Comparing Unidirectional, Bidirectional, and Word2vec Models for Discovering Vulnerabilities in Compiled Lifted Code

0
Sign in to get full access
Overview
- Compares the performance of unidirectional, bidirectional, and Word2vec models for discovering vulnerabilities in compiled lifted code
- Evaluates the models on their ability to detect buffer overflow vulnerabilities, a common type of software security flaw
- Finds that bidirectional models outperform unidirectional and Word2vec models in vulnerability detection
Plain English Explanation
This research paper examines different machine learning models for finding security vulnerabilities in software code. Specifically, it looks at unidirectional, bidirectional, and Word2vec models and how well they can detect a common type of vulnerability called a buffer overflow.
The researchers found that the bidirectional models, which can process information in both directions, performed better than the unidirectional models that only process information in one direction. This is likely because vulnerabilities can occur in complex ways throughout the code, and the bidirectional approach allows the model to better understand those relationships.
The paper suggests that using more advanced neural network architectures like bidirectional models can be an effective way to improve the automated detection of security flaws in software. This could help developers catch vulnerabilities earlier in the development process and make software more secure.
Technical Explanation
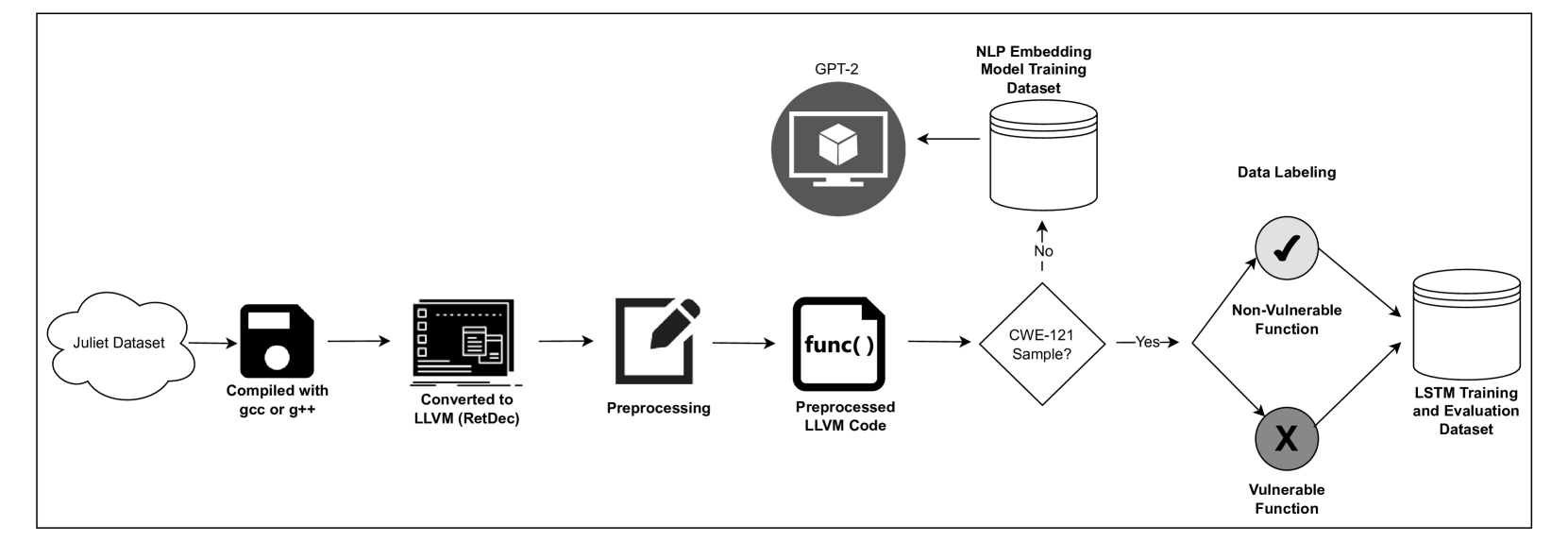
The paper evaluates three different types of natural language processing models for their ability to detect buffer overflow vulnerabilities in compiled lifted code:
- Unidirectional models: These models process the code sequentially, from start to finish, to generate a representation.
