Triple Disentangled Representation Learning for Multimodal Affective Analysis
2401.16119
0
1
Abstract
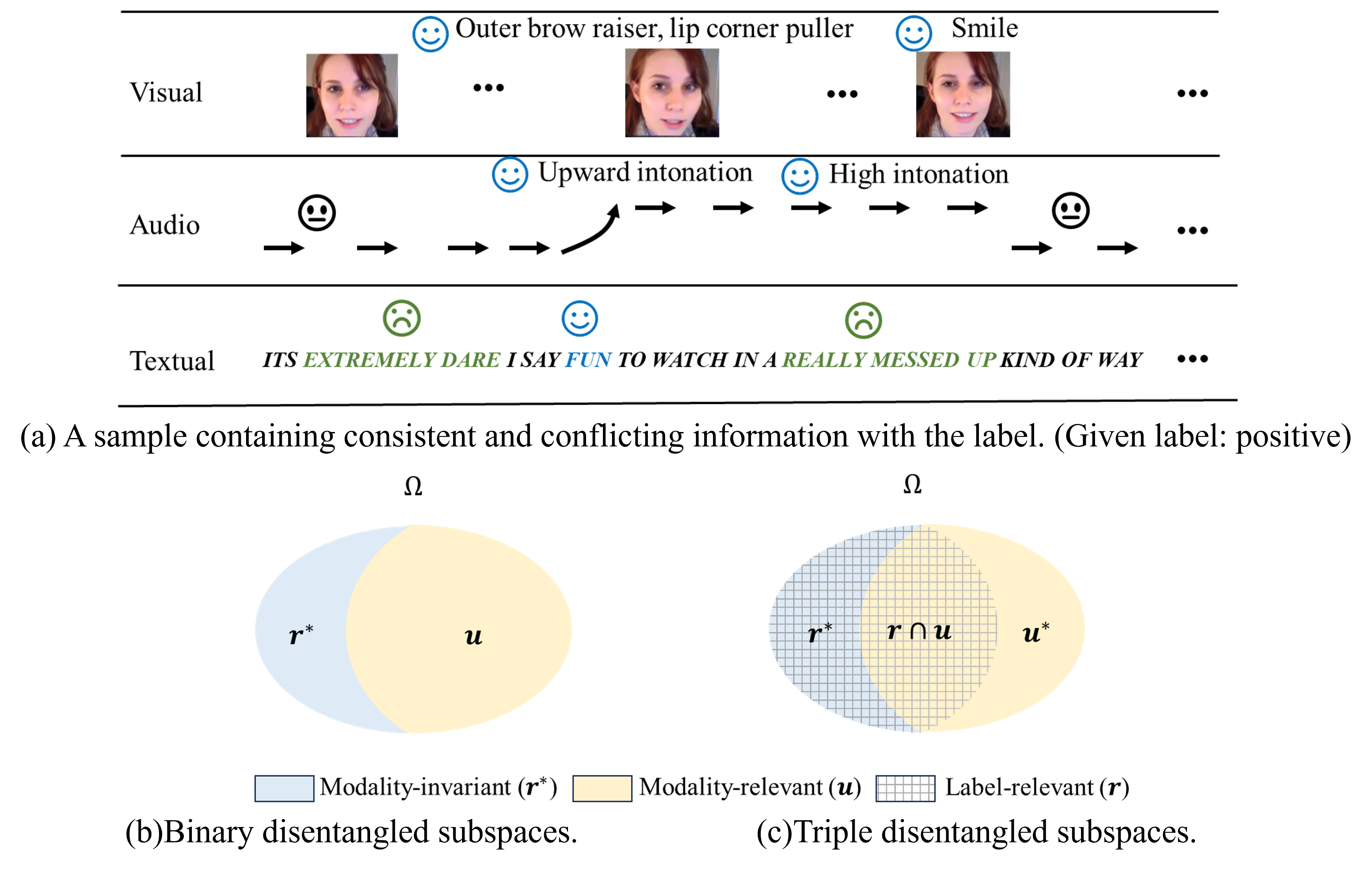
Multimodal learning has exhibited a significant advantage in affective analysis tasks owing to the comprehensive information of various modalities, particularly the complementary information. Thus, many emerging studies focus on disentangling the modality-invariant and modality-specific representations from input data and then fusing them for prediction. However, our study shows that modality-specific representations may contain information that is irrelevant or conflicting with the tasks, which downgrades the effectiveness of learned multimodal representations. We revisit the disentanglement issue, and propose a novel triple disentanglement approach, TriDiRA, which disentangles the modality-invariant, effective modality-specific and ineffective modality-specific representations from input data. By fusing only the modality-invariant and effective modality-specific representations, TriDiRA can significantly alleviate the impact of irrelevant and conflicting information across modalities during model training. Extensive experiments conducted on four benchmark datasets demonstrate the effectiveness and generalization of our triple disentanglement, which outperforms SOTA methods.
