Towards Adapting Open-Source Large Language Models for Expert-Level Clinical Note Generation
2405.00715
0
0
Abstract
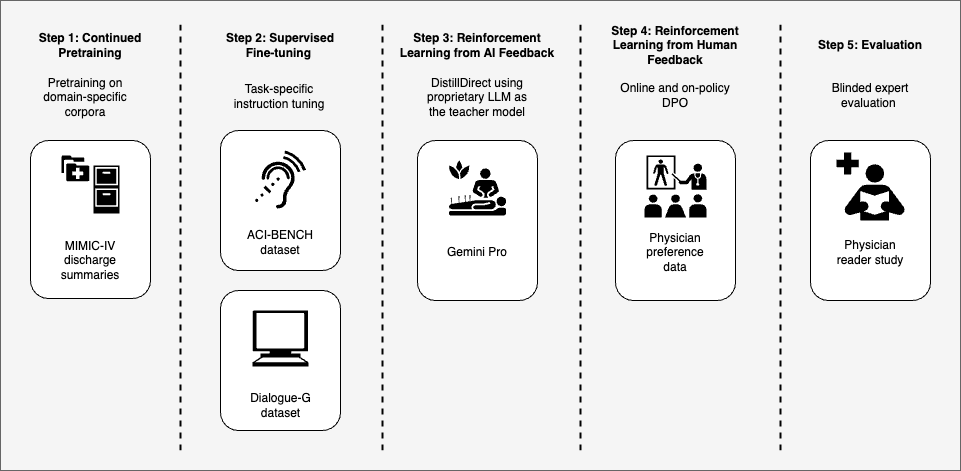
Proprietary Large Language Models (LLMs) such as GPT-4 and Gemini have demonstrated promising capabilities in clinical text summarization tasks. However, due to patient data privacy concerns and computational costs, many healthcare providers prefer using small, locally-hosted models over external generic LLMs. This study presents a comprehensive domain- and task-specific adaptation process for the open-source LLaMA-2 13 billion parameter model, enabling it to generate high-quality clinical notes from outpatient patient-doctor dialogues. Our process incorporates continued pre-training, supervised fine-tuning, and reinforcement learning from both AI and human feedback. We introduced a new approach, DistillDirect, for performing on-policy reinforcement learning with Gemini 1.0 Pro as the teacher model. Our resulting model, LLaMA-Clinic, can generate clinical notes comparable in quality to those authored by physicians. In a blinded physician reader study, the majority (90.4%) of individual evaluations rated the notes generated by LLaMA-Clinic as acceptable or higher across all three criteria: real-world readiness, completeness, and accuracy. In the more challenging Assessment and Plan section, LLaMA-Clinic scored higher (4.2/5) in real-world readiness than physician-authored notes (4.1/5). Our cost analysis for inference shows that our LLaMA-Clinic model achieves a 3.75-fold cost reduction compared to an external generic LLM service. Additionally, we highlight key considerations for future clinical note-generation tasks, emphasizing the importance of pre-defining a best-practice note format, rather than relying on LLMs to determine this for clinical practice. We have made our newly created synthetic clinic dialogue-note dataset and the physician feedback dataset publicly available to foster future research.
Create account to get full access
Overview
- This paper explores the potential of adapting open-source large language models (LLMs) to generate expert-level clinical notes, which could improve healthcare efficiency and patient outcomes.
- The researchers investigated fine-tuning LLMs like Adapted Large Language Models Can Outperform Medical Experts and ME-LLaMA: Foundation Large Language Models for Medical Applications on clinical datasets to assess their ability to produce high-quality medical notes.
- The paper also examines the feasibility of using these adapted LLMs as part of a comprehensive system for automating clinical documentation, building on work like Large Language Models for Healthcare: A Comprehensive Benchmark and A Continued Pretrained LLM Approach for Automatic Medical Note Generation.
Plain English Explanation
This research looks at using powerful language models, known as large language models (LLMs), to help generate high-quality medical notes. Medical notes are an important part of healthcare, as they help doctors and nurses keep track of a patient's condition and treatment. However, writing these notes can be time-consuming for healthcare providers.
The researchers in this study wanted to see if they could take existing open-source LLMs, like the ones used in Adapted Large Language Models Can Outperform Medical Experts and ME-LLaMA: Foundation Large Language Models for Medical Applications, and fine-tune them on medical data. This means they would teach the LLMs the specific language and format used in medical notes.
