Communication-Efficient Distributed Deep Learning via Federated Dynamic Averaging

0

Sign in to get full access
Overview
- This paper proposes a new approach called "Federated Dynamic Averaging" (FDA) to improve the communication efficiency of distributed deep learning models.
- FDA dynamically adjusts the frequency of model updates between the central server and edge devices, reducing the amount of data that needs to be transmitted.
- The authors demonstrate the effectiveness of FDA on several image classification tasks, showing that it can achieve comparable accuracy to traditional federated learning while significantly reducing communication costs.
Plain English Explanation
The paper focuses on a challenge in distributed deep learning - the large amount of data that needs to be transmitted between the central server and the edge devices (e.g., smartphones, IoT sensors) during the training process. This communication overhead can be a significant bottleneck, especially in settings with limited network bandwidth or devices with low computational power.
To address this, the researchers developed a new technique called Federated Dynamic Averaging (FDA). The key idea behind FDA is to dynamically adjust the frequency of model updates between the central server and the edge devices. Instead of sending updates after every training iteration, the edge devices only send updates when the changes to the model are significant enough. This reduces the overall amount of data that needs to be transmitted, making the training process more communication-efficient.
The authors tested FDA on several image classification tasks and found that it could achieve similar accuracy to traditional federated learning approaches, but with much lower communication costs. This could be particularly useful in scenarios where network bandwidth is limited, such as federated learning for aerial vehicles or federated learning in healthcare.
Technical Explanation
The key technical innovation in this paper is the Federated Dynamic Averaging (FDA) algorithm, which dynamically adjusts the frequency of model updates between the central server and the edge devices. The algorithm works as follows:
- The central server initializes a global model and distributes it to the edge devices.
- Each edge device trains the model on its local data and computes the update to the model parameters.
- Instead of sending the update after every training iteration, the edge device checks the magnitude of the update. If the update is above a certain threshold, the edge device sends the update to the central server.
- The central server aggregates the updates from the edge devices and updates the global model accordingly.
- The central server then broadcasts the updated global model to the edge devices, and the process repeats.
The authors show that this dynamic update strategy can significantly reduce the amount of communication required while maintaining comparable model accuracy to traditional federated learning approaches. They evaluate FDA on several image classification tasks, including CIFAR-10, CIFAR-100, and ImageNet, and demonstrate its effectiveness in reducing communication costs.
Critical Analysis
The authors provide a thorough experimental evaluation of the FDA algorithm and demonstrate its benefits in terms of communication efficiency. However, the paper does not discuss some potential limitations or caveats:
- The performance of FDA may depend heavily on the choice of the update threshold, which is a hyperparameter that needs to be tuned for each task and dataset. It's not clear how robust the algorithm is to different threshold values.
- The paper only considers image classification tasks, which may have different communication patterns than other types of machine learning problems, such as language modeling or reinforcement learning. Further research is needed to understand the broader applicability of FDA.
- The authors do not discuss potential issues with the stability or convergence of the FDA algorithm, especially in the presence of highly heterogeneous data across edge devices.
Overall, the FDA algorithm presents an interesting approach to improving the communication efficiency of distributed deep learning, but additional research is needed to fully understand its limitations and potential issues.
Conclusion
This paper introduces a new technique called Federated Dynamic Averaging (FDA) that can significantly reduce the communication overhead in distributed deep learning. By dynamically adjusting the frequency of model updates between the central server and edge devices, FDA can achieve comparable accuracy to traditional federated learning approaches while greatly reducing the amount of data that needs to be transmitted.
The results demonstrate the potential of FDA to enable more communication-efficient distributed deep learning, which could be particularly useful in scenarios with limited network bandwidth or devices with constrained computational resources, such as federated learning for aerial vehicles or federated learning in healthcare. Further research is needed to understand the broader applicability of FDA and address potential limitations, but this work represents an important step towards more efficient distributed deep learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Communication-Efficient Distributed Deep Learning via Federated Dynamic Averaging
Michail Theologitis, Georgios Frangias, Georgios Anestis, Vasilis Samoladas, Antonios Deligiannakis
Driven by the ever-growing volume and decentralized nature of data, coupled with the need to harness this data and generate knowledge from it, has led to the extensive use of distributed deep learning (DDL) techniques for training. These techniques rely on local training that is performed at the distributed nodes based on locally collected data, followed by a periodic synchronization process that combines these models to create a global model. However, frequent synchronization of DL models, encompassing millions to many billions of parameters, creates a communication bottleneck, severely hindering scalability. Worse yet, DDL algorithms typically waste valuable bandwidth, and make themselves less practical in bandwidth-constrained federated settings, by relying on overly simplistic, periodic, and rigid synchronization schedules. These drawbacks also have a direct impact on the time required for the training process, necessitating excessive time for data communication. To address these shortcomings, we propose Federated Dynamic Averaging (FDA), a communication-efficient DDL strategy that dynamically triggers synchronization based on the value of the model variance. In essence, the costly synchronization step is triggered only if the local models, which are initialized from a common global model after each synchronization, have significantly diverged. This decision is facilitated by the communication of a small local state from each distributed node/worker. Through extensive experiments across a wide range of learning tasks we demonstrate that FDA reduces communication cost by orders of magnitude, compared to both traditional and cutting-edge communication-efficient algorithms. Additionally, we show that FDA maintains robust performance across diverse data heterogeneity settings.
Read more6/7/2024

