Combining RL and IL using a dynamic, performance-based modulation over learning signals and its application to local planning
2405.09760
0
0
Abstract
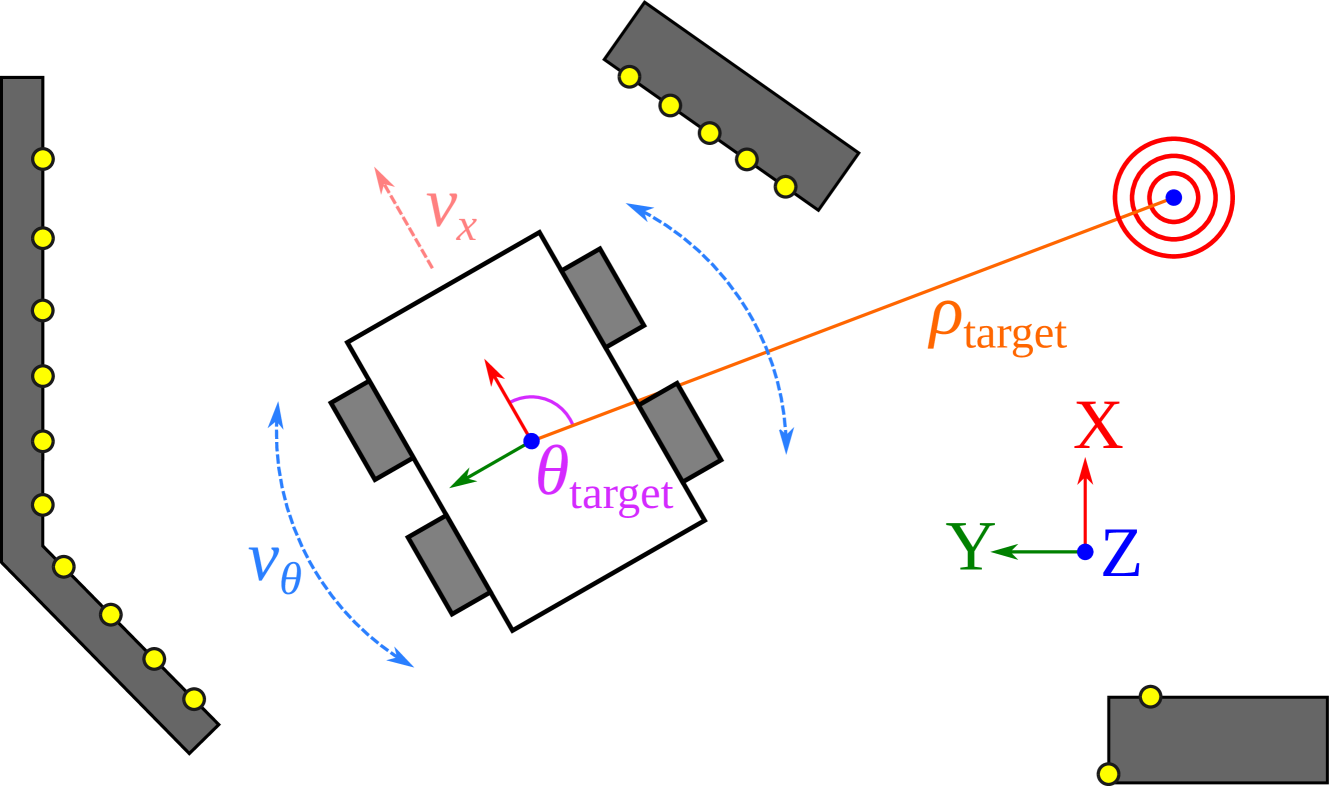
This paper proposes a method to combine reinforcement learning (RL) and imitation learning (IL) using a dynamic, performance-based modulation over learning signals. The proposed method combines RL and behavioral cloning (IL), or corrective feedback in the action space (interactive IL/IIL), by dynamically weighting the losses to be optimized, taking into account the backpropagated gradients used to update the policy and the agent's estimated performance. In this manner, RL and IL/IIL losses are combined by equalizing their impact on the policy's updates, while modulating said impact such that IL signals are prioritized at the beginning of the learning process, and as the agent's performance improves, the RL signals become progressively more relevant, allowing for a smooth transition from pure IL/IIL to pure RL. The proposed method is used to learn local planning policies for mobile robots, synthesizing IL/IIL signals online by means of a scripted policy. An extensive evaluation of the application of the proposed method to this task is performed in simulations, and it is empirically shown that it outperforms pure RL in terms of sample efficiency (achieving the same level of performance in the training environment utilizing approximately 4 times less experiences), while consistently producing local planning policies with better performance metrics (achieving an average success rate of 0.959 in an evaluation environment, outperforming pure RL by 12.5% and pure IL by 13.9%). Furthermore, the obtained local planning policies are successfully deployed in the real world without performing any major fine tuning. The proposed method can extend existing RL algorithms, and is applicable to other problems for which generating IL/IIL signals online is feasible. A video summarizing some of the real world experiments that were conducted can be found in https://youtu.be/mZlaXn9WGzw.
