Collapse-Aware Triplet Decoupling for Adversarially Robust Image Retrieval

0

Sign in to get full access
Overview
- This paper proposes a novel approach called "Collapse-Oriented Adversarial Training with Triplet Decoupling" to improve the robustness of image retrieval models.
- The method aims to make image embeddings more resilient to adversarial attacks by training the model to learn a more compact and discriminative feature representation.
- The key innovation is the use of triplet decoupling, which separates the triplet loss into two components to better capture the intra-class and inter-class variations.
Plain English Explanation
Image retrieval is the task of finding visually similar images from a large database given a query image. However, these models can be vulnerable to adversarial attacks, where small imperceptible changes to the input image can cause the model to misidentify it.
The Collapse-Oriented Adversarial Training with Triplet Decoupling for Robust Image Retrieval paper proposes a new way to train image retrieval models to be more robust against such attacks. The key idea is to learn a more compact and discriminative feature representation for the images.
Typically, image retrieval models are trained using a triplet loss, which encourages the model to place images of the same class (e.g., the same object) closer together in the feature space, and images of different classes farther apart. The Collapse-Oriented Adversarial Training method takes this a step further by explicitly training the model to make the feature representations of images within the same class even more tightly clustered ("collapsed").
At the same time, the Triplet Decoupling technique is used to separate the triplet loss into two components: one that focuses on the intra-class variations (differences within the same class) and one that focuses on the inter-class variations (differences between classes). This allows the model to better capture the nuances of the feature representations.
The result is a more robust image retrieval model that is less susceptible to adversarial attacks, while still maintaining good performance on standard retrieval tasks.
Technical Explanation
The paper proposes a Collapse-Oriented Adversarial Training (COAT) method that trains the image retrieval model to learn a more compact and discriminative feature representation. This is achieved by modifying the triplet loss function used to train the model.
Typically, the triplet loss encourages the model to place images of the same class (e.g., the same object) closer together in the feature space, and images of different classes farther apart. The COAT method takes this a step further by explicitly training the model to make the feature representations of images within the same class even more tightly clustered ("collapsed").
Additionally, the paper introduces a Triplet Decoupling (TD) technique, which separates the triplet loss into two components: one that focuses on the intra-class variations (differences within the same class) and one that focuses on the inter-class variations (differences between classes). This allows the model to better capture the nuances of the feature representations.
The overall training process involves alternating between standard triplet training and the COAT method, which gradually pushes the feature representations to be more compact and discriminative. The authors demonstrate the effectiveness of their approach through extensive experiments on several image retrieval benchmarks, showing improved robustness against adversarial attacks while maintaining high retrieval performance.
Critical Analysis
The paper presents a well-designed and thorough study, with a clear motivation and a novel approach to improving the robustness of image retrieval models. The authors have considered relevant prior work and have made a convincing case for the benefits of their Collapse-Oriented Adversarial Training with Triplet Decoupling method.
One potential limitation of the approach is that it may not be as effective in scenarios where the intra-class variations are already very small, as the "collapse" aspect of the training might not provide substantial additional benefits. Additionally, the paper does not explore the trade-offs between the degree of collapse and the overall retrieval performance, which could be an interesting area for further investigation.
Another aspect that could be addressed in future research is the generalization of the method to other types of visual tasks beyond image retrieval, such as object detection or multimodal affective analysis. Exploring how the collapse-oriented and triplet decoupling principles could be applied to these domains could further demonstrate the broader applicability of the proposed techniques.
Conclusion
The Collapse-Oriented Adversarial Training with Triplet Decoupling for Robust Image Retrieval paper presents a novel approach to improving the robustness of image retrieval models against adversarial attacks. By training the model to learn a more compact and discriminative feature representation using a collapse-oriented triplet loss and triplet decoupling, the authors demonstrate significant improvements in the model's ability to withstand adversarial perturbations while maintaining high retrieval performance.
