Comparison of Three Programming Error Measures for Explaining Variability in CS1 Grades
2404.05988
0
0

Abstract
Programming courses can be challenging for first year university students, especially for those without prior coding experience. Students initially struggle with code syntax, but as more advanced topics are introduced across a semester, the difficulty in learning to program shifts to learning computational thinking (e.g., debugging strategies). This study examined the relationships between students' rate of programming errors and their grades on two exams. Using an online integrated development environment, data were collected from 280 students in a Java programming course. The course had two parts. The first focused on introductory procedural programming and culminated with exam 1, while the second part covered more complex topics and object-oriented programming and ended with exam 2. To measure students' programming abilities, 51095 code snapshots were collected from students while they completed assignments that were autograded based on unit tests. Compiler and runtime errors were extracted from the snapshots, and three measures -- Error Count, Error Quotient and Repeated Error Density -- were explored to identify the best measure explaining variability in exam grades. Models utilizing Error Quotient outperformed the models using the other two measures, in terms of the explained variability in grades and Bayesian Information Criterion. Compiler errors were significant predictors of exam 1 grades but not exam 2 grades; only runtime errors significantly predicted exam 2 grades. The findings indicate that leveraging Error Quotient with multiple error types (compiler and runtime) may be a better measure of students' introductory programming abilities, though still not explaining most of the observed variability.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper compares three different measures of programming errors to understand their ability to explain variability in grades for an introductory computer science (CS1) course.
- The three measures are: outcome-based, behavioral, and a hybrid approach combining both.
- The researchers analyzed data from a large CS1 course to evaluate the effectiveness of these measures in predicting student performance.
Plain English Explanation
The paper looks at different ways to measure how well students are learning to program in an introductory computer science course. One common way is to look at their final grades or exam scores - this is called an "outcome-based" measure. Another approach is to look at the specific mistakes or errors students make when writing code - this is a "behavioral" measure.
The researchers in this study tried a combination of these two approaches, using both outcome and behavioral data, to see if it could better explain why some students do better than others in the course. They analyzed data from a large CS1 class to compare the effectiveness of these three different measurement methods.
The key idea is that by understanding what types of programming errors students make, instructors may be able to better tailor their teaching to address common challenges and improve student learning. The paper provides insight into which error measures are most useful for predicting and explaining student performance in introductory programming courses.
Technical Explanation
The paper examines three different measures of programming errors to understand their ability to explain variability in grades for an introductory computer science (CS1) course:
- Outcome-based measure: This focuses on the final program outputs or grade-related outcomes.
- Behavioral measure: This looks at the specific programming errors or mistakes students make during the coding process.
- Hybrid measure: This combines both outcome and behavioral data to capture a more comprehensive picture.
The researchers analyzed data from a large CS1 course, including student grades and detailed logs of their programming activities. They evaluated the predictive power of each error measure in explaining the variance in student grades using regression analysis.
The results show that the behavioral measure, which captures the types of programming errors students make, was the strongest predictor of grade variance. The hybrid approach incorporating both outcome and behavioral data also performed well. In contrast, the outcome-based measure alone was less effective at explaining the differences in student performance.
These findings suggest that understanding the specific programming mistakes students make can provide valuable insights beyond just their final grades. By identifying common error patterns, instructors may be able to develop more targeted interventions to address underlying challenges and improve learning outcomes in introductory programming courses.
Critical Analysis
The paper provides a thorough and rigorous analysis of different approaches to measuring programming errors and their relationship to student performance. However, there are a few potential limitations and areas for further research:
-
Generalizability: The study was conducted in a single CS1 course, so the findings may not generalize to other introductory programming contexts or student populations. Replicating the analysis across multiple institutions or courses would strengthen the conclusions.
-
Qualitative insights: While the quantitative analysis is valuable, complementary qualitative research could offer deeper insights into the reasons behind specific programming errors and how students perceive and approach problem-solving.
-
Longitudinal perspective: Tracking students' error patterns and learning trajectories over time, rather than a single course, could provide more nuanced understanding of how programming skills develop.
-
Instructor feedback: The study does not consider the role of instructor guidance and feedback in shaping student learning and error reduction. Integrating this factor could yield additional insights.
Overall, this paper makes an important contribution to the literature on assessing and understanding novice programmers' skill development. The findings highlight the value of analyzing behavioral data, beyond just outcome measures, to gain a more comprehensive picture of student learning.