- Bidirectional models: These models process the code in both the forward and backward directions to generate a more contextual representation.
- Word2vec models: These models learn vector representations of individual code tokens, which are then used for vulnerability detection.
The researchers trained and evaluated these models on a dataset of real-world software binaries containing both vulnerable and non-vulnerable code. They measured the models' performance using metrics like precision, recall, and F1-score.
The results showed that the bidirectional models outperformed the unidirectional and Word2vec models on the vulnerability detection task. The authors attribute this to the bidirectional models' ability to capture more contextual information about the code structure and relationships between different components.
Critical Analysis
The paper provides a thorough and well-designed experimental evaluation of the three model types. However, there are a few potential limitations and areas for further research:
-
Dataset size and diversity: The dataset used in the experiments, while real-world, may not be large or diverse enough to fully generalize the findings. Evaluating the models on a broader range of software projects could provide more robust results.
-
Interpretability and explainability: The paper does not delve into how the models arrive at their predictions or what specific code features they are using to detect vulnerabilities. Improving the interpretability of these models could lead to better understanding and further improvements.
-
Generalization to other vulnerability types: The focus of this paper is on buffer overflow vulnerabilities. It would be valuable to explore how the model performance extends to other common vulnerability types, such as SQL injections or cross-site scripting (XSS) flaws.
-
Practical deployment challenges: While the results are promising, the authors do not discuss the practical challenges of deploying these models in real-world software development workflows. Factors like model inference speed, integration with existing tooling, and maintaining model performance over time should be considered.
Conclusion
This research presents a compelling case for the use of bidirectional neural network models to improve the automated detection of security vulnerabilities in software code. By outperforming both unidirectional and Word2vec approaches, the bidirectional models demonstrate the value of capturing contextual information when analyzing complex code structures.
The findings of this paper suggest that continued advancements in machine learning for software security could lead to more effective and comprehensive vulnerability detection tools. This could ultimately help developers build more secure software and better protect users from potential exploits.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Comparing Unidirectional, Bidirectional, and Word2vec Models for Discovering Vulnerabilities in Compiled Lifted Code
Gary A. McCully, John D. Hastings, Shengjie Xu, Adam Fortier
Ransomware and other forms of malware cause significant financial and operational damage to organizations by exploiting long-standing and often difficult-to-detect software vulnerabilities. To detect vulnerabilities such as buffer overflows in compiled code, this research investigates the application of unidirectional transformer-based embeddings, specifically GPT-2. Using a dataset of LLVM functions, we trained a GPT-2 model to generate embeddings, which were subsequently used to build LSTM neural networks to differentiate between vulnerable and non-vulnerable code. Our study reveals that embeddings from the GPT-2 model significantly outperform those from bidirectional models of BERT and RoBERTa, achieving an accuracy of 92.5% and an F1-score of 89.7%. LSTM neural networks were developed with both frozen and unfrozen embedding model layers. The model with the highest performance was achieved when the embedding layers were unfrozen. Further, the research finds that, in exploring the impact of different optimizers within this domain, the SGD optimizer demonstrates superior performance over Adam. Overall, these findings reveal important insights into the potential of unidirectional transformer-based approaches in enhancing cybersecurity defenses.