This research has important implications for the development of reliable and secure image retrieval systems, which are crucial for a wide range of applications, from content-based image search to visual recognition tasks. The proposed techniques could potentially be extended to other visual domains, further expanding the impact of this work on the field of computer vision and machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Collapse-Aware Triplet Decoupling for Adversarially Robust Image Retrieval
Qiwei Tian, Chenhao Lin, Zhengyu Zhao, Qian Li, Chao Shen
Adversarial training has achieved substantial performance in defending image retrieval against adversarial examples. However, existing studies in deep metric learning (DML) still suffer from two major limitations: weak adversary and model collapse. In this paper, we address these two limitations by proposing Collapse-Aware TRIplet DEcoupling (CA-TRIDE). Specifically, TRIDE yields a stronger adversary by spatially decoupling the perturbation targets into the anchor and the other candidates. Furthermore, CA prevents the consequential model collapse, based on a novel metric, collapseness, which is incorporated into the optimization of perturbation. We also identify two drawbacks of the existing robustness metric in image retrieval and propose a new metric for a more reasonable robustness evaluation. Extensive experiments on three datasets demonstrate that CA-TRIDE outperforms existing defense methods in both conventional and new metrics. Codes are available at https://github.com/michaeltian108/CA-TRIDE.
Read more6/7/2024
0
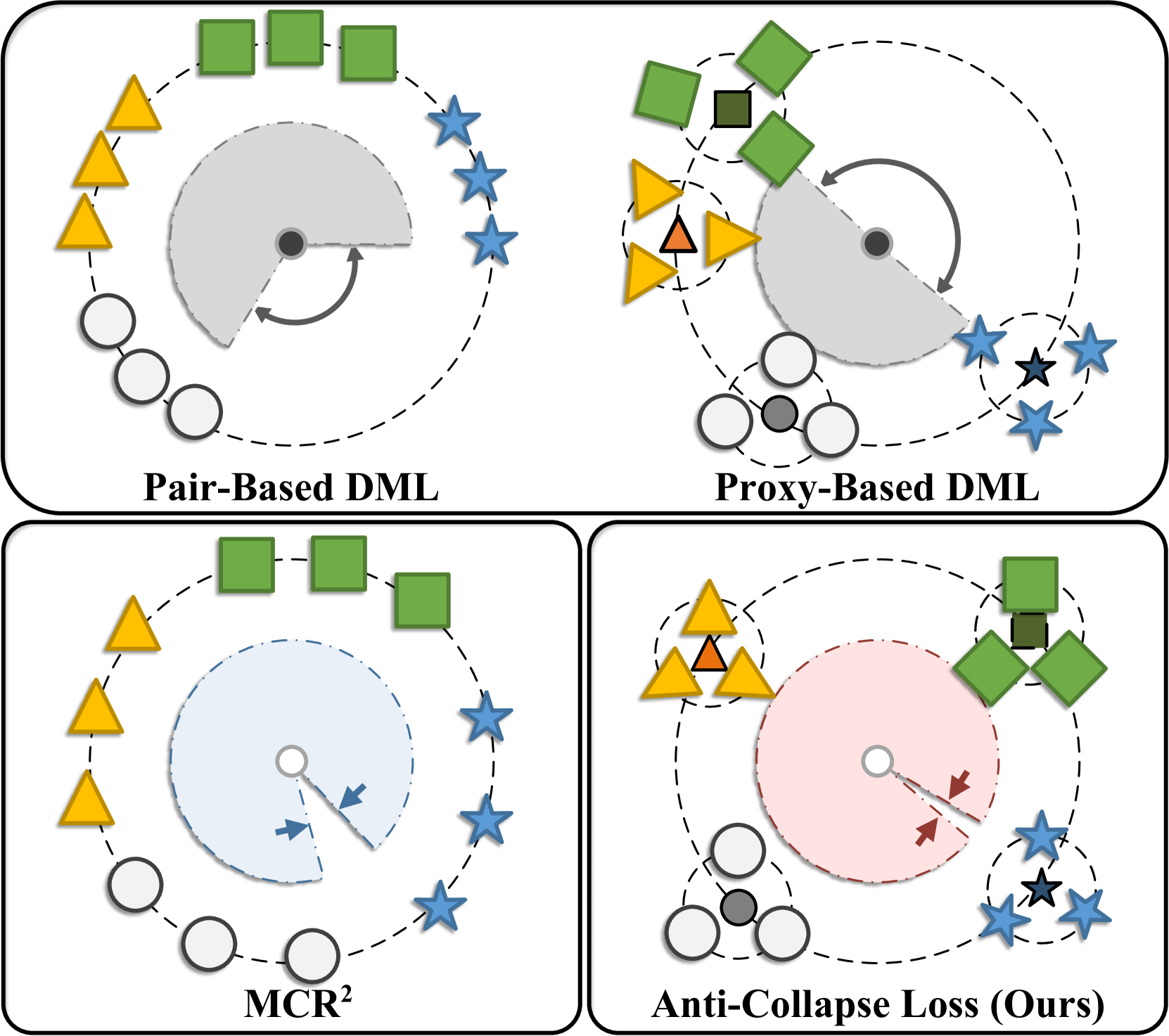
Anti-Collapse Loss for Deep Metric Learning Based on Coding Rate Metric
Xiruo Jiang, Yazhou Yao, Xili Dai, Fumin Shen, Xian-Sheng Hua, Heng-Tao Shen
Deep metric learning (DML) aims to learn a discriminative high-dimensional embedding space for downstream tasks like classification, clustering, and retrieval. Prior literature predominantly focuses on pair-based and proxy-based methods to maximize inter-class discrepancy and minimize intra-class diversity. However, these methods tend to suffer from the collapse of the embedding space due to their over-reliance on label information. This leads to sub-optimal feature representation and inferior model performance. To maintain the structure of embedding space and avoid feature collapse, we propose a novel loss function called Anti-Collapse Loss. Specifically, our proposed loss primarily draws inspiration