Create account to get full access
Overview
- Combines reinforcement learning (RL) and imitation learning (IL) using a dynamic, performance-based modulation over learning signals
- Applies this approach to local planning tasks
- Aims to leverage the strengths of both RL and IL to improve planning capabilities
Plain English Explanation
This research paper proposes a novel approach that combines reinforcement learning and imitation learning in a dynamic, performance-based way. The key idea is to have the system constantly evaluate its own performance and then adaptively adjust the relative influence of the RL and IL signals during the learning process.
The motivation is to take advantage of the complementary strengths of these two machine learning techniques. Reinforcement learning is good at discovering novel solutions through trial-and-error, while imitation learning can quickly learn effective behaviors by mimicking expert demonstrations. By blending these approaches in an intelligent way, the researchers aim to create a more capable and flexible planning system.
The paper then applies this combined RL-IL framework to the domain of local planning, where an agent needs to navigate through a dynamic environment and make real-time decisions. The dynamic modulation allows the system to start by relying more on imitation learning to get up to speed quickly, and then gradually transition to reinforcement learning as it gains more experience and becomes more self-sufficient.
The researchers demonstrate the effectiveness of their approach through experiments in simulated environments, showing that it outperforms using RL or IL alone. This suggests that the synergistic integration of these two powerful machine learning techniques can lead to significant performance improvements, especially for complex planning tasks.
Technical Explanation
The core of this research is a novel interactive imitation learning framework that dynamically blends reinforcement learning and imitation learning signals during the training process.
The key innovation is a performance-based modulation mechanism that continuously evaluates the agent's current capabilities and adjusts the relative weighting of the RL and IL learning signals accordingly. When the agent is performing poorly, the system increases the influence of the imitation learning signal to quickly bootstrap effective behaviors. As the agent improves, the RL signal is gradually given more weight to allow for more exploratory learning and the discovery of novel solutions.
The researchers apply this dynamic RL-IL framework to the domain of local planning, where an agent must navigate through a complex, changing environment and make real-time decisions. The experiments demonstrate that this combined approach outperforms using RL or IL alone, particularly in challenging scenarios that require both rapid skill acquisition and long-term optimization.
Critical Analysis
The researchers present a well-designed and thoughtful approach to integrating reinforcement learning and imitation learning. The dynamic modulation mechanism is a clever way to leverage the strengths of both techniques, and the application to local planning is a compelling real-world problem.
However, the paper does not address some potential limitations and areas for further research. For example, the performance-based modulation strategy relies on accurately measuring the agent's performance, which could be challenging in more complex or noisy environments. Additionally, the paper focuses on a specific local planning task, and it's unclear how well the approach would generalize to other domains or planning problems.
It would also be interesting to see how this framework compares to other approaches that combine RL and IL, such as learned reward functions or hierarchical architectures. Exploring these comparisons could help identify the unique strengths and limitations of the dynamic modulation technique.
Conclusion
This research presents a novel and promising approach to combining reinforcement learning and imitation learning for improved planning capabilities. By dynamically adjusting the relative influence of these two learning signals based on the agent's performance, the system can quickly acquire effective behaviors while also discovering novel solutions through exploration.
The application to local planning tasks demonstrates the potential real-world impact of this work, as the ability to navigate complex, dynamic environments is crucial for many robotics and autonomous systems applications. While the paper raises some interesting questions for further research, the core ideas and experimental results suggest that this dynamic RL-IL integration could be a valuable contribution to the field of machine learning for planning and control.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏋️
Fusion Dynamical Systems with Machine Learning in Imitation Learning: A Comprehensive Overview
Yingbai Hu, Fares J. Abu-Dakka, Fei Chen, Xiao Luo, Zheng Li, Alois Knoll, Weiping Ding
0
0
Imitation Learning (IL), also referred to as Learning from Demonstration (LfD), holds significant promise for capturing expert motor skills through efficient imitation, facilitating adept navigation of complex scenarios. A persistent challenge in IL lies in extending generalization from historical demonstrations, enabling the acquisition of new skills without re-teaching. Dynamical system-based IL (DSIL) emerges as a significant subset of IL methodologies, offering the ability to learn trajectories via movement primitives and policy learning based on experiential abstraction. This paper emphasizes the fusion of theoretical paradigms, integrating control theory principles inherent in dynamical systems into IL. This integration notably enhances robustness, adaptability, and convergence in the face of novel scenarios. This survey aims to present a comprehensive overview of DSIL methods, spanning from classical approaches to recent advanced approaches. We categorize DSIL into autonomous dynamical systems and non-autonomous dynamical systems, surveying traditional IL methods with low-dimensional input and advanced deep IL methods with high-dimensional input. Additionally, we present and analyze three main stability methods for IL: Lyapunov stability, contraction theory, and diffeomorphism mapping. Our exploration also extends to popular policy improvement methods for DSIL, encompassing reinforcement learning, deep reinforcement learning, and evolutionary strategies.