Conclusion
This study demonstrates that examining the specific programming errors students make, rather than just their final grades, can provide valuable insights for understanding and improving introductory computer science education. The behavioral measure of errors was found to be the strongest predictor of grade variability, outperforming a more traditional outcome-based approach.
These findings suggest that instructors could benefit from closely monitoring the types of mistakes students commit during the coding process and using that information to design more targeted interventions and learning support. By gaining a deeper understanding of common error patterns, educators may be able to better address underlying challenges and foster more effective programming skill development in introductory CS courses.
Overall, this research highlights the potential of leveraging both behavioral and outcome data to gain a more holistic and actionable view of student learning, which can ultimately lead to improved educational practices and learning outcomes in computer science.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
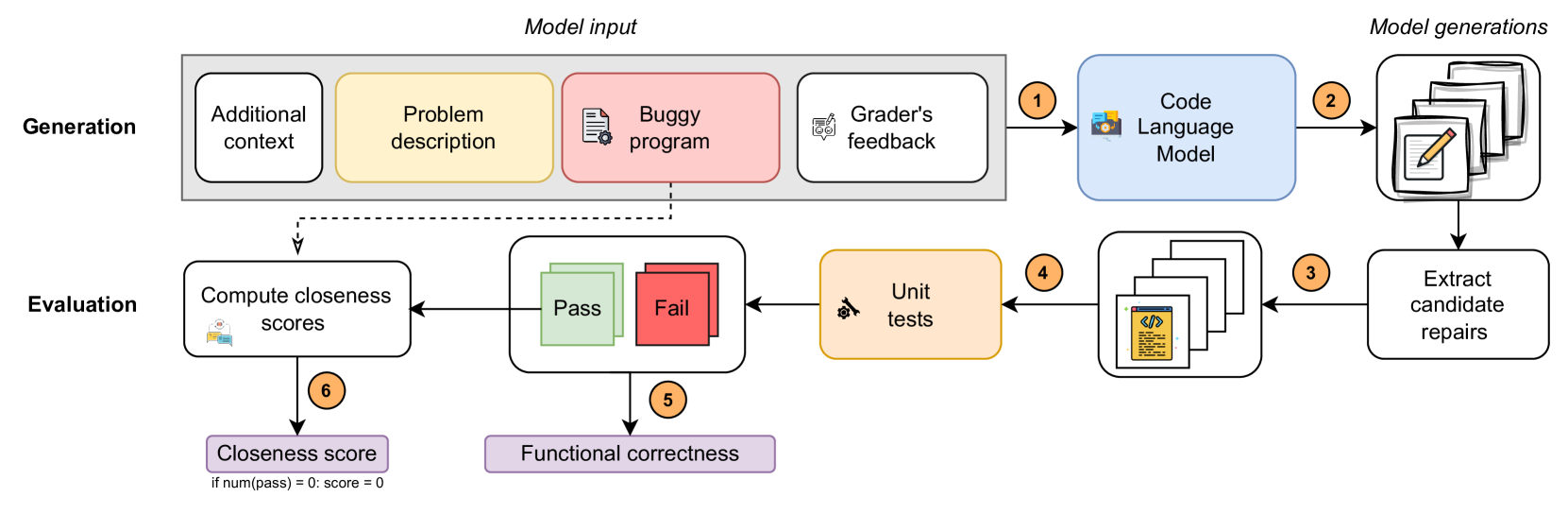
Benchmarking Educational Program Repair
Charles Koutcheme, Nicola Dainese, Sami Sarsa, Juho Leinonen, Arto Hellas, Paul Denny
0
0
The emergence of large language models (LLMs) has sparked enormous interest due to their potential application across a range of educational tasks. For example, recent work in programming education has used LLMs to generate learning resources, improve error messages, and provide feedback on code. However, one factor that limits progress within the field is that much of the research uses bespoke datasets and different evaluation metrics, making direct comparisons between results unreliable. Thus, there is a pressing need for standardization and benchmarks that facilitate the equitable comparison of competing approaches. One task where LLMs show great promise is program repair, which can be used to provide debugging support and next-step hints to students. In this article, we propose a novel educational program repair benchmark. We curate two high-quality publicly available programming datasets, present a unified evaluation procedure introducing a novel evaluation metric rouge@k for approximating the quality of repairs, and evaluate a set of five recent models to establish baseline performance.
