Convergences and Divergences between Automatic Assessment and Human Evaluation: Insights from Comparing ChatGPT-Generated Translation and Neural Machine Translation

0

Sign in to get full access
Overview
- This paper compares the performance of ChatGPT, a large language model (LLM), to neural machine translation (NMT) systems in translating text.
- The researchers evaluate the translations produced by ChatGPT and NMT models on various metrics, including fluency, adequacy, and faithfulness to the original text.
- The findings suggest that ChatGPT can rival or even outperform professional human translators and state-of-the-art NMT systems in certain translation tasks.
Plain English Explanation
The researchers wanted to see how well ChatGPT, a powerful language AI model, could perform at translating text compared to traditional neural machine translation (NMT) systems. NMT is a common way to automatically translate text from one language to another, but the researchers wanted to see if ChatGPT could match or even exceed the performance of these specialized translation models.
To do this, they had ChatGPT and various NMT systems translate different texts and then evaluated the quality of the translations. They looked at factors like how fluent and natural the translations sounded, how well they captured the meaning of the original text, and how faithfully they reproduced the content.
The results were quite surprising - in many cases, ChatGPT was able to produce translations that were just as good as or even better than those from professional human translators and state-of-the-art NMT systems. This suggests that large language models like ChatGPT could potentially rival or even replace traditional machine translation approaches in certain scenarios.
Technical Explanation
The researchers first collected a diverse set of text samples spanning various domains, including news articles, blog posts, and technical documents. They then had ChatGPT and several NMT models, including METAL and industry-leading systems, translate these texts from one language to another.
Next, the translations were evaluated by professional human raters on metrics such as fluency, adequacy, and faithfulness to the original text. The researchers also compared the translations to human-generated reference translations to assess their quality.
The results showed that in many cases, ChatGPT's translations were on par with or even surpassed the performance of the NMT systems, particularly in terms of fluency and naturalness. The researchers also found that ChatGPT's translations were often more faithful to the original text than those produced by the NMT models.
Critical Analysis
The researchers acknowledge several limitations and caveats to their study. For instance, the text samples used were relatively short, and the study did not cover certain specialized domains like legal or medical texts, where NMT systems may still have an advantage.
Additionally, the researchers note that the performance of ChatGPT may be heavily dependent on the specific prompts and instructions given to the model. Further research is needed to explore the full capabilities and limitations of ChatGPT in translation tasks.
While the results are promising, it's important to remember that ChatGPT is a general-purpose language model, not a specialized translation system. In certain high-stakes or mission-critical translation scenarios, the robustness and predictability of traditional NMT systems may still be preferred.
Conclusion
The findings of this study suggest that large language models like ChatGPT have the potential to rival or even outperform state-of-the-art neural machine translation systems in various translation tasks. This has significant implications for the field of machine translation and could potentially lead to the development of more flexible and versatile translation tools.
However, further research is needed to fully understand the capabilities and limitations of these models, as well as their suitability for different translation use cases. As with any technology, it's important to carefully evaluate the performance and reliability of these systems before deploying them in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Convergences and Divergences between Automatic Assessment and Human Evaluation: Insights from Comparing ChatGPT-Generated Translation and Neural Machine Translation
Zhaokun Jiang, Ziyin Zhang
Large language models have demonstrated parallel and even superior translation performance compared to neural machine translation (NMT) systems. However, existing comparative studies between them mainly rely on automated metrics, raising questions into the feasibility of these metrics and their alignment with human judgment. The present study investigates the convergences and divergences between automated metrics and human evaluation in assessing the quality of machine translation from ChatGPT and three NMT systems. To perform automatic assessment, four automated metrics are employed, while human evaluation incorporates the DQF-MQM error typology and six rubrics. Notably, automatic assessment and human evaluation converge in measuring formal fidelity (e.g., error rates), but diverge when evaluating semantic and pragmatic fidelity, with automated metrics failing to capture the improvement of ChatGPT's translation brought by prompt engineering. These results underscore the indispensable role of human judgment in evaluating the performance of advanced translation tools at the current stage.
Read more4/24/2024

0
Exploring the Correlation between Human and Machine Evaluation of Simultaneous Speech Translation
Xiaoman Wang, Claudio Fantinuoli
Assessing the performance of interpreting services is a complex task, given the nuanced nature of spoken language translation, the strategies that interpreters apply, and the diverse expectations of users. The complexity of this task become even more pronounced when automated evaluation methods are applied. This is particularly true because interpreted texts exhibit less linearity between the source and target languages due to the strategies employed by the interpreter. This study aims to assess the reliability of automatic metrics in evaluating simultaneous interpretations by analyzing their correlation with human evaluations. We focus on a particular feature of interpretation quality, namely translation accuracy or faithfulness. As a benchmark we use human assessments performed by language experts, and evaluate how well sentence embeddings and Large Language Models correlate with them. We quantify semantic similarity between the source and translated texts without relying on a reference translation. The results suggest GPT models, particularly GPT-3.5 with direct prompting, demonstrate the strongest correlation with human judgment in terms of semantic similarity between source and target texts, even when evaluating short textual segments. Additionally, the study reveals that the size of the context window has a notable impact on this correlation.
Read more6/17/2024