from the principle of Maximal Coding Rate Reduction. It promotes the sparseness of feature clusters in the embedding space to prevent collapse by maximizing the average coding rate of sample features or class proxies. Moreover, we integrate our proposed loss with pair-based and proxy-based methods, resulting in notable performance improvement. Comprehensive experiments on benchmark datasets demonstrate that our proposed method outperforms existing state-of-the-art methods. Extensive ablation studies verify the effectiveness of our method in preventing embedding space collapse and promoting generalization performance.
Read more7/4/2024

0
Pseudo-triplet Guided Few-shot Composed Image Retrieval
Bohan Hou, Haoqiang Lin, Haokun Wen, Meng Liu, Xuemeng Song
Composed Image Retrieval (CIR) is a challenging task that aims to retrieve the target image based on a multimodal query, i.e., a reference image and its corresponding modification text. While previous supervised or zero-shot learning paradigms all fail to strike a good trade-off between time-consuming annotation cost and retrieval performance, recent researchers introduced the task of few-shot CIR (FS-CIR) and proposed a textual inversion-based network based on pretrained CLIP model to realize it. Despite its promising performance, the approach suffers from two key limitations: insufficient multimodal query composition training and indiscriminative training triplet selection. To address these two limitations, in this work, we propose a novel two-stage pseudo triplet guided few-shot CIR scheme, dubbed PTG-FSCIR. In the first stage, we employ a masked training strategy and advanced image caption generator to construct pseudo triplets from pure image data to enable the model to acquire primary knowledge related to multimodal query composition. In the second stage, based on active learning, we design a pseudo modification text-based query-target distance metric to evaluate the challenging score for each unlabeled sample. Meanwhile, we propose a robust top range-based random sampling strategy according to the 3-$sigma$ rule in statistics, to sample the challenging samples for fine-tuning the pretrained model. Notably, our scheme is plug-and-play and compatible with any existing supervised CIR models. We tested our scheme across three backbones on three public datasets (i.e., FashionIQ, CIRR, and Birds-to-Words), achieving maximum improvements of 26.4%, 25.5% and 21.6% respectively, demonstrating our scheme's effectiveness.
