Comparing Complex Concepts with Transformers: Matching Patent Claims Against Natural Language Text

0
🌿
Sign in to get full access
Overview
- Compares claims in patent applications to other text like the patent specification
- Challenges in this task due to differences in language between claims and other parts of a patent
- Tests two new language model-based approaches and finds they outperform previous methods
Plain English Explanation
Comparing the key claims in a patent application to other text, like the full patent specification, is an important capability for managing patent portfolios. However, this is a challenging task for computers because the language used in the claims is often quite different from the language used elsewhere in the patent document or in non-patent text.
The researchers in this study tested two new approaches using large language models (LLMs) - advanced AI systems trained on vast amounts of text data. They found that both of these new LLM-based methods substantially outperformed previous techniques that had been published.
This ability to match dense, technical information from one domain (the patent claims) against more broad and varied information expressed in different vocabulary could be useful beyond just the intellectual property space. It suggests LLMs have powerful text-matching capabilities that could apply to other domains where specialized terminology needs to be related to more general language.
Technical Explanation
The researchers tested two new LLM-based approaches for the task of matching patent claims to other text. The first used an LLM to generate patent images from the claim text, which were then matched against images generated from the full patent specification. The second directly used the LLM to evaluate the similarity between the claim text and the specification text.
Both of these new LLM-based approaches significantly outperformed previous techniques that had been published for this specialized language processing task. The researchers suggest the LLMs' ability to match entities and concepts across different vocabulary domains is a key factor in their strong performance.
Critical Analysis
The paper acknowledges some limitations, such as the models' tendency to focus on surface-level similarities rather than deeper semantic connections. The authors also note that further research is needed to understand the models' failure cases and improve their robustness.
While the results are promising, it's important to consider potential biases or errors the LLMs may introduce, especially when applied to high-stakes domains like intellectual property. Careful evaluation and validation will be crucial as these techniques are developed further.
Conclusion
This research demonstrates the potential for large language models to tackle specialized text-matching tasks that have historically been challenging for computers, such as relating patent claims to the broader patent specification. The ability to bridge different vocabularies and domains suggests LLMs could have valuable applications beyond just the intellectual property space.
However, the limitations and potential pitfalls highlighted in the critical analysis suggest these techniques will require thoughtful development and validation before they can be reliably deployed. Continued research in this area could yield important advances in natural language processing and its real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌿
0
Comparing Complex Concepts with Transformers: Matching Patent Claims Against Natural Language Text
Matthias Blume, Ghobad Heidari, Christoph Hewel
A key capability in managing patent applications or a patent portfolio is comparing claims to other text, e.g. a patent specification. Because the language of claims is different from language used elsewhere in the patent application or in non-patent text, this has been challenging for computer based natural language processing. We test two new LLM-based approaches and find that both provide substantially better performance than previously published values. The ability to match dense information from one domain against much more distributed information expressed in a different vocabulary may also be useful beyond the intellectual property space.
Read more7/16/2024

0
Natural Language Processing in Patents: A Survey
Lekang Jiang, Stephan Goetz
Patents, encapsulating crucial technical and legal information, present a rich domain for natural language processing (NLP) applications. As NLP technologies evolve, large language models (LLMs) have demonstrated outstanding capabilities in general text processing and generation tasks. However, the application of LLMs in the patent domain remains under-explored and under-developed due to the complexity of patent processing. Understanding the unique characteristics of patent documents and related research in the patent domain becomes essential for researchers to apply these tools effectively. Therefore, this paper aims to equip NLP researchers with the essential knowledge to navigate this complex domain efficiently. We introduce the relevant fundamental aspects of patents to provide solid background information, particularly for readers unfamiliar with the patent system. In addition, we systematically break down the structural and linguistic characteristics unique to patents and map out how NLP can be leveraged for patent analysis and generation. Moreover, we demonstrate the spectrum of text-based patent-related tasks, including nine patent analysis and four patent generation tasks.
Read more8/14/2024

