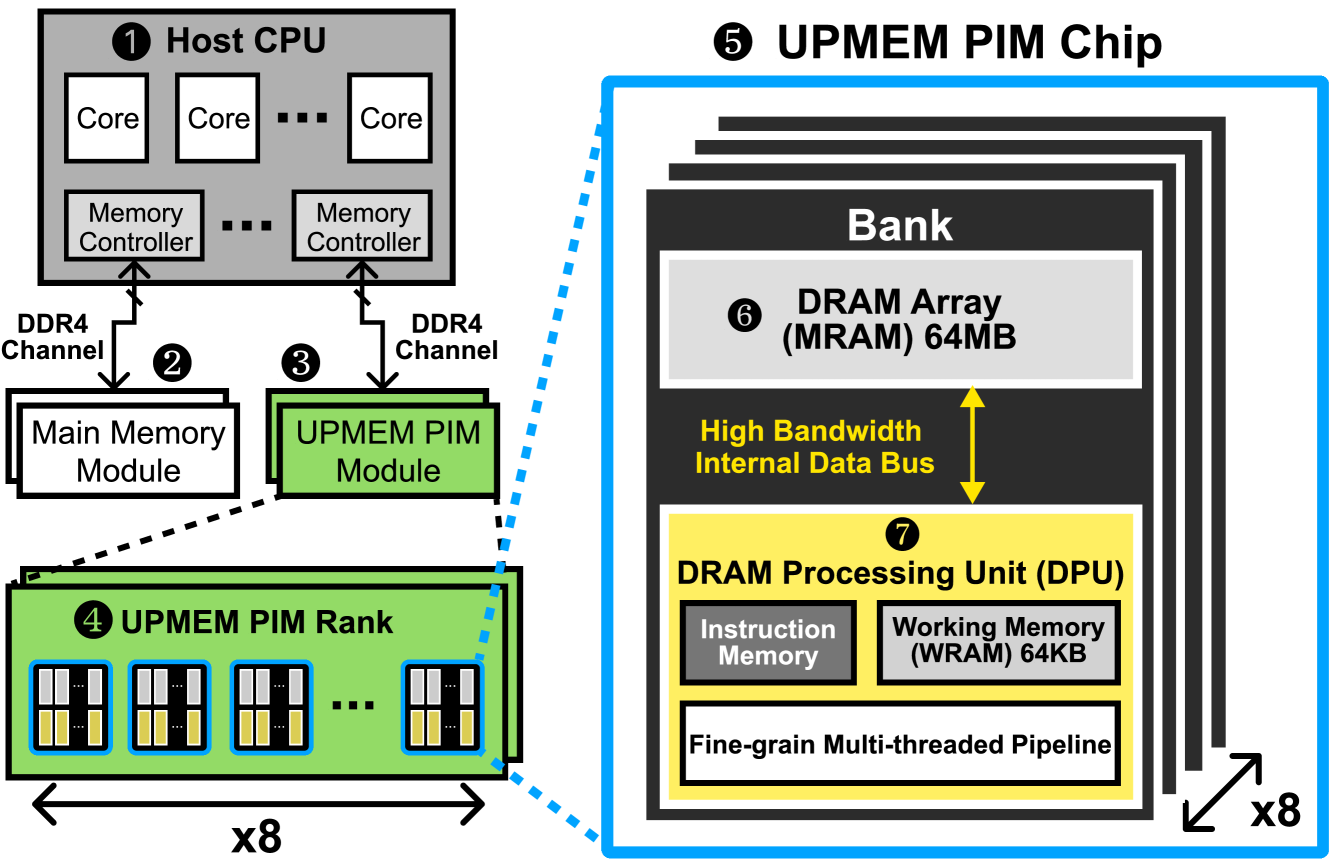
Analysis of Distributed Optimization Algorithms on a Real Processing-In-Memory System
Steve Rhyner, Haocong Luo, Juan G'omez-Luna, Mohammad Sadrosadati, Jiawei Jiang, Ataberk Olgun, Harshita Gupta, Ce Zhang, Onur Mutlu
Machine Learning (ML) training on large-scale datasets is a very expensive and time-consuming workload. Processor-centric architectures (e.g., CPU, GPU) commonly used for modern ML training workloads are limited by the data movement bottleneck, i.e., due to repeatedly accessing the training dataset. As a result, processor-centric systems suffer from performance degradation and high energy consumption. Processing-In-Memory (PIM) is a promising solution to alleviate the data movement bottleneck by placing the computation mechanisms inside or near memory. Our goal is to understand the capabilities and characteristics of popular distributed optimization algorithms on real-world PIM architectures to accelerate data-intensive ML training workloads. To this end, we 1) implement several representative centralized distributed optimization algorithms on UPMEM's real-world general-purpose PIM system, 2) rigorously evaluate these algorithms for ML training on large-scale datasets in terms of performance, accuracy, and scalability, 3) compare to conventional CPU and GPU baselines, and 4) discuss implications for future PIM hardware and the need to shift to an algorithm-hardware codesign perspective to accommodate decentralized distributed optimization algorithms. Our results demonstrate three major findings: 1) Modern general-purpose PIM architectures can be a viable alternative to state-of-the-art CPUs and GPUs for many memory-bound ML training workloads, when operations and datatypes are natively supported by PIM hardware, 2) the importance of carefully choosing the optimization algorithm that best fit PIM, and 3) contrary to popular belief, contemporary PIM architectures do not scale approximately linearly with the number of nodes for many data-intensive ML training workloads. To facilitate future research, we aim to open-source our complete codebase.
Read more4/11/2024
🧠
0
OPIMA: Optical Processing-In-Memory for Convolutional Neural Network Acceleration
Febin Sunny, Amin Shafiee, Abhishek Balasubramaniam, Mahdi Nikdast, Sudeep Pasricha