Create account to get full access
Overview
- This paper presents a method for learning a triple disentangled representation of multimodal affective data, such as facial expressions, body language, and speech.
- The goal is to separate the representations into three factors: emotion, identity, and environment, which can then be used for various multimodal affective analysis tasks.
- The authors propose a novel deep learning architecture and training procedure to achieve this disentanglement, and evaluate the approach on several multimodal emotion recognition benchmarks.
Plain English Explanation
The paper describes a way to break down information from different types of data, like facial expressions, body movements, and speech, into three separate factors: emotion, identity, and environment. This process of separating different aspects of data is called "disentanglement." The researchers developed a new deep learning model and training method to do this. They then tested their approach on standard datasets used for recognizing emotions from multimodal data. The key idea is that separating the data into these three factors could be useful for various applications that involve understanding human emotions and behavior from different types of sensor inputs.
Technical Explanation
The authors propose a "Triple Disentangled Representation Learning" (TDRL) framework for multimodal affective analysis. The goal is to learn representations that disentangle emotion, identity, and environment factors from multimodal data like facial expressions, body language, and speech. They design a deep neural network architecture with three separate encoding streams to capture these three factors, along with reconstruction and adversarial losses to enforce the disentanglement.
The model is trained end-to-end on multimodal emotion recognition datasets. Experiments show that the disentangled representations improve performance on emotion classification, as well as enabling other applications like identity-invariant emotion analysis and environment-aware emotion prediction. The authors also demonstrate the interpretability of the learned representations through visualization and ablation studies.
Critical Analysis
The paper presents a novel and promising approach for learning disentangled multimodal representations for affective analysis. However, the evaluation is limited to standard emotion recognition benchmarks, and more work is needed to fully demonstrate the practical benefits of the disentangled representations across a broader range of real-world applications.
Additionally, the training procedure relies on adversarial losses, which can be unstable and challenging to optimize in practice. The authors also do not provide a detailed analysis of the learned representations or the factors that the model is actually capturing, which would be important for understanding the strengths and limitations of the approach.
Conclusion
