A Double Machine Learning Approach to Combining Experimental and Observational Data
2307.01449
0
0

Abstract
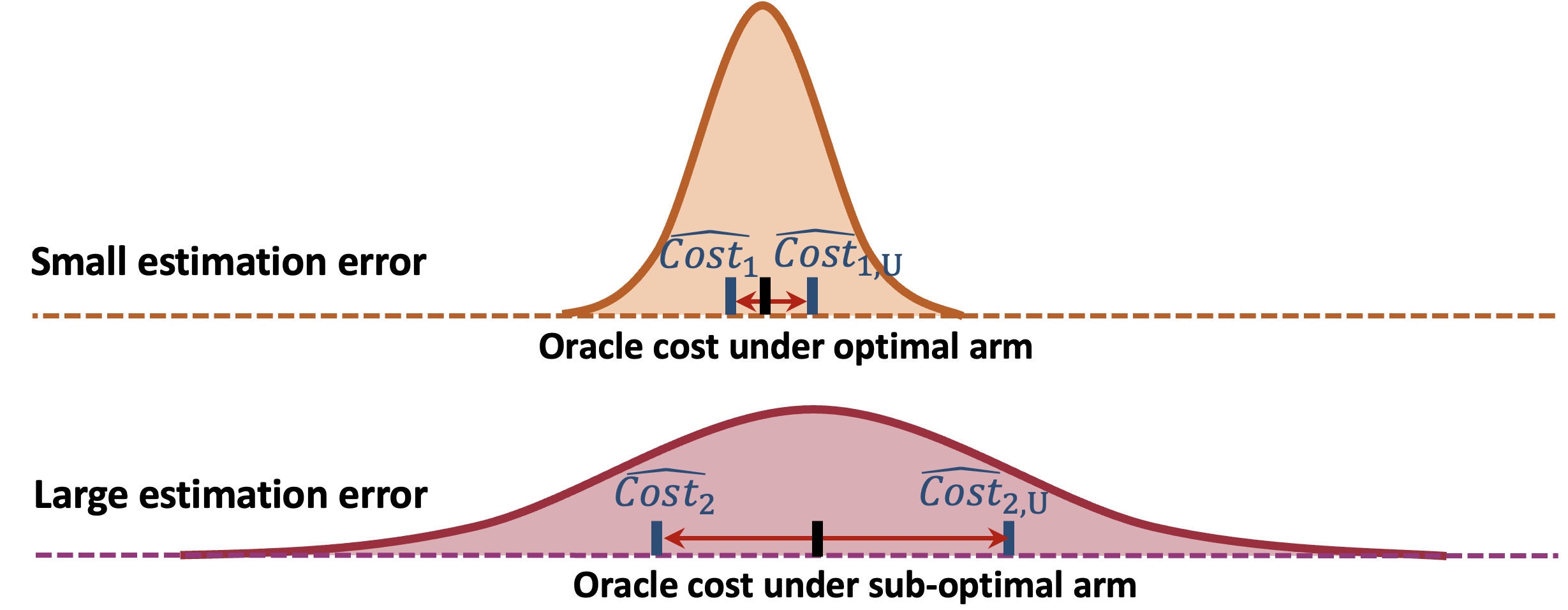
Experimental and observational studies often lack validity due to untestable assumptions. We propose a double machine learning approach to combine experimental and observational studies, allowing practitioners to test for assumption violations and estimate treatment effects consistently. Our framework tests for violations of external validity and ignorability under milder assumptions. When only one of these assumptions is violated, we provide semiparametrically efficient treatment effect estimators. However, our no-free-lunch theorem highlights the necessity of accurately identifying the violated assumption for consistent treatment effect estimation. Through comparative analyses, we show our framework's superiority over existing data fusion methods. The practical utility of our approach is further exemplified by three real-world case studies, underscoring its potential for widespread application in empirical research.
