The RealHumanEval: Evaluating Large Language Models' Abilities to Support Programmers
2404.02806
0
0
Abstract
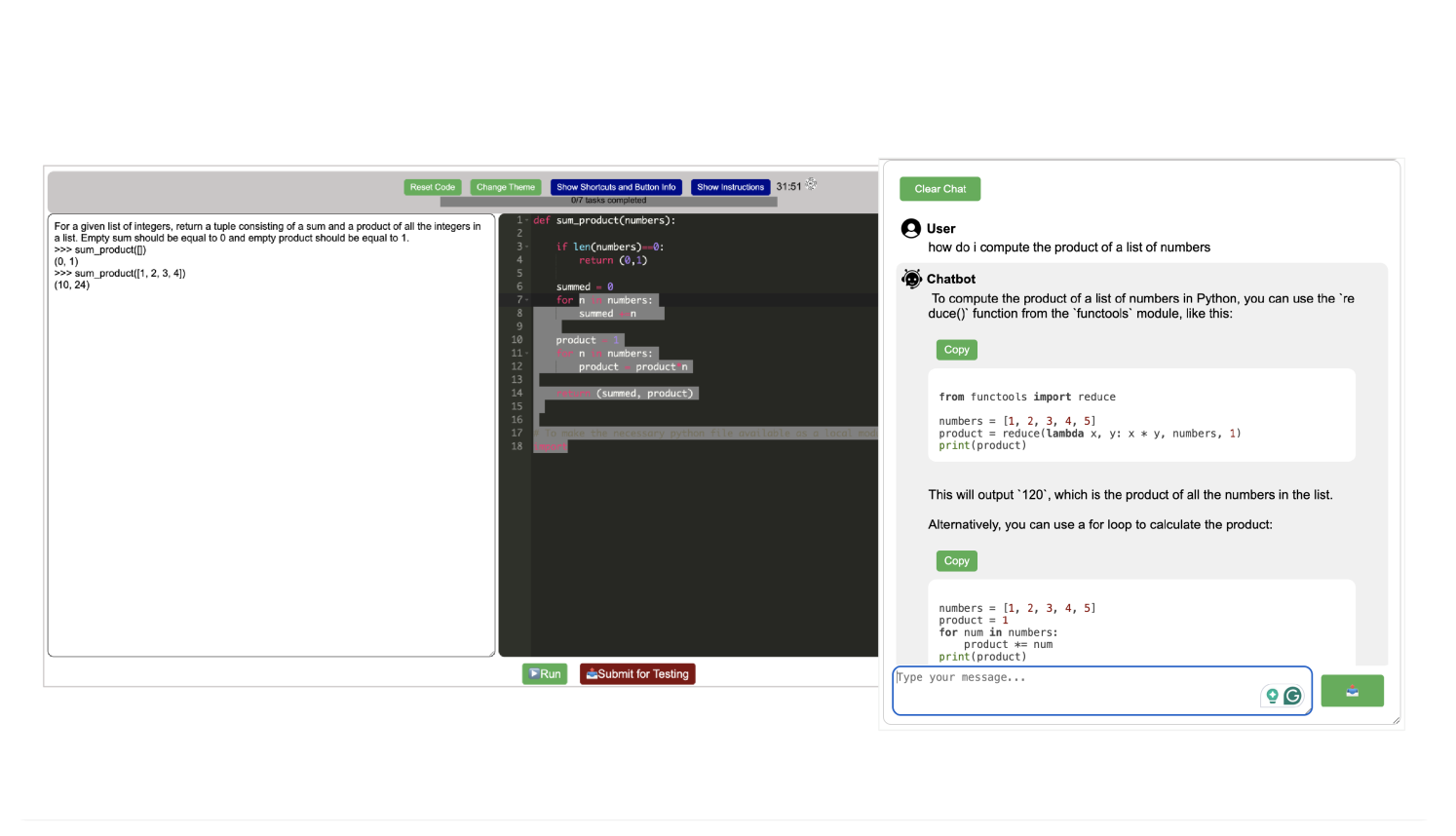
Evaluation of large language models (LLMs) for code has primarily relied on static benchmarks, including HumanEval (Chen et al., 2021), which measure the ability of LLMs to generate complete code that passes unit tests. As LLMs are increasingly used as programmer assistants, we study whether gains on existing benchmarks translate to gains in programmer productivity when coding with LLMs, including time spent coding. In addition to static benchmarks, we investigate the utility of preference metrics that might be used as proxies to measure LLM helpfulness, such as code acceptance or copy rates. To do so, we introduce RealHumanEval, a web interface to measure the ability of LLMs to assist programmers, through either autocomplete or chat support. We conducted a user study (N=213) using RealHumanEval in which users interacted with six LLMs of varying base model performance. Despite static benchmarks not incorporating humans-in-the-loop, we find that improvements in benchmark performance lead to increased programmer productivity; however gaps in benchmark versus human performance are not proportional -- a trend that holds across both forms of LLM support. In contrast, we find that programmer preferences do not correlate with their actual performance, motivating the need for better, human-centric proxy signals. We also open-source RealHumanEval to enable human-centric evaluation of new models and the study data to facilitate efforts to improve code models.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces the RealHumanEval benchmark, a new tool for evaluating the abilities of large language models to assist programmers.