Read more7/9/2024
0
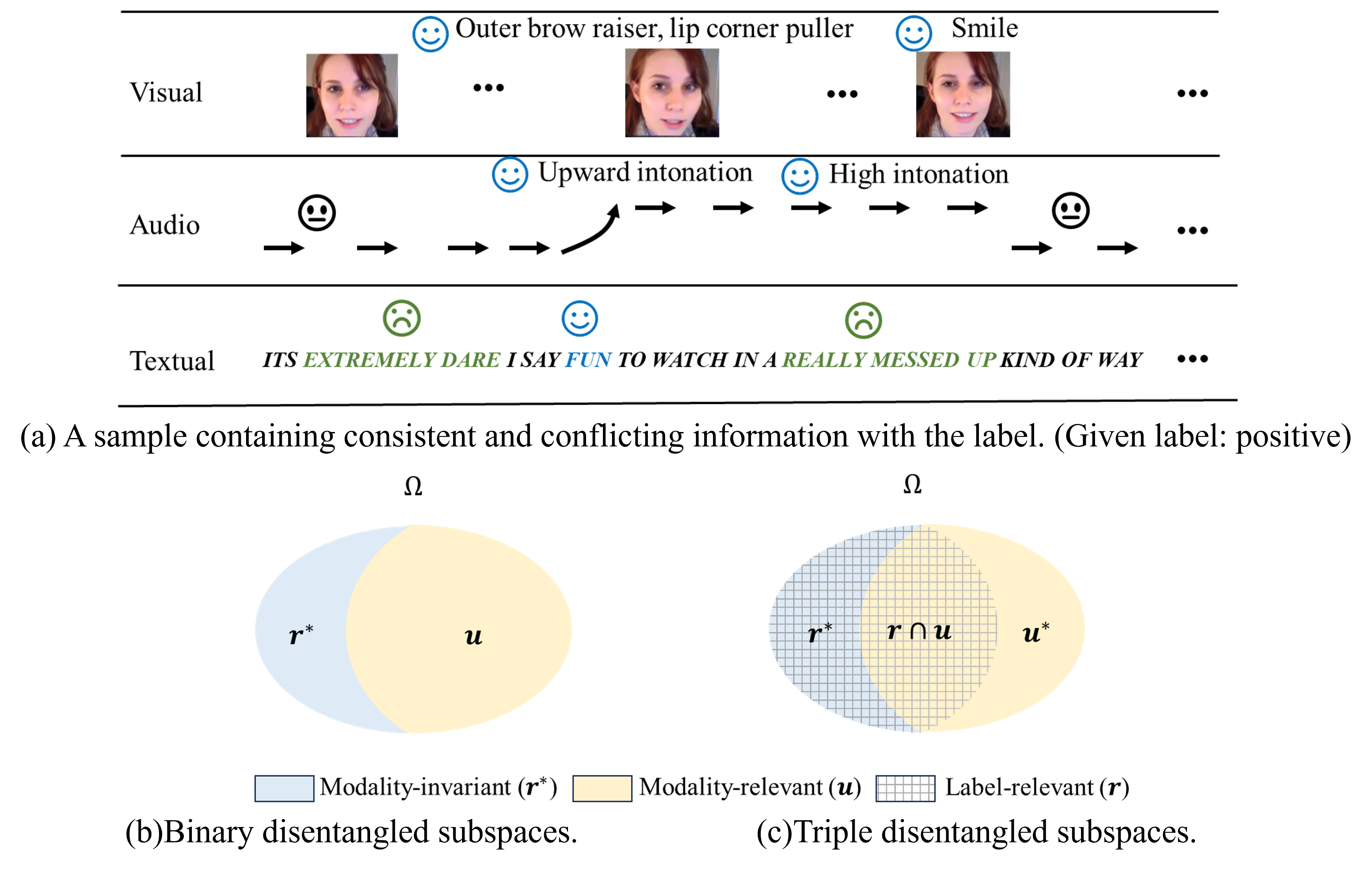
Triple Disentangled Representation Learning for Multimodal Affective Analysis
Ying Zhou, Xuefeng Liang, Han Chen, Yin Zhao, Xin Chen, Lida Yu
Multimodal learning has exhibited a significant advantage in affective analysis tasks owing to the comprehensive information of various modalities, particularly the complementary information. Thus, many emerging studies focus on disentangling the modality-invariant and modality-specific representations from input data and then fusing them for prediction. However, our study shows that modality-specific representations may contain information that is irrelevant or conflicting with the tasks, which downgrades the effectiveness of learned multimodal representations. We revisit the disentanglement issue, and propose a novel triple disentanglement approach, TriDiRA, which disentangles the modality-invariant, effective modality-specific and ineffective modality-specific representations from input data. By fusing only the modality-invariant and effective modality-specific representations, TriDiRA can significantly alleviate the impact of irrelevant and conflicting information across modalities during model training. Extensive experiments conducted on four benchmark datasets demonstrate the effectiveness and generalization of our triple disentanglement, which outperforms SOTA methods.
Read more4/9/2024