0
FedDM: Enhancing Communication Efficiency and Handling Data Heterogeneity in Federated Diffusion Models
Jayneel Vora, Nader Bouacida, Aditya Krishnan, Prasant Mohapatra
We introduce FedDM, a novel training framework designed for the federated training of diffusion models. Our theoretical analysis establishes the convergence of diffusion models when trained in a federated setting, presenting the specific conditions under which this convergence is guaranteed. We propose a suite of training algorithms that leverage the U-Net architecture as the backbone for our diffusion models. These include a basic Federated Averaging variant, FedDM-vanilla, FedDM-prox to handle data heterogeneity among clients, and FedDM-quant, which incorporates a quantization module to reduce the model update size, thereby enhancing communication efficiency across the federated network. We evaluate our algorithms on FashionMNIST (28x28 resolution), CIFAR-10 (32x32 resolution), and CelebA (64x64 resolution) for DDPMs, as well as LSUN Church Outdoors (256x256 resolution) for LDMs, focusing exclusively on the imaging modality. Our evaluation results demonstrate that FedDM algorithms maintain high generation quality across image resolutions. At the same time, the use of quantized updates and proximal terms in the local training objective significantly enhances communication efficiency (up to 4x) and model convergence, particularly in non-IID data settings, at the cost of increased FID scores (up to 1.75x).
Read more7/23/2024
0
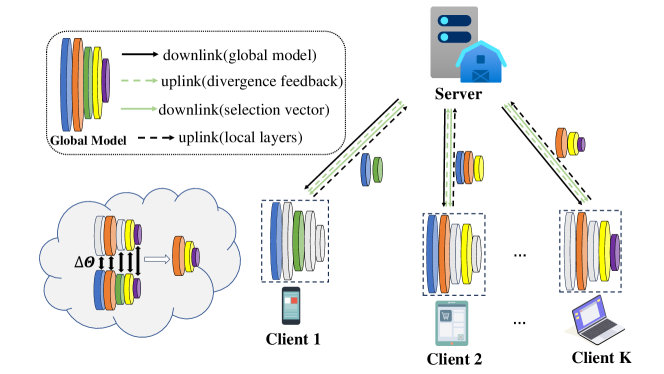
Communication-Efficient Model Aggregation with Layer Divergence Feedback in Federated Learning
Liwei Wang, Jun Li, Wen Chen, Qingqing Wu, Ming Ding
Federated Learning (FL) facilitates collaborative machine learning by training models on local datasets, and subsequently aggregating these local models at a central server. However, the frequent exchange of model parameters between clients and the central server can result in significant communication overhead during the FL training process. To solve this problem, this paper proposes a novel FL framework, the Model Aggregation with Layer Divergence Feedback mechanism (FedLDF). Specifically, we calculate model divergence between the local model and the global model from the previous round. Then through model layer divergence feedback, the distinct layers of each client are uploaded and the amount of data transferred is reduced effectively. Moreover, the convergence bound reveals that the access ratio of clients has a positive correlation with model performance. Simulation results show that our algorithm uploads local models with reduced communication overhead while upholding a superior global model performance.
Read more4/15/2024

0
Training Diffusion Models with Federated Learning
Matthijs de Goede, Bart Cox, J'er'emie Decouchant
The training of diffusion-based models for image generation is predominantly controlled by a select few Big Tech companies, raising concerns about privacy, copyright, and data authority due to their lack of transparency regarding training data. To ad-dress this issue, we propose a federated diffusion model scheme that enables the independent and collaborative training of diffusion models without exposing local data. Our approach adapts the Federated Averaging (FedAvg) algorithm to train a Denoising Diffusion Model (DDPM). Through a novel utilization of the underlying UNet backbone, we achieve a significant reduction of up to 74% in the number of parameters exchanged during training,compared to the naive FedAvg approach, whilst simultaneously maintaining image quality comparable to the centralized setting, as evaluated by the FID score.
Read more6/19/2024