4/1/2024
🏅
Imitation Bootstrapped Reinforcement Learning
Hengyuan Hu, Suvir Mirchandani, Dorsa Sadigh
0
0
Despite the considerable potential of reinforcement learning (RL), robotic control tasks predominantly rely on imitation learning (IL) due to its better sample efficiency. However, it is costly to collect comprehensive expert demonstrations that enable IL to generalize to all possible scenarios, and any distribution shift would require recollecting data for finetuning. Therefore, RL is appealing if it can build upon IL as an efficient autonomous self-improvement procedure. We propose imitation bootstrapped reinforcement learning (IBRL), a novel framework for sample-efficient RL with demonstrations that first trains an IL policy on the provided demonstrations and then uses it to propose alternative actions for both online exploration and bootstrapping target values. Compared to prior works that oversample the demonstrations or regularize RL with an additional imitation loss, IBRL is able to utilize high quality actions from IL policies since the beginning of training, which greatly accelerates exploration and training efficiency. We evaluate IBRL on 6 simulation and 3 real-world tasks spanning various difficulty levels. IBRL significantly outperforms prior methods and the improvement is particularly more prominent in harder tasks.
5/7/2024
🏷️
Beyond Imitation: A Life-long Policy Learning Framework for Path Tracking Control of Autonomous Driving
C. Gong, C. Lu, Z. Li, Z. Liu, J. Gong, X. Chen
0
0
Model-free learning-based control methods have recently shown significant advantages over traditional control methods in avoiding complex vehicle characteristic estimation and parameter tuning. As a primary policy learning method, imitation learning (IL) is capable of learning control policies directly from expert demonstrations. However, the performance of IL policies is highly dependent on the data sufficiency and quality of the demonstrations. To alleviate the above problems of IL-based policies, a lifelong policy learning (LLPL) framework is proposed in this paper, which extends the IL scheme with lifelong learning (LLL). First, a novel IL-based model-free control policy learning method for path tracking is introduced. Even with imperfect demonstration, the optimal control policy can be learned directly from historical driving data. Second, by using the LLL method, the pre-trained IL policy can be safely updated and fine-tuned with incremental execution knowledge. Third, a knowledge evaluation method for policy learning is introduced to avoid learning redundant or inferior knowledge, thus ensuring the performance improvement of online policy learning. Experiments are conducted using a high-fidelity vehicle dynamic model in various scenarios to evaluate the performance of the proposed method. The results show that the proposed LLPL framework can continuously improve the policy performance with collected incremental driving data, and achieves the best accuracy and control smoothness compared to other baseline methods after evolving on a 7 km curved road. Through learning and evaluation with noisy real-life data collected in an off-road environment, the proposed LLPL framework also demonstrates its applicability in learning and evolving in real-life scenarios.
4/29/2024

Synergistic Reinforcement and Imitation Learning for Vision-driven Autonomous Flight of UAV Along River
Zihan Wang, Jianwen Li, Nina Mahmoudian
0
0
Vision-driven autonomous flight and obstacle avoidance of Unmanned Aerial Vehicles (UAVs) along complex riverine environments for tasks like rescue and surveillance requires a robust control policy, which is yet difficult to obtain due to the shortage of trainable riverine environment simulators. To easily verify the vision-based navigation controller performance for the river following task before real-world deployment, we developed a trainable photo-realistic dynamics-free riverine simulation environment using Unity. In this paper, we address the shortcomings that vanilla Reinforcement Learning (RL) algorithm encounters in learning a navigation policy within this partially observable, non-Markovian environment. We propose a synergistic approach that integrates RL and Imitation Learning (IL). Initially, an IL expert is trained on manually collected demonstrations, which then guides the RL policy training process. Concurrently, experiences generated by the RL agent are utilized to re-train the IL expert, enhancing its ability to generalize to unseen data. By leveraging the strengths of both RL and IL, this framework achieves a faster convergence rate and higher performance compared to pure RL, pure IL, and RL combined with static IL algorithms. The results validate the efficacy of the proposed method in terms of both task completion and efficiency. The code and trainable environments are available.
5/1/2024