The Comparison of Translationese in Machine Translation and Human Transation in terms of Translation Relations

0
Sign in to get full access
Overview
- Compares the language patterns in machine-translated and human-translated texts
- Investigates how translation methods impact the "translationese" (language that sounds like a translation) of the final text
- Examines the relationship between translation quality and the degree of translationese
Plain English Explanation
This research paper compares the linguistic characteristics of texts that have been translated by machines versus texts translated by human translators. The researchers wanted to understand how the translation method impacts the "translationese" - the subtle ways that translated text can sound different from naturally written text.
They looked at various linguistic features, such as word order, vocabulary choices, and grammatical structures, to see how machine-translated and human-translated texts differ in terms of their "translationese." The goal was to provide insights into the relationship between translation quality and the degree of translationese present in the final text.
This research is relevant for understanding the capabilities and limitations of machine translation as well as developing better translation evaluation metrics. It could also have implications for translating low-resource languages and the future of machine translation.
Technical Explanation
The researchers conducted a comparative analysis of machine-translated and human-translated texts across several language pairs. They examined a range of linguistic features, including lexical, syntactic, and semantic characteristics, to quantify the degree of translationese present in each type of translation.
The experiment design involved collecting a corpus of source texts and their corresponding machine-translated and human-translated versions. They then applied various computational linguistic techniques to analyze the textual features and differences between the machine-translated and human-translated outputs.
The key findings indicate that machine-translated texts tend to exhibit a higher degree of translationese compared to human-translated texts. This was evidenced by more pronounced patterns in the machine-translated texts, such as more literal word-for-word translations, less natural-sounding sentence structures, and a higher frequency of certain linguistic constructs.
The researchers also found that the degree of translationese was inversely correlated with translation quality, as assessed by human evaluation. Texts with lower translationese tended to be rated as higher quality translations.
These insights contribute to our understanding of the limitations of current machine translation systems and the challenges in developing more natural-sounding machine-translated output.
Critical Analysis
The paper provides a well-designed and thorough analysis of translationese in machine-translated and human-translated texts. However, the study is limited to a specific set of language pairs and text genres, which may limit the generalizability of the findings.
Additionally, the researchers acknowledge that the assessment of translation quality is inherently subjective, and the human evaluation process may have introduced some biases. Further research could explore more objective metrics for measuring translation quality and its relationship to translationese.
It would also be interesting to investigate how the findings might apply to specialized domains or low-resource language pairs, where the challenges of machine translation are even more pronounced.
Conclusion
This research provides valuable insights into the linguistic characteristics of machine-translated and human-translated texts, highlighting the differences in the degree of translationese. The findings suggest that reducing translationese is an important consideration in improving the quality and naturalness of machine translation.
The study contributes to our understanding of the current limitations of machine translation and the ongoing need for advancements in this field. The insights gained from this research could inform the development of better translation evaluation metrics and the design of more natural-sounding machine translation systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
The Comparison of Translationese in Machine Translation and Human Transation in terms of Translation Relations
Fan Zhou
This study explores the distinctions between neural machine translation (NMT) and human translation (HT) through the lens of translation relations. It benchmarks HT to assess the translation techniques produced by an NMT system and aims to address three key research questions: the differences in overall translation relations between NMT and HT, how each utilizes non-literal translation techniques, and the variations in factors influencing their use of specific non-literal techniques. The research employs two parallel corpora, each spanning nine genres with the same source texts with one translated by NMT and the other by humans. Translation relations in these corpora are manually annotated on aligned pairs, enabling a comparative analysis that draws on linguistic insights, including semantic and syntactic nuances such as hypernyms and alterations in part-of-speech tagging. The results indicate that NMT relies on literal translation significantly more than HT across genres. While NMT performs comparably to HT in employing syntactic non-literal translation techniques, it falls behind in semantic-level performance.
Read more4/16/2024

0
Convergences and Divergences between Automatic Assessment and Human Evaluation: Insights from Comparing ChatGPT-Generated Translation and Neural Machine Translation
Zhaokun Jiang, Ziyin Zhang
Large language models have demonstrated parallel and even superior translation performance compared to neural machine translation (NMT) systems. However, existing comparative studies between them mainly rely on automated metrics, raising questions into the feasibility of these metrics and their alignment with human judgment. The present study investigates the convergences and divergences between automated metrics and human evaluation in assessing the quality of machine translation from ChatGPT and three NMT systems. To perform automatic assessment, four automated metrics are employed, while human evaluation incorporates the DQF-MQM error typology and six rubrics. Notably, automatic assessment and human evaluation converge in measuring formal fidelity (e.g., error rates), but diverge when evaluating semantic and pragmatic fidelity, with automated metrics failing to capture the improvement of ChatGPT's translation brought by prompt engineering. These results underscore the indispensable role of human judgment in evaluating the performance of advanced translation tools at the current stage.
Read more4/24/2024