Create account to get full access
Overview
- This paper proposes a "double machine learning" approach to combining experimental and observational data to improve causal inference and policy evaluation.
- The key idea is to use machine learning models to leverage the strengths of both experimental and observational data, overcoming the limitations of each.
- The authors demonstrate the effectiveness of their approach through simulations and a real-world application in education policy.
Plain English Explanation
When researchers want to understand the effects of a policy or intervention, they often turn to either experimental or observational data. Experimental data comes from carefully designed studies where the intervention is randomly assigned, allowing for strong causal conclusions. However, experiments can be costly and difficult to conduct, especially for large-scale policies. Observational data, on the other hand, is readily available from various sources, but can be biased due to confounding factors that are hard to account for.
The authors of this paper propose a way to get the best of both worlds by combining experimental and observational data using machine learning. Their "double machine learning" approach involves training two models: one to predict the outcome of interest based on the observational data, and another to estimate the causal effect of the intervention. By integrating these models, the researchers can leverage the strengths of each type of data to make more accurate and reliable inferences about the impacts of a policy or intervention.
The authors demonstrate the effectiveness of their approach through simulations and a real-world application in education policy. Their results suggest that this method can lead to significant improvements in causal inference and policy evaluation, compared to using either experimental or observational data alone.
Technical Explanation
The key components of the authors' "double machine learning" approach are:
-
Outcome Model: A machine learning model trained to predict the outcome of interest (e.g., student test scores) based on the observational data. This model helps to account for confounding factors in the observational data.
-
Treatment Effect Model: A second machine learning model trained to estimate the causal effect of the intervention (e.g., a new education policy) on the outcome. This model leverages the experimental data to identify the true effect of the intervention, adjusting for biases in the observational data.
By integrating these two models, the authors can leverage the strengths of both experimental and observational data to make more accurate causal inferences and policy evaluations. The outcome model helps to improve the quality of the observational data, while the treatment effect model allows the researchers to estimate the causal effect of the intervention.
The authors demonstrate the effectiveness of their approach through a series of simulations and a real-world application in education policy. Their results show that the double machine learning method can lead to significant improvements in the accuracy of causal estimates, compared to using either experimental or observational data alone.
Critical Analysis
The authors acknowledge several limitations and areas for further research in their paper. One key limitation is the assumption that the observational data is "conditionally independent" of the intervention, meaning that all confounding factors have been accounted for. In practice, this assumption may be difficult to verify, and violations could lead to biased estimates.
Additionally, the authors' approach relies heavily on the quality and representativeness of the experimental and observational data. If the data is not well-matched or suffers from other issues, the double machine learning method may not be able to fully correct for the biases.
Further research could explore ways to relax the assumptions underlying the double machine learning approach, as well as investigate its performance in more complex real-world settings with multiple interventions or heterogeneous treatment effects.
Conclusion
This paper presents a novel "double machine learning" approach to combining experimental and observational data for improved causal inference and policy evaluation. By integrating two machine learning models – one to predict outcomes and another to estimate causal effects – the authors demonstrate the ability to leverage the strengths of both data sources to make more accurate and reliable inferences.
The implications of this work are significant, as it offers a promising way to enhance our understanding of the impacts of policies and interventions, even in situations where experimental data is limited or unavailable. As governments, organizations, and researchers continue to grapple with complex social and economic challenges, tools like the double machine learning approach could prove invaluable in informing evidence-based decision-making and driving positive change.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Estimating Causal Effects with Double Machine Learning -- A Method Evaluation
Jonathan Fuhr, Philipp Berens, Dominik Papies
0
0
The estimation of causal effects with observational data continues to be a very active research area. In recent years, researchers have developed new frameworks which use machine learning to relax classical assumptions necessary for the estimation of causal effects. In this paper, we review one of the most prominent methods - double/debiased machine learning (DML) - and empirically evaluate it by comparing its performance on simulated data relative to more traditional statistical methods, before applying it to real-world data. Our findings indicate that the application of a suitably flexible machine learning algorithm within DML improves the adjustment for various nonlinear confounding relationships. This advantage enables a departure from traditional functional form assumptions typically necessary in causal effect estimation. However, we demonstrate that the method continues to critically depend on standard assumptions about causal structure and identification. When estimating the effects of air pollution on housing prices in our application, we find that DML estimates are consistently larger than estimates of less flexible methods. From our overall results, we provide actionable recommendations for specific choices researchers must make when applying DML in practice.