This paper introduces an interesting framework for learning triple-disentangled representations from multimodal affective data. The ability to separate emotion, identity, and environment factors could enable more robust and interpretable models for a variety of applications in human-centric computing and affective analysis. While further research is needed to fully realize the potential of this approach, it represents an important step towards teaching large language models to better interpret and reason about multimodal human behavior and experiences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
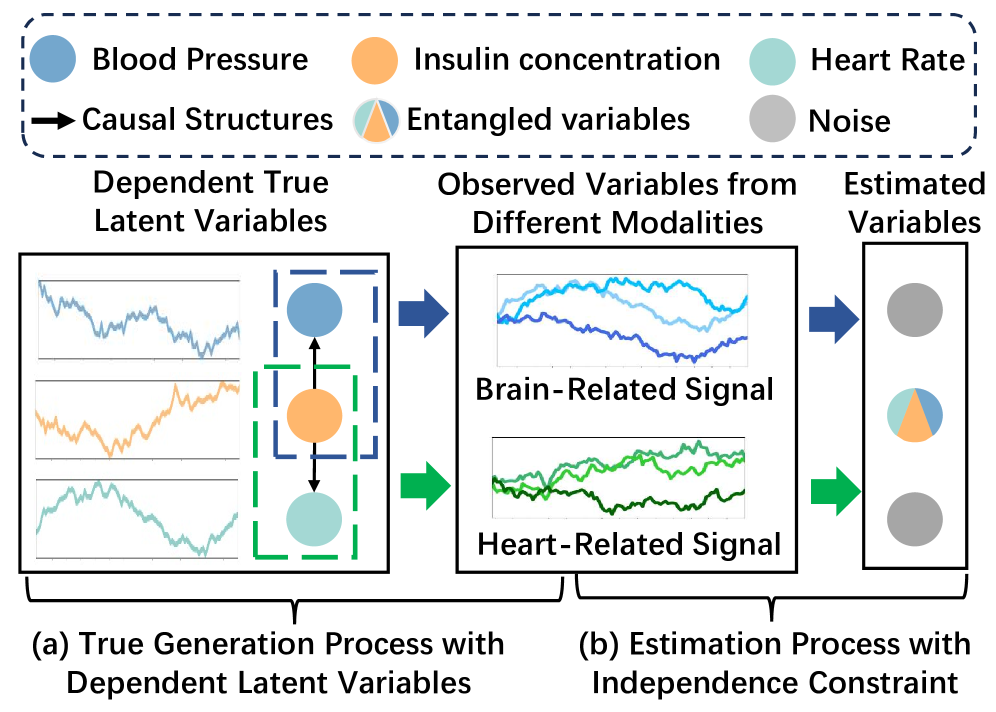
From Orthogonality to Dependency: Learning Disentangled Representation for Multi-Modal Time-Series Sensing Signals
Ruichu Cai, Zhifang Jiang, Zijian Li, Weilin Chen, Xuexin Chen, Zhifeng Hao, Yifan Shen, Guangyi Chen, Kun Zhang
0
0
Existing methods for multi-modal time series representation learning aim to disentangle the modality-shared and modality-specific latent variables. Although achieving notable performances on downstream tasks, they usually assume an orthogonal latent space. However, the modality-specific and modality-shared latent variables might be dependent on real-world scenarios. Therefore, we propose a general generation process, where the modality-shared and modality-specific latent variables are dependent, and further develop a textbf{M}ulti-modtextbf{A}l textbf{TE}mporal Disentanglement (textbf{MATE}) model. Specifically, our textbf{MATE} model is built on a temporally variational inference architecture with the modality-shared and modality-specific prior networks for the disentanglement of latent variables. Furthermore, we establish identifiability results to show that the extracted representation is disentangled. More specifically, we first achieve the subspace identifiability for modality-shared and modality-specific latent variables by leveraging the pairing of multi-modal data. Then we establish the component-wise identifiability of modality-specific latent variables by employing sufficient changes of historical latent variables. Extensive experimental studies on multi-modal sensors, human activity recognition, and healthcare datasets show a general improvement in different downstream tasks, highlighting the effectiveness of our method in real-world scenarios.
5/28/2024
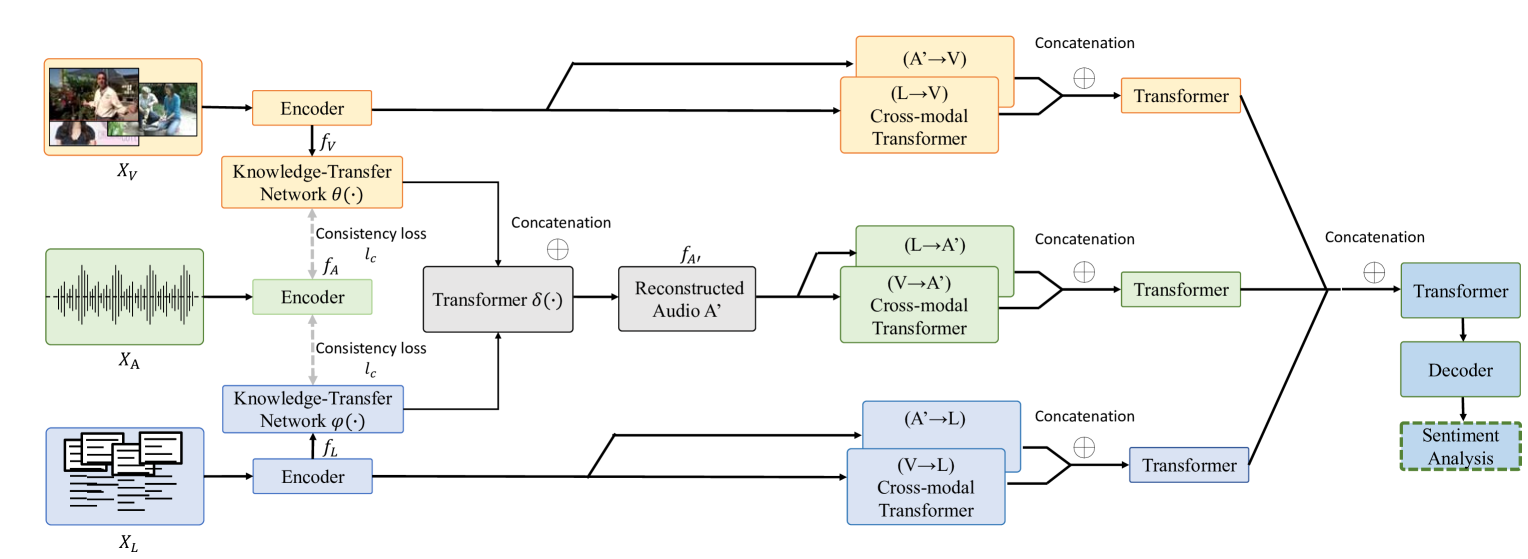
Multimodal Sentiment Analysis with Missing Modality: A Knowledge-Transfer Approach
Weide Liu, Huijing Zhan, Hao Chen, Fengmao Lv
0
0
Multimodal sentiment analysis aims to identify the emotions expressed by individuals through visual, language, and acoustic cues. However, most of the existing research efforts assume that all modalities are available during both training and testing, making their algorithms susceptible to the missing modality scenario. In this paper, we propose a novel knowledge-transfer network to translate between different modalities to reconstruct the missing audio modalities. Moreover, we develop a cross-modality attention mechanism to retain the maximal information of the reconstructed and observed modalities for sentiment prediction. Extensive experiments on three publicly available datasets demonstrate significant improvements over baselines and achieve comparable results to the previous methods with complete multi-modality supervision.
6/21/2024

TripletMix: Triplet Data Augmentation for 3D Understanding