- The benchmark consists of a set of programming tasks that were originally completed by human programmers, allowing models to be tested on real-world, open-ended programming challenges.
- The authors evaluate several prominent language models on the RealHumanEval and provide insights into the models' capabilities and limitations when it comes to supporting programmers.
Plain English Explanation
The RealHumanEval benchmark aims to test how well large language models, such as ChatGPT, can assist human programmers. Rather than using simplified or artificial programming tasks, the benchmark consists of real-world coding challenges that were originally completed by people.
This is an important distinction, as it allows the researchers to get a more realistic sense of how these AI models would perform when trying to help programmers with their actual work. The tasks cover a wide range of programming concepts and difficulty levels, giving a comprehensive view of the models' capabilities.
By evaluating several prominent language models on the RealHumanEval, the researchers were able to identify both the strengths and weaknesses of these systems when it comes to assisting programmers. This provides valuable insights that can help guide the development of future AI tools to better support software engineers and developers.
Technical Explanation
The paper introduces the RealHumanEval benchmark, which consists of a set of 164 programming problems originally completed by human programmers. These tasks cover a variety of programming concepts and difficulty levels, allowing the researchers to thoroughly evaluate the capabilities of large language models.
The authors assess the performance of several prominent models, including GPT-3, InstructGPT, and Anthropic's Claude, on the RealHumanEval. The models are asked to both generate solutions to the programming problems as well as provide step-by-step explanations of their approaches.
The results show that the language models are able to generate correct solutions for many of the easier tasks, demonstrating an understanding of fundamental programming constructs. However, the models struggle more with the more complex, open-ended problems that require deeper reasoning and problem-solving skills.
Additionally, the authors find that the models' ability to provide clear, step-by-step explanations of their solutions is more limited. This suggests that while the models can generate functional code, they may have difficulty truly understanding and articulating the underlying logic in a way that would be most helpful for human programmers.
Critical Analysis
The RealHumanEval benchmark represents an important step forward in evaluating the real-world capabilities of large language models when it comes to supporting programmers. By using a diverse set of tasks originally completed by humans, the benchmark provides a more realistic assessment compared to simpler, artificial programming challenges.
However, the paper acknowledges that the benchmark may not capture all the ways in which language models could potentially assist programmers. For example, the tasks do not test the models' ability to understand and work with existing codebases, which is a crucial skill for professional developers.
Additionally, while the evaluation covers a range of programming concepts, the tasks are still relatively narrow in scope compared to the breadth of real-world programming work. Further research may be needed to understand how these models would perform on an even wider variety of programming challenges.
It's also worth noting that the paper does not delve deeply into the potential biases or limitations of the language models themselves. As these systems become more prevalent in software development workflows, it will be important to carefully scrutinize their decision-making processes and potential shortcomings.
Conclusion
The RealHumanEval benchmark represents an important step forward in evaluating the real-world capabilities of large language models when it comes to supporting programmers. By using a diverse set of tasks originally completed by humans, the benchmark provides a more realistic assessment of these models' strengths and weaknesses.
The results suggest that while language models can generate functional code for many programming problems, they still struggle with more complex, open-ended tasks that require deeper reasoning and problem-solving skills. Additionally, the models' ability to provide clear, step-by-step explanations of their solutions is more limited, which could hinder their usefulness in truly supporting human programmers.
As these AI systems continue to be integrated into software development workflows, it will be crucial to thoroughly evaluate their capabilities and limitations to ensure they are used responsibly and effectively. The RealHumanEval benchmark represents an important step in that direction, and the insights it provides can help guide the development of future AI tools to better support programmers and software engineers.
