Combining Experimental and Historical Data for Policy Evaluation
2406.00317
0
0
Abstract
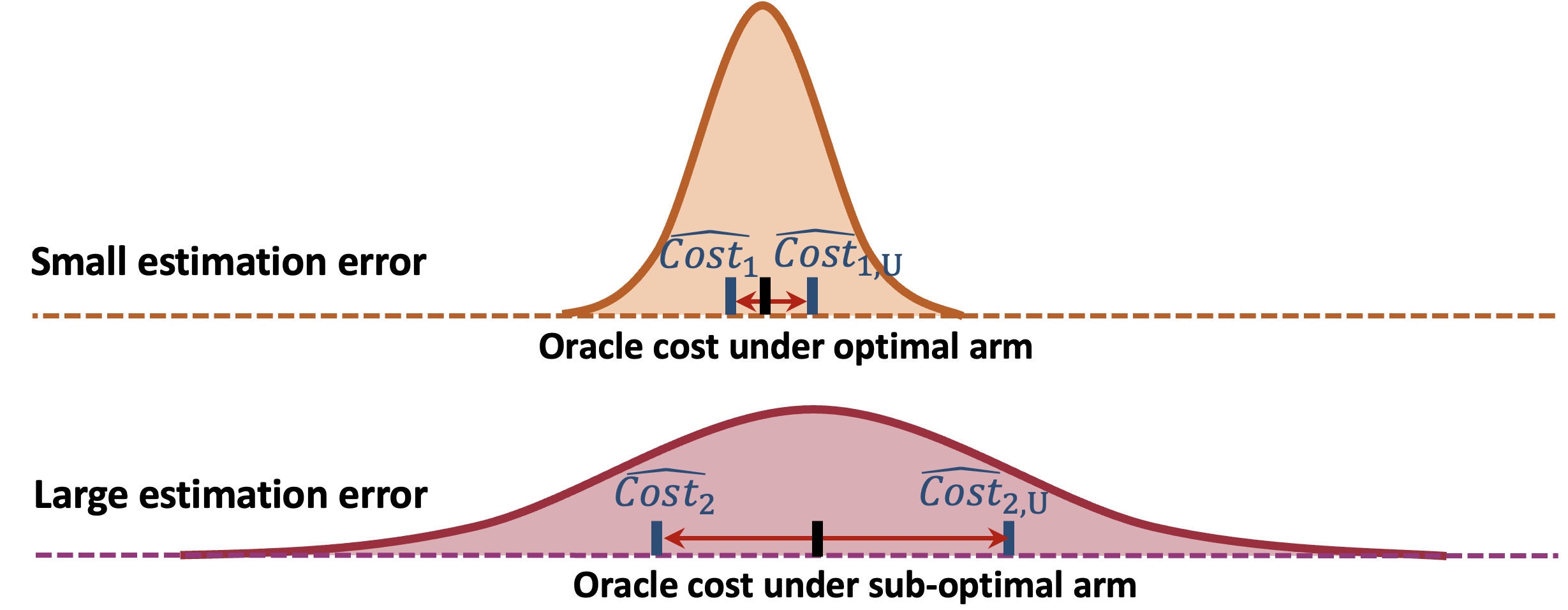
This paper studies policy evaluation with multiple data sources, especially in scenarios that involve one experimental dataset with two arms, complemented by a historical dataset generated under a single control arm. We propose novel data integration methods that linearly integrate base policy value estimators constructed based on the experimental and historical data, with weights optimized to minimize the mean square error (MSE) of the resulting combined estimator. We further apply the pessimistic principle to obtain more robust estimators, and extend these developments to sequential decision making. Theoretically, we establish non-asymptotic error bounds for the MSEs of our proposed estimators, and derive their oracle, efficiency and robustness properties across a broad spectrum of reward shift scenarios. Numerical experiments and real-data-based analyses from a ridesharing company demonstrate the superior performance of the proposed estimators.
Create account to get full access
Overview
- This paper explores a method for combining experimental and historical data to evaluate the effectiveness of different policies.
- The key ideas are to leverage both randomized controlled trial (RCT) data and observational data to improve policy evaluation.
- The authors propose a novel statistical approach that can handle the challenges of combining these different data sources.