0
Evaluating Automatic Metrics with Incremental Machine Translation Systems
Guojun Wu, Shay B. Cohen, Rico Sennrich
We introduce a dataset comprising commercial machine translations, gathered weekly over six years across 12 translation directions. Since human A/B testing is commonly used, we assume commercial systems improve over time, which enables us to evaluate machine translation (MT) metrics based on their preference for more recent translations. Our study confirms several previous findings in MT metrics research and demonstrates the dataset's value as a testbed for metric evaluation. We release our code at https://github.com/gjwubyron/Evo
Read more7/4/2024
0
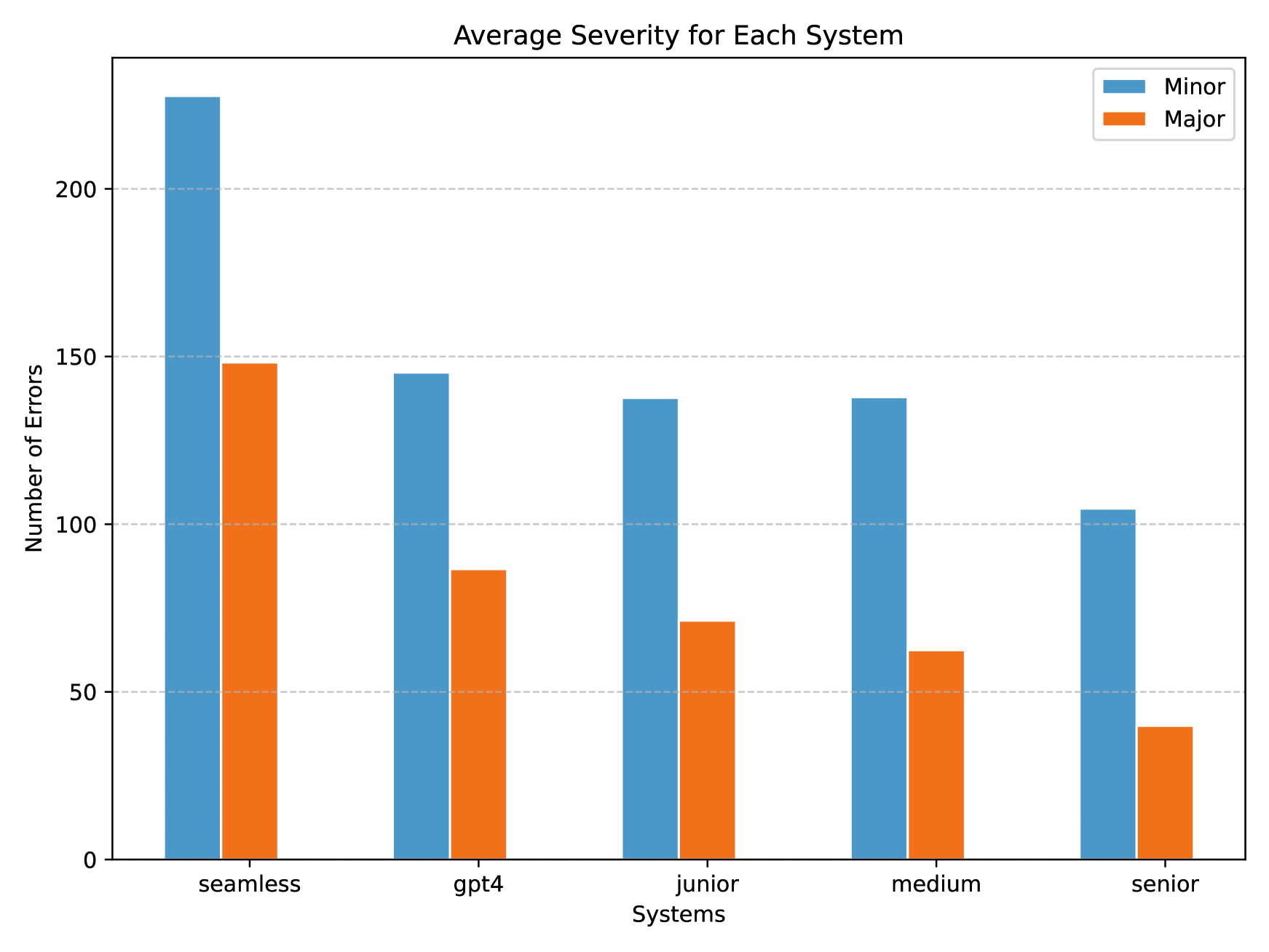
GPT-4 vs. Human Translators: A Comprehensive Evaluation of Translation Quality Across Languages, Domains, and Expertise Levels
Jianhao Yan, Pingchuan Yan, Yulong Chen, Judy Li, Xianchao Zhu, Yue Zhang
This study comprehensively evaluates the translation quality of Large Language Models (LLMs), specifically GPT-4, against human translators of varying expertise levels across multiple language pairs and domains. Through carefully designed annotation rounds, we find that GPT-4 performs comparably to junior translators in terms of total errors made but lags behind medium and senior translators. We also observe the imbalanced performance across different languages and domains, with GPT-4's translation capability gradually weakening from resource-rich to resource-poor directions. In addition, we qualitatively study the translation given by GPT-4 and human translators, and find that GPT-4 translator suffers from literal translations, but human translators sometimes overthink the background information. To our knowledge, this study is the first to evaluate LLMs against human translators and analyze the systematic differences between their outputs, providing valuable insights into the current state of LLM-based translation and its potential limitations.
Read more7/8/2024