5/10/2024
📊
Fuzzy Intelligent System for Student Software Project Evaluation
Anna Ogorodova, Pakizar Shamoi, Aron Karatayev
0
0
Developing software projects allows students to put knowledge into practice and gain teamwork skills. However, assessing student performance in project-oriented courses poses significant challenges, particularly as the size of classes increases. The current paper introduces a fuzzy intelligent system designed to evaluate academic software projects using object-oriented programming and design course as an example. To establish evaluation criteria, we first conducted a survey of student project teams (n=31) and faculty (n=3) to identify key parameters and their applicable ranges. The selected criteria - clean code, use of inheritance, and functionality - were selected as essential for assessing the quality of academic software projects. These criteria were then represented as fuzzy variables with corresponding fuzzy sets. Collaborating with three experts, including one professor and two course instructors, we defined a set of fuzzy rules for a fuzzy inference system. This system processes the input criteria to produce a quantifiable measure of project success. The system demonstrated promising results in automating the evaluation of projects. Our approach standardizes project evaluations and helps to reduce the subjective bias in manual grading.
5/2/2024
🏷️
Improving LLM Classification of Logical Errors by Integrating Error Relationship into Prompts
Yanggyu Lee, Suchae Jeong, Jihie Kim
0
0
LLMs trained in the understanding of programming syntax are now providing effective assistance to developers and are being used in programming education such as in generation of coding problem examples or providing code explanations. A key aspect of programming education is understanding and dealing with error message. However, 'logical errors' in which the program operates against the programmer's intentions do not receive error messages from the compiler. In this study, building on existing research on programming errors, we first define the types of logical errors that can occur in programming in general. Based on the definition, we propose an effective approach for detecting logical errors with LLMs that makes use of relations among error types in the Chain-of-Thought and Tree-of-Thought prompts. The experimental results indicate that when such logical error descriptions in the prompt are used, the average classifition performance is about 21% higher than the ones without them. We also conducted an experiment for exploiting the relations among errors in generating a new logical error dataset using LLMs. As there is very limited dataset for logical errors such benchmark dataset can be very useful for various programming related applications. We expect that our work can assist novice programmers in identifying the causes of code errors and correct them more effectively.
5/2/2024
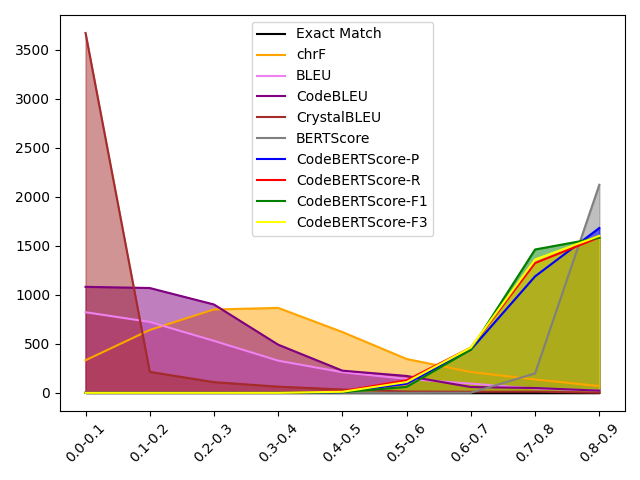
On the Limitations of Embedding Based Methods for Measuring Functional Correctness for Code Generation
Atharva Naik
0
0
The task of code generation from natural language (NL2Code) has become extremely popular, especially with the advent of Large Language Models (LLMs). However, efforts to quantify and track this progress have suffered due to a lack of reliable metrics for functional correctness. While popular benchmarks like HumanEval have test cases to enable reliable evaluation of correctness, it is time-consuming and requires human effort to collect test cases. As an alternative several reference-based evaluation metrics have been proposed, with embedding-based metrics like CodeBERTScore being touted as having a high correlation with human preferences and functional correctness. In our work, we analyze the ability of embedding-based metrics like CodeBERTScore to measure functional correctness and other helpful constructs like editing effort by analyzing outputs of ten models over two popular code generation benchmarks. Our results show that while they have a weak correlation with functional correctness (0.16), they are strongly correlated (0.72) with editing effort.
5/6/2024