Read more9/27/2024
📶
0
Bi-Directional Transformers vs. word2vec: Discovering Vulnerabilities in Lifted Compiled Code
Gary A. McCully, John D. Hastings, Shengjie Xu, Adam Fortier
Detecting vulnerabilities within compiled binaries is challenging due to lost high-level code structures and other factors such as architectural dependencies, compilers, and optimization options. To address these obstacles, this research explores vulnerability detection using natural language processing (NLP) embedding techniques with word2vec, BERT, and RoBERTa to learn semantics from intermediate representation (LLVM IR) code. Long short-term memory (LSTM) neural networks were trained on embeddings from encoders created using approximately 48k LLVM functions from the Juliet dataset. This study is pioneering in its comparison of word2vec models with multiple bidirectional transformer (BERT, RoBERTa) embeddings built using LLVM code to train neural networks to detect vulnerabilities in compiled binaries. word2vec Skip-Gram models achieved 92% validation accuracy in detecting vulnerabilities, outperforming word2vec Continuous Bag of Words (CBOW), BERT, and RoBERTa. This suggests that complex contextual embeddings may not provide advantages over simpler word2vec models for this task when a limited number (e.g. 48K) of data samples are used to train the bidirectional transformer-based models. The comparative results provide novel insights into selecting optimal embeddings for learning compiler-independent semantic code representations to advance machine learning detection of vulnerabilities in compiled binaries.
Read more9/10/2024
🌀
0
Automated Software Vulnerability Static Code Analysis Using Generative Pre-Trained Transformer Models
Elijah Pelofske, Vincent Urias, Lorie M. Liebrock
Generative Pre-Trained Transformer models have been shown to be surprisingly effective at a variety of natural language processing tasks -- including generating computer code. We evaluate the effectiveness of open source GPT models for the task of automatic identification of the presence of vulnerable code syntax (specifically targeting C and C++ source code). This task is evaluated on a selection of 36 source code examples from the NIST SARD dataset, which are specifically curated to not contain natural English that indicates the presence, or lack thereof, of a particular vulnerability. The NIST SARD source code dataset contains identified vulnerable lines of source code that are examples of one out of the 839 distinct Common Weakness Enumerations (CWE), allowing for exact quantification of the GPT output classification error rate. A total of 5 GPT models are evaluated, using 10 different inference temperatures and 100 repetitions at each setting, resulting in 5,000 GPT queries per vulnerable source code analyzed. Ultimately, we find that the GPT models that we evaluated are not suitable for fully automated vulnerability scanning because the false positive and false negative rates are too high to likely be useful in practice. However, we do find that the GPT models perform surprisingly well at automated vulnerability detection for some of the test cases, in particular surpassing random sampling, and being able to identify the exact lines of code that are vulnerable albeit at a low success rate. The best performing GPT model result found was Llama-2-70b-chat-hf with inference temperature of 0.1 applied to NIST SARD test case 149165 (which is an example of a buffer overflow vulnerability), which had a binary classification recall score of 1.0 and a precision of 1.0 for correctly and uniquely identifying the vulnerable line of code and the correct CWE number.
Read more8/2/2024
💬
0
Finetuning Large Language Models for Vulnerability Detection
Alexey Shestov, Rodion Levichev, Ravil Mussabayev, Evgeny Maslov, Anton Cheshkov, Pavel Zadorozhny
This paper presents the results of finetuning large language models (LLMs) for the task of detecting vulnerabilities in source code. We leverage WizardCoder, a recent improvement of the state-of-the-art LLM StarCoder, and adapt it for vulnerability detection through further finetuning. To accelerate training, we modify WizardCoder's training procedure, also we investigate optimal training regimes. For the imbalanced dataset with many more negative examples than positive, we also explore different techniques to improve classification performance. The finetuned WizardCoder model achieves improvement in ROC AUC and F1 measures on balanced and imbalanced vulnerability datasets over CodeBERT-like model, demonstrating the effectiveness of adapting pretrained LLMs for vulnerability detection in source code. The key contributions are finetuning the state-of-the-art code LLM, WizardCoder, increasing its training speed without the performance harm, optimizing the training procedure and regimes, handling class imbalance, and improving performance on difficult vulnerability detection datasets. This demonstrates the potential for transfer learning by finetuning large pretrained language models for specialized source code analysis tasks.
Read more7/30/2024