Recent advances in machine learning (ML) have spotlighted the pressing need for computing architectures that bridge the gap between memory bandwidth and processing power. The advent of deep neural networks has pushed traditional Von Neumann architectures to their limits due to the high latency and energy consumption costs associated with data movement between the processor and memory for these workloads. One of the solutions to overcome this bottleneck is to perform computation within the main memory through processing-in-memory (PIM), thereby limiting data movement and the costs associated with it. However, DRAM-based PIM struggles to achieve high throughput and energy efficiency due to internal data movement bottlenecks and the need for frequent refresh operations. In this work, we introduce OPIMA, a PIM-based ML accelerator, architected within an optical main memory. OPIMA has been designed to leverage the inherent massive parallelism within main memory while performing high-speed, low-energy optical computation to accelerate ML models based on convolutional neural networks. We present a comprehensive analysis of OPIMA to guide design choices and operational mechanisms. Additionally, we evaluate the performance and energy consumption of OPIMA, comparing it with conventional electronic computing systems and emerging photonic PIM architectures. The experimental results show that OPIMA can achieve 2.98x higher throughput and 137x better energy efficiency than the best-known prior work.
Read more7/12/2024

0
UpDLRM: Accelerating Personalized Recommendation using Real-World PIM Architecture
Sitian Chen, Haobin Tan, Amelie Chi Zhou, Yusen Li, Pavan Balaji
Deep Learning Recommendation Models (DLRMs) have gained popularity in recommendation systems due to their effectiveness in handling large-scale recommendation tasks. The embedding layers of DLRMs have become the performance bottleneck due to their intensive needs on memory capacity and memory bandwidth. In this paper, we propose UpDLRM, which utilizes real-world processingin-memory (PIM) hardware, UPMEM DPU, to boost the memory bandwidth and reduce recommendation latency. The parallel nature of the DPU memory can provide high aggregated bandwidth for the large number of irregular memory accesses in embedding lookups, thus offering great potential to reduce the inference latency. To fully utilize the DPU memory bandwidth, we further studied the embedding table partitioning problem to achieve good workload-balance and efficient data caching. Evaluations using real-world datasets show that, UpDLRM achieves much lower inference time for DLRM compared to both CPU-only and CPU-GPU hybrid counterparts.
Read more6/21/2024