Plain English Explanation
The paper is about a way to use both experimental data and historical data to figure out how well different policies or programs work. Experimental data comes from carefully controlled studies, like randomized controlled trials (RCTs), where people are randomly assigned to different groups to test the effects of a policy. Historical data is information that has been collected over time, often from people's regular activities, without the strict controls of an experiment.
The researchers realized that using both of these data sources together could give a more complete picture of how effective a policy is. RCT data provides clear evidence of the direct effects of a policy, but it can be expensive and time-consuming to collect. Historical data, on the other hand, is often easier to access, but it can be harder to determine the true impact of a policy because there are many other factors involved.
The key innovation in this paper is a new statistical approach that can combine these two very different types of data in a way that provides a more accurate and reliable assessment of policy effectiveness. This could be especially helpful for policymakers and program managers who need to make decisions about which policies or interventions to implement, but don't have the resources to conduct a full RCT.
Technical Explanation
The paper proposes a novel approach to off-policy evaluation that leverages both experimental (RCT) data and observational (historical) data. The key innovation is a statistical framework that can handle the different characteristics and biases inherent in these two data sources.
The authors start by defining a general problem setup where there is a set of policies (or actions) that can be taken, and the goal is to evaluate the effects of these policies on some outcome of interest. The RCT data provides a clean causal estimate of the effect of a specific policy, but it may be limited in scope or sample size. The observational data, on the other hand, can provide a richer, more diverse set of policy experiences, but suffers from potential confounding and selection bias.
The proposed approach combines these data sources using a "doubly robust" estimator that blends the strengths of both. This involves modeling the outcome of interest as a function of the policy choice and other observed covariates, as well as modeling the propensity of individuals to receive each policy. By using these two models in a carefully constructed way, the estimator is able to provide consistent estimates of policy effects even when one of the models is misspecified.
The authors demonstrate the effectiveness of their approach through both theoretical analysis and extensive simulations. They show that the method can outperform alternatives that rely solely on either experimental or observational data, especially when the two data sources have different strengths and weaknesses.
Critical Analysis
The paper makes a compelling case for the value of combining experimental and observational data for policy evaluation. The proposed statistical framework is technically sound and the simulation results are promising. However, there are a few potential limitations and areas for further research:
-
Generalizability: The paper focuses on a fairly general problem setup, but the specific modeling assumptions and data requirements may limit the real-world applicability in certain domains. Further research is needed to understand how the method performs with different types of policies, outcomes, and data structures.
-
Practical Implementation: While the theoretical framework is well-developed, the paper does not provide much guidance on the practical implementation of the method. Aspects like feature engineering, model selection, and hyperparameter tuning could be challenging in practice and would benefit from more detailed discussion.
-
Causal Identification: The paper relies on the standard unconfoundedness assumption for causal identification. In some settings, this may be a strong assumption, and alternative approaches, such as instrumental variables, may be needed to overcome issues of unobserved confounding.
-
Ethical Considerations: The paper does not address the potential ethical implications of using combined experimental and observational data for policy evaluation. Issues around privacy, data bias, and the fairness of policy decisions should be carefully considered.
Overall, the paper presents a promising methodological advance in the field of policy evaluation. With further research and practical validation, the proposed approach could become a valuable tool for policymakers and program managers.
Conclusion
This paper introduces a novel statistical framework for combining experimental and observational data to evaluate the effectiveness of different policies. The key innovation is a "doubly robust" estimator that can leverage the strengths of both data sources to provide more accurate and reliable estimates of policy impacts.
The proposed method has the potential to significantly improve policy evaluation, especially in situations where conducting a full randomized controlled trial may be infeasible or prohibitively expensive. By incorporating both experimental and historical data, policymakers can make more informed decisions about which interventions to implement, ultimately leading to better outcomes for the populations they serve.