The goal was to see if these adapted LLMs could then generate high-quality, expert-level medical notes automatically. This could save healthcare providers time and potentially improve patient care by ensuring important details are captured consistently. The researchers built on previous work, like Large Language Models for Healthcare: A Comprehensive Benchmark and A Continued Pretrained LLM Approach for Automatic Medical Note Generation, that has explored using language models for medical applications.
Technical Explanation
The paper investigates the feasibility of adapting open-source large language models (LLMs) to generate expert-level clinical notes. The researchers fine-tuned several LLMs, including those explored in Adapted Large Language Models Can Outperform Medical Experts and ME-LLaMA: Foundation Large Language Models for Medical Applications, on clinical datasets to assess their ability to produce high-quality medical notes.
The fine-tuning process involved training the base LLMs on large collections of clinical text data, such as electronic health records and medical literature, to imbue them with domain-specific knowledge and language patterns. The researchers then evaluated the adapted LLMs on various clinical note generation tasks, measuring factors like coherence, medical accuracy, and adherence to clinical documentation standards.
The findings build on previous work, like Large Language Models for Healthcare: A Comprehensive Benchmark and A Continued Pretrained LLM Approach for Automatic Medical Note Generation, which have explored the use of language models for automating clinical documentation. The results suggest that with appropriate fine-tuning, open-source LLMs can generate clinical notes that approach the quality and consistency of those produced by human experts.
Critical Analysis
The paper presents a promising approach for leveraging open-source LLMs to assist with clinical note generation, but it also acknowledges several important caveats and areas for further research.
One key limitation is the reliance on curated clinical datasets for fine-tuning the LLMs. The researchers note that the quality and representativeness of these datasets can significantly impact the performance of the adapted models, and further work is needed to address potential biases and gaps in the training data.
Additionally, the paper highlights the need for robust evaluation frameworks to assess the clinical validity and safety of the generated notes. While the reported results are encouraging, the researchers emphasize the importance of thorough testing and validation to ensure the adapted LLMs can be deployed safely in real-world healthcare settings, as discussed in Hippocrates: An Open-Source Framework for Advancing Large Language Models in Healthcare.
Another area for further investigation is the potential for these adapted LLMs to be integrated into broader clinical documentation workflows, building on work like A Continued Pretrained LLM Approach for Automatic Medical Note Generation. The researchers acknowledge the need to explore how these models could be seamlessly incorporated into existing healthcare information systems to maximize their impact.
Overall, the paper presents a valuable contribution to the growing body of research exploring the use of LLMs in healthcare. While the findings are promising, the researchers emphasize the importance of continued refinement, validation, and responsible deployment to ensure these technologies can truly benefit patients and healthcare providers.
Conclusion
This research explores the potential of adapting open-source large language models (LLMs) to generate expert-level clinical notes, which could improve healthcare efficiency and patient outcomes. The researchers fine-tuned several LLMs on clinical datasets and evaluated their ability to produce high-quality medical notes.
The findings build on previous work in this area, suggesting that with appropriate fine-tuning, open-source LLMs can generate clinical notes that approach the quality and consistency of those produced by human experts. However, the paper also highlights important caveats and areas for further research, such as the need for robust evaluation frameworks, addressing potential biases in training data, and seamlessly integrating these models into clinical documentation workflows.
Overall, this research represents a valuable contribution to the growing field of using language models for healthcare applications. While the results are promising, the researchers emphasize the importance of continued refinement, validation, and responsible deployment to ensure these technologies can truly benefit patients and healthcare providers.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Adapted Large Language Models Can Outperform Medical Experts in Clinical Text Summarization
Dave Van Veen, Cara Van Uden, Louis Blankemeier, Jean-Benoit Delbrouck, Asad Aali, Christian Bluethgen, Anuj Pareek, Malgorzata Polacin, Eduardo Pontes Reis, Anna Seehofnerova, Nidhi Rohatgi, Poonam Hosamani, William Collins, Neera Ahuja, Curtis P. Langlotz, Jason Hom, Sergios Gatidis, John Pauly, Akshay S. Chaudhari
0
0
Analyzing vast textual data and summarizing key information from electronic health records imposes a substantial burden on how clinicians allocate their time. Although large language models (LLMs) have shown promise in natural language processing (NLP), their effectiveness on a diverse range of clinical summarization tasks remains unproven. In this study, we apply adaptation methods to eight LLMs, spanning four distinct clinical summarization tasks: radiology reports, patient questions, progress notes, and doctor-patient dialogue. Quantitative assessments with syntactic, semantic, and conceptual NLP metrics reveal trade-offs between models and adaptation methods. A clinical reader study with ten physicians evaluates summary completeness, correctness, and conciseness; in a majority of cases, summaries from our best adapted LLMs are either equivalent (45%) or superior (36%) compared to summaries from medical experts. The ensuing safety analysis highlights challenges faced by both LLMs and medical experts, as we connect errors to potential medical harm and categorize types of fabricated information. Our research provides evidence of LLMs outperforming medical experts in clinical text summarization across multiple tasks. This suggests that integrating LLMs into clinical workflows could alleviate documentation burden, allowing clinicians to focus more on patient care.