0
Exploring the Correlation between Human and Machine Evaluation of Simultaneous Speech Translation
Xiaoman Wang, Claudio Fantinuoli
Assessing the performance of interpreting services is a complex task, given the nuanced nature of spoken language translation, the strategies that interpreters apply, and the diverse expectations of users. The complexity of this task become even more pronounced when automated evaluation methods are applied. This is particularly true because interpreted texts exhibit less linearity between the source and target languages due to the strategies employed by the interpreter. This study aims to assess the reliability of automatic metrics in evaluating simultaneous interpretations by analyzing their correlation with human evaluations. We focus on a particular feature of interpretation quality, namely translation accuracy or faithfulness. As a benchmark we use human assessments performed by language experts, and evaluate how well sentence embeddings and Large Language Models correlate with them. We quantify semantic similarity between the source and translated texts without relying on a reference translation. The results suggest GPT models, particularly GPT-3.5 with direct prompting, demonstrate the strongest correlation with human judgment in terms of semantic similarity between source and target texts, even when evaluating short textual segments. Additionally, the study reveals that the size of the context window has a notable impact on this correlation.
Read more6/17/2024
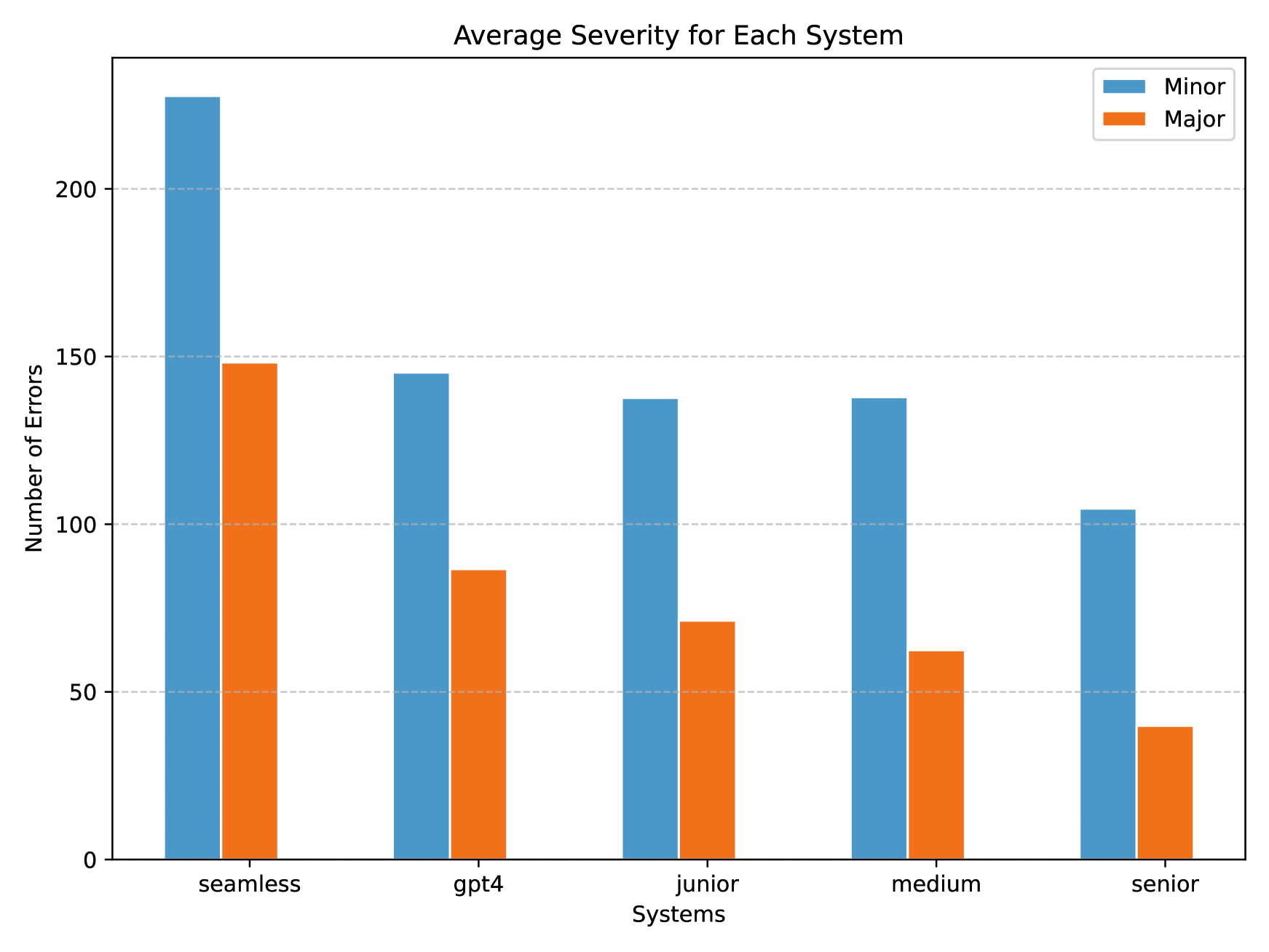
0
GPT-4 vs. Human Translators: A Comprehensive Evaluation of Translation Quality Across Languages, Domains, and Expertise Levels
Jianhao Yan, Pingchuan Yan, Yulong Chen, Judy Li, Xianchao Zhu, Yue Zhang
This study comprehensively evaluates the translation quality of Large Language Models (LLMs), specifically GPT-4, against human translators of varying expertise levels across multiple language pairs and domains. Through carefully designed annotation rounds, we find that GPT-4 performs comparably to junior translators in terms of total errors made but lags behind medium and senior translators. We also observe the imbalanced performance across different languages and domains, with GPT-4's translation capability gradually weakening from resource-rich to resource-poor directions. In addition, we qualitatively study the translation given by GPT-4 and human translators, and find that GPT-4 translator suffers from literal translations, but human translators sometimes overthink the background information. To our knowledge, this study is the first to evaluate LLMs against human translators and analyze the systematic differences between their outputs, providing valuable insights into the current state of LLM-based translation and its potential limitations.
Read more7/8/2024