While the paper presents a strong theoretical foundation and promising simulation results, further research is needed to address practical implementation challenges and potential ethical concerns. Nevertheless, this work represents an important step forward in the field of causal inference and policy evaluation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

A Double Machine Learning Approach to Combining Experimental and Observational Data
Harsh Parikh, Marco Morucci, Vittorio Orlandi, Sudeepa Roy, Cynthia Rudin, Alexander Volfovsky
0
0
Experimental and observational studies often lack validity due to untestable assumptions. We propose a double machine learning approach to combine experimental and observational studies, allowing practitioners to test for assumption violations and estimate treatment effects consistently. Our framework tests for violations of external validity and ignorability under milder assumptions. When only one of these assumptions is violated, we provide semiparametrically efficient treatment effect estimators. However, our no-free-lunch theorem highlights the necessity of accurately identifying the violated assumption for consistent treatment effect estimation. Through comparative analyses, we show our framework's superiority over existing data fusion methods. The practical utility of our approach is further exemplified by three real-world case studies, underscoring its potential for widespread application in empirical research.
4/4/2024
📊
Beyond IID: data-driven decision-making in heterogeneous environments
Omar Besbes, Will Ma, Omar Mouchtaki
0
0
How should one leverage historical data when past observations are not perfectly indicative of the future, e.g., due to the presence of unobserved confounders which one cannot correct for? Motivated by this question, we study a data-driven decision-making framework in which historical samples are generated from unknown and different distributions assumed to lie in a heterogeneity ball with known radius and centered around the (also) unknown future (out-of-sample) distribution on which the performance of a decision will be evaluated. This work aims at analyzing the performance of central data-driven policies but also near-optimal ones in these heterogeneous environments and understanding key drivers of performance. We establish a first result which allows to upper bound the asymptotic worst-case regret of a broad class of policies. Leveraging this result, for any integral probability metric, we provide a general analysis of the performance achieved by Sample Average Approximation (SAA) as a function of the radius of the heterogeneity ball. This analysis is centered around the approximation parameter, a notion of complexity we introduce to capture how the interplay between the heterogeneity and the problem structure impacts the performance of SAA. In turn, we illustrate through several widely-studied problems -- e.g., newsvendor, pricing -- how this methodology can be applied and find that the performance of SAA varies considerably depending on the combinations of problem classes and heterogeneity. The failure of SAA for certain instances motivates the design of alternative policies to achieve rate-optimality. We derive problem-dependent policies achieving strong guarantees for the illustrative problems described above and provide initial results towards a principled approach for the design and analysis of general rate-optimal algorithms.
6/21/2024
🌀
Data-Driven Switchback Experiments: Theoretical Tradeoffs and Empirical Bayes Designs
Ruoxuan Xiong, Alex Chin, Sean J. Taylor
0
0
We study the design and analysis of switchback experiments conducted on a single aggregate unit. The design problem is to partition the continuous time space into intervals and switch treatments between intervals, in order to minimize the estimation error of the treatment effect. We show that the estimation error depends on four factors: carryover effects, periodicity, serially correlated outcomes, and impacts from simultaneous experiments. We derive a rigorous bias-variance decomposition and show the tradeoffs of the estimation error from these factors. The decomposition provides three new insights in choosing a design: First, balancing the periodicity between treated and control intervals reduces the variance; second, switching less frequently reduces the bias from carryover effects while increasing the variance from correlated outcomes, and vice versa; third, randomizing interval start and end points reduces both bias and variance from simultaneous experiments. Combining these insights, we propose a new empirical Bayes design approach. This approach uses prior data and experiments for designing future experiments. We illustrate this approach using real data from a ride-sharing platform, yielding a design that reduces MSE by 33% compared to the status quo design used on the platform.
6/12/2024
📊
Efficient Policy Evaluation with Offline Data Informed Behavior Policy Design
Shuze Liu, Shangtong Zhang
0
0
Most reinforcement learning practitioners evaluate their policies with online Monte Carlo estimators for either hyperparameter tuning or testing different algorithmic design choices, where the policy is repeatedly executed in the environment to get the average outcome. Such massive interactions with the environment are prohibitive in many scenarios. In this paper, we propose novel methods that improve the data efficiency of online Monte Carlo estimators while maintaining their unbiasedness. We first propose a tailored closed-form behavior policy that provably reduces the variance of an online Monte Carlo estimator. We then design efficient algorithms to learn this closed-form behavior policy from previously collected offline data. Theoretical analysis is provided to characterize how the behavior policy learning error affects the amount of reduced variance. Compared with previous works, our method achieves better empirical performance in a broader set of environments, with fewer requirements for offline data.
6/3/2024