4/15/2024
💬
Comparative Analysis of Open-Source Language Models in Summarizing Medical Text Data
Yuhao Chen, Zhimu Wang, Bo Wen, Farhana Zulkernine
0
0
Unstructured text in medical notes and dialogues contains rich information. Recent advancements in Large Language Models (LLMs) have demonstrated superior performance in question answering and summarization tasks on unstructured text data, outperforming traditional text analysis approaches. However, there is a lack of scientific studies in the literature that methodically evaluate and report on the performance of different LLMs, specifically for domain-specific data such as medical chart notes. We propose an evaluation approach to analyze the performance of open-source LLMs such as Llama2 and Mistral for medical summarization tasks, using GPT-4 as an assessor. Our innovative approach to quantitative evaluation of LLMs can enable quality control, support the selection of effective LLMs for specific tasks, and advance knowledge discovery in digital health.
5/31/2024
🤯
D-NLP at SemEval-2024 Task 2: Evaluating Clinical Inference Capabilities of Large Language Models
Duygu Altinok
0
0
Large language models (LLMs) have garnered significant attention and widespread usage due to their impressive performance in various tasks. However, they are not without their own set of challenges, including issues such as hallucinations, factual inconsistencies, and limitations in numerical-quantitative reasoning. Evaluating LLMs in miscellaneous reasoning tasks remains an active area of research. Prior to the breakthrough of LLMs, Transformers had already proven successful in the medical domain, effectively employed for various natural language understanding (NLU) tasks. Following this trend, LLMs have also been trained and utilized in the medical domain, raising concerns regarding factual accuracy, adherence to safety protocols, and inherent limitations. In this paper, we focus on evaluating the natural language inference capabilities of popular open-source and closed-source LLMs using clinical trial reports as the dataset. We present the performance results of each LLM and further analyze their performance on a development set, particularly focusing on challenging instances that involve medical abbreviations and require numerical-quantitative reasoning. Gemini, our leading LLM, achieved a test set F1-score of 0.748, securing the ninth position on the task scoreboard. Our work is the first of its kind, offering a thorough examination of the inference capabilities of LLMs within the medical domain.
5/8/2024
💬
Publicly Shareable Clinical Large Language Model Built on Synthetic Clinical Notes
Sunjun Kweon, Junu Kim, Jiyoun Kim, Sujeong Im, Eunbyeol Cho, Seongsu Bae, Jungwoo Oh, Gyubok Lee, Jong Hak Moon, Seng Chan You, Seungjin Baek, Chang Hoon Han, Yoon Bin Jung, Yohan Jo, Edward Choi
0
0
The development of large language models tailored for handling patients' clinical notes is often hindered by the limited accessibility and usability of these notes due to strict privacy regulations. To address these challenges, we first create synthetic large-scale clinical notes using publicly available case reports extracted from biomedical literature. We then use these synthetic notes to train our specialized clinical large language model, Asclepius. While Asclepius is trained on synthetic data, we assess its potential performance in real-world applications by evaluating it using real clinical notes. We benchmark Asclepius against several other large language models, including GPT-3.5-turbo and other open-source alternatives. To further validate our approach using synthetic notes, we also compare Asclepius with its variants trained on real clinical notes. Our findings convincingly demonstrate that synthetic clinical notes can serve as viable substitutes for real ones when constructing high-performing clinical language models. This conclusion is supported by detailed evaluations conducted by both GPT-4 and medical professionals. All resources including weights, codes, and data used in the development of Asclepius are made publicly accessible for future research. (https://github.com/starmpcc/Asclepius)
6/14/2024