Related Papers

METAL: Towards Multilingual Meta-Evaluation
Rishav Hada, Varun Gumma, Mohamed Ahmed, Kalika Bali, Sunayana Sitaram
0
0
With the rising human-like precision of Large Language Models (LLMs) in numerous tasks, their utilization in a variety of real-world applications is becoming more prevalent. Several studies have shown that LLMs excel on many standard NLP benchmarks. However, it is challenging to evaluate LLMs due to test dataset contamination and the limitations of traditional metrics. Since human evaluations are difficult to collect, there is a growing interest in the community to use LLMs themselves as reference-free evaluators for subjective metrics. However, past work has shown that LLM-based evaluators can exhibit bias and have poor alignment with human judgments. In this study, we propose a framework for an end-to-end assessment of LLMs as evaluators in multilingual scenarios. We create a carefully curated dataset, covering 10 languages containing native speaker judgments for the task of summarization. This dataset is created specifically to evaluate LLM-based evaluators, which we refer to as meta-evaluation (METAL). We compare the performance of LLM-based evaluators created using GPT-3.5-Turbo, GPT-4, and PaLM2. Our results indicate that LLM-based evaluators based on GPT-4 perform the best across languages, while GPT-3.5-Turbo performs poorly. Additionally, we perform an analysis of the reasoning provided by LLM-based evaluators and find that it often does not match the reasoning provided by human judges.
4/3/2024
🚀
NaturalCodeBench: Examining Coding Performance Mismatch on HumanEval and Natural User Prompts
Shudan Zhang, Hanlin Zhao, Xiao Liu, Qinkai Zheng, Zehan Qi, Xiaotao Gu, Xiaohan Zhang, Yuxiao Dong, Jie Tang
0
0
Large language models (LLMs) have manifested strong ability to generate codes for productive activities. However, current benchmarks for code synthesis, such as HumanEval, MBPP, and DS-1000, are predominantly oriented towards introductory tasks on algorithm and data science, insufficiently satisfying challenging requirements prevalent in real-world coding. To fill this gap, we propose NaturalCodeBench (NCB), a challenging code benchmark designed to mirror the complexity and variety of scenarios in real coding tasks. NCB comprises 402 high-quality problems in Python and Java, meticulously selected from natural user queries from online coding services, covering 6 different domains. Noting the extraordinary difficulty in creating testing cases for real-world queries, we also introduce a semi-automated pipeline to enhance the efficiency of test case construction. Comparing with manual solutions, it achieves an efficiency increase of more than 4 times. Our systematic experiments on 39 LLMs find that performance gaps on NCB between models with close HumanEval scores could still be significant, indicating a lack of focus on practical code synthesis scenarios or over-specified optimization on HumanEval. On the other hand, even the best-performing GPT-4 is still far from satisfying on NCB. The evaluation toolkit and development set are available at https://github.com/THUDM/NaturalCodeBench.
5/8/2024
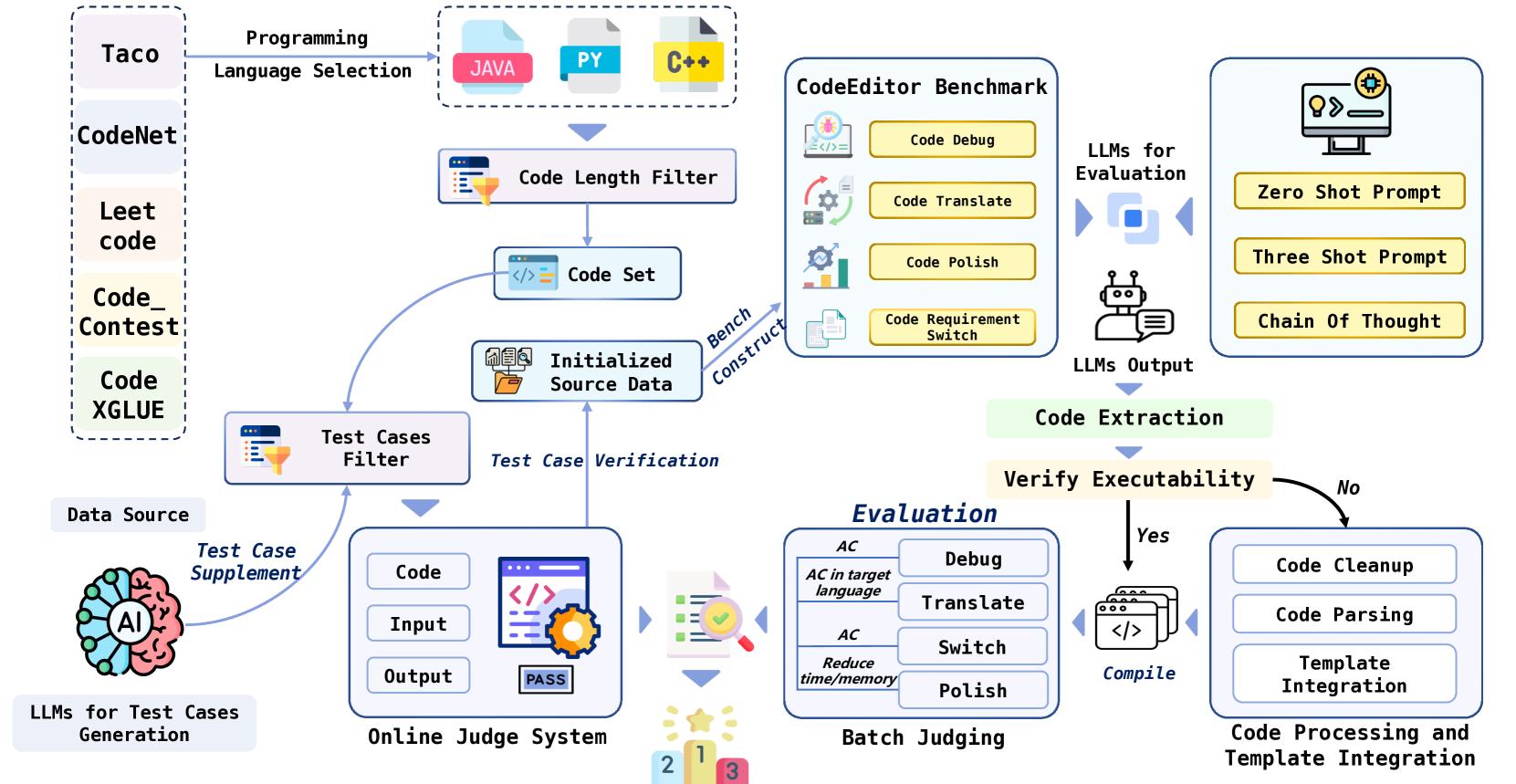