5/1/2024
Combining Experimental and Historical Data for Policy Evaluation
Ting Li, Chengchun Shi, Qianglin Wen, Yang Sui, Yongli Qin, Chunbo Lai, Hongtu Zhu
0
0
This paper studies policy evaluation with multiple data sources, especially in scenarios that involve one experimental dataset with two arms, complemented by a historical dataset generated under a single control arm. We propose novel data integration methods that linearly integrate base policy value estimators constructed based on the experimental and historical data, with weights optimized to minimize the mean square error (MSE) of the resulting combined estimator. We further apply the pessimistic principle to obtain more robust estimators, and extend these developments to sequential decision making. Theoretically, we establish non-asymptotic error bounds for the MSEs of our proposed estimators, and derive their oracle, efficiency and robustness properties across a broad spectrum of reward shift scenarios. Numerical experiments and real-data-based analyses from a ridesharing company demonstrate the superior performance of the proposed estimators.
6/4/2024
Estimating Heterogeneous Treatment Effects by Combining Weak Instruments and Observational Data
Miruna Oprescu, Nathan Kallus
0
0
Accurately predicting conditional average treatment effects (CATEs) is crucial in personalized medicine and digital platform analytics. Since often the treatments of interest cannot be directly randomized, observational data is leveraged to learn CATEs, but this approach can incur significant bias from unobserved confounding. One strategy to overcome these limitations is to seek latent quasi-experiments in instrumental variables (IVs) for the treatment, for example, a randomized intent to treat or a randomized product recommendation. This approach, on the other hand, can suffer from low compliance, i.e., IV weakness. Some subgroups may even exhibit zero compliance meaning we cannot instrument for their CATEs at all. In this paper we develop a novel approach to combine IV and observational data to enable reliable CATE estimation in the presence of unobserved confounding in the observational data and low compliance in the IV data, including no compliance for some subgroups. We propose a two-stage framework that first learns biased CATEs from the observational data, and then applies a compliance-weighted correction using IV data, effectively leveraging IV strength variability across covariates. We characterize the convergence rates of our method and validate its effectiveness through a simulation study. Additionally, we demonstrate its utility with real data by analyzing the heterogeneous effects of 401(k) plan participation on wealth.
6/11/2024

Causal hybrid modeling with double machine learning
Kai-Hendrik Cohrs, Gherardo Varando, Nuno Carvalhais, Markus Reichstein, Gustau Camps-Valls
0
0
Hybrid modeling integrates machine learning with scientific knowledge to enhance interpretability, generalization, and adherence to natural laws. Nevertheless, equifinality and regularization biases pose challenges in hybrid modeling to achieve these purposes. This paper introduces a novel approach to estimating hybrid models via a causal inference framework, specifically employing Double Machine Learning (DML) to estimate causal effects. We showcase its use for the Earth sciences on two problems related to carbon dioxide fluxes. In the $Q_{10}$ model, we demonstrate that DML-based hybrid modeling is superior in estimating causal parameters over end-to-end deep neural network (DNN) approaches, proving efficiency, robustness to bias from regularization methods, and circumventing equifinality. Our approach, applied to carbon flux partitioning, exhibits flexibility in accommodating heterogeneous causal effects. The study emphasizes the necessity of explicitly defining causal graphs and relationships, advocating for this as a general best practice. We encourage the continued exploration of causality in hybrid models for more interpretable and trustworthy results in knowledge-guided machine learning.
4/5/2024