0
Can Large Language Models Generate High-quality Patent Claims?
Lekang Jiang, Caiqi Zhang, Pascal A Scherz, Stephan Goetz
Large language models (LLMs) have shown exceptional performance across various text generation tasks but remain under-explored in the patent domain, which offers highly structured and precise language. This paper constructs a dataset to investigate the performance of current LLMs in patent claim generation. Our results demonstrate that generating claims based on patent descriptions outperforms previous research relying on abstracts. Interestingly, current patent-specific LLMs perform much worse than state-of-the-art general LLMs, highlighting the necessity for future research on in-domain LLMs. We also find that LLMs can produce high-quality first independent claims, but their performances markedly decrease for subsequent dependent claims. Moreover, fine-tuning can enhance the completeness of inventions' features, conceptual clarity, and feature linkage. Among the tested LLMs, GPT-4 demonstrates the best performance in comprehensive human evaluations by patent experts, with better feature coverage, conceptual clarity, and technical coherence. Despite these capabilities, comprehensive revision and modification are still necessary to pass rigorous patent scrutiny and ensure legal robustness.
Read more7/1/2024
0
Large Language Model Informed Patent Image Retrieval
Hao-Cheng Lo, Jung-Mei Chu, Jieh Hsiang, Chun-Chieh Cho
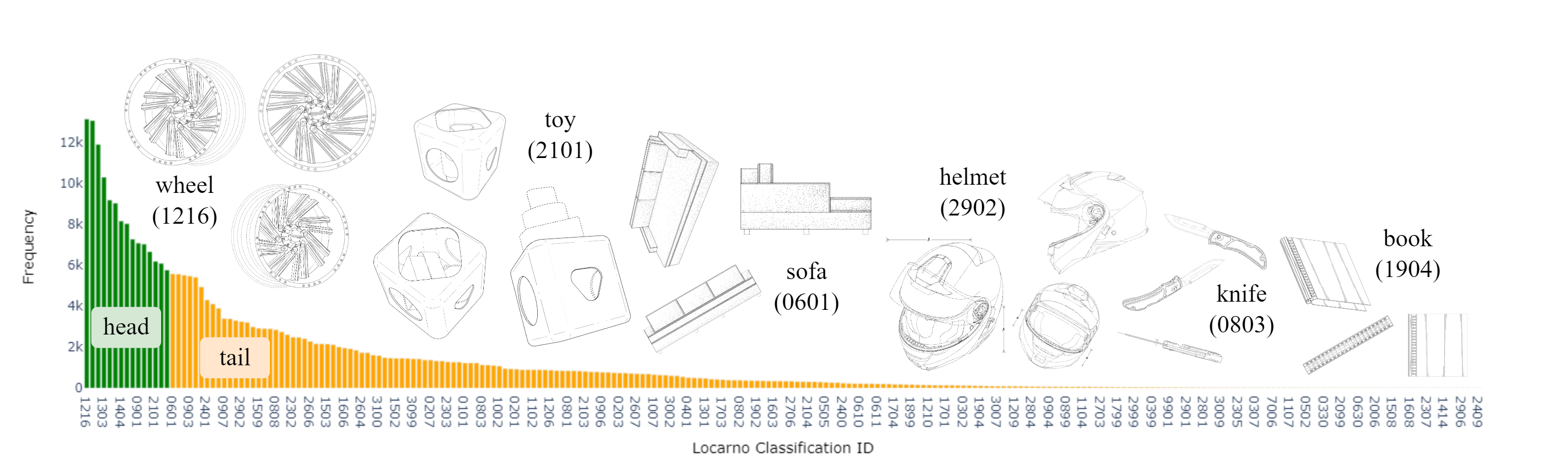
In patent prosecution, image-based retrieval systems for identifying similarities between current patent images and prior art are pivotal to ensure the novelty and non-obviousness of patent applications. Despite their growing popularity in recent years, existing attempts, while effective at recognizing images within the same patent, fail to deliver practical value due to their limited generalizability in retrieving relevant prior art. Moreover, this task inherently involves the challenges posed by the abstract visual features of patent images, the skewed distribution of image classifications, and the semantic information of image descriptions. Therefore, we propose a language-informed, distribution-aware multimodal approach to patent image feature learning, which enriches the semantic understanding of patent image by integrating Large Language Models and improves the performance of underrepresented classes with our proposed distribution-aware contrastive losses. Extensive experiments on DeepPatent2 dataset show that our proposed method achieves state-of-the-art or comparable performance in image-based patent retrieval with mAP +53.3%, Recall@10 +41.8%, and MRR@10 +51.9%. Furthermore, through an in-depth user analysis, we explore our model in aiding patent professionals in their image retrieval efforts, highlighting the model's real-world applicability and effectiveness.
Read more5/1/2024