CodeEditorBench: Evaluating Code Editing Capability of Large Language Models
Jiawei Guo, Ziming Li, Xueling Liu, Kaijing Ma, Tianyu Zheng, Zhouliang Yu, Ding Pan, Yizhi LI, Ruibo Liu, Yue Wang, Shuyue Guo, Xingwei Qu, Xiang Yue, Ge Zhang, Wenhu Chen, Jie Fu
0
0
Large Language Models (LLMs) for code are rapidly evolving, with code editing emerging as a critical capability. We introduce CodeEditorBench, an evaluation framework designed to rigorously assess the performance of LLMs in code editing tasks, including debugging, translating, polishing, and requirement switching. Unlike existing benchmarks focusing solely on code generation, CodeEditorBench emphasizes real-world scenarios and practical aspects of software development. We curate diverse coding challenges and scenarios from five sources, covering various programming languages, complexity levels, and editing tasks. Evaluation of 19 LLMs reveals that closed-source models (particularly Gemini-Ultra and GPT-4), outperform open-source models in CodeEditorBench, highlighting differences in model performance based on problem types and prompt sensitivities. CodeEditorBench aims to catalyze advancements in LLMs by providing a robust platform for assessing code editing capabilities. We will release all prompts and datasets to enable the community to expand the dataset and benchmark emerging LLMs. By introducing CodeEditorBench, we contribute to the advancement of LLMs in code editing and provide a valuable resource for researchers and practitioners.
4/9/2024
🚀
Who Validates the Validators? Aligning LLM-Assisted Evaluation of LLM Outputs with Human Preferences
Shreya Shankar, J. D. Zamfirescu-Pereira, Bjorn Hartmann, Aditya G. Parameswaran, Ian Arawjo
0
0
Due to the cumbersome nature of human evaluation and limitations of code-based evaluation, Large Language Models (LLMs) are increasingly being used to assist humans in evaluating LLM outputs. Yet LLM-generated evaluators simply inherit all the problems of the LLMs they evaluate, requiring further human validation. We present a mixed-initiative approach to ``validate the validators'' -- aligning LLM-generated evaluation functions (be it prompts or code) with human requirements. Our interface, EvalGen, provides automated assistance to users in generating evaluation criteria and implementing assertions. While generating candidate implementations (Python functions, LLM grader prompts), EvalGen asks humans to grade a subset of LLM outputs; this feedback is used to select implementations that better align with user grades. A qualitative study finds overall support for EvalGen but underscores the subjectivity and iterative process of alignment. In particular, we identify a phenomenon we dub emph{criteria drift}: users need criteria to grade outputs, but grading outputs helps users define criteria. What is more, some criteria appears emph{dependent} on the specific LLM outputs observed (rather than independent criteria that can be defined emph{a priori}), raising serious questions for approaches that assume the independence of evaluation from observation of model outputs. We present our interface and implementation details, a comparison of our algorithm with a baseline approach, and implications for the design of future LLM evaluation assistants.
4/19/2024