Jiaze Wang, Yi Wang, Ziyu Guo, Renrui Zhang, Donghao Zhou, Guangyong Chen, Anfeng Liu, Pheng-Ann Heng
0
0
Data augmentation has proven to be a vital tool for enhancing the generalization capabilities of deep learning models, especially in the context of 3D vision where traditional datasets are often limited. Despite previous advancements, existing methods primarily cater to unimodal data scenarios, leaving a gap in the augmentation of multimodal triplet data, which integrates text, images, and point clouds. Simultaneously augmenting all three modalities enhances diversity and improves alignment across modalities, resulting in more comprehensive and robust 3D representations. To address this gap, we propose TripletMix, a novel approach to address the previously unexplored issue of multimodal data augmentation in 3D understanding. TripletMix innovatively applies the principles of mixed-based augmentation to multimodal triplet data, allowing for the preservation and optimization of cross-modal connections. Our proposed TripletMix combines feature-level and input-level augmentations to achieve dual enhancement between raw data and latent features, significantly improving the model's cross-modal understanding and generalization capabilities by ensuring feature consistency and providing diverse and realistic training samples. We demonstrate that TripletMix not only improves the baseline performance of models in various learning scenarios including zero-shot and linear probing classification but also significantly enhances model generalizability. Notably, we improved the zero-shot classification accuracy on ScanObjectNN from 51.3 percent to 61.9 percent, and on Objaverse-LVIS from 46.8 percent to 51.4 percent. Our findings highlight the potential of multimodal data augmentation to significantly advance 3D object recognition and understanding.
5/30/2024
🌿
Mutual Information Analysis in Multimodal Learning Systems
Hadi Hadizadeh, S. Faegheh Yeganli, Bahador Rashidi, Ivan V. Baji'c
0
0
In recent years, there has been a significant increase in applications of multimodal signal processing and analysis, largely driven by the increased availability of multimodal datasets and the rapid progress in multimodal learning systems. Well-known examples include autonomous vehicles, audiovisual generative systems, vision-language systems, and so on. Such systems integrate multiple signal modalities: text, speech, images, video, LiDAR, etc., to perform various tasks. A key issue for understanding such systems is the relationship between various modalities and how it impacts task performance. In this paper, we employ the concept of mutual information (MI) to gain insight into this issue. Taking advantage of the recent progress in entropy modeling and estimation, we develop a system called InfoMeter to estimate MI between modalities in a multimodal learning system. We then apply InfoMeter to analyze a multimodal 3D object detection system over a large-scale dataset for autonomous driving. Our experiments on this system suggest that a lower MI between modalities is beneficial for detection accuracy. This new insight may facilitate improvements in the development of future multimodal learning systems.
5/22/2024