A Comprehensive Study of Machine Learning Techniques for Log-Based Anomaly Detection

0
❗
Sign in to get full access
Overview
- This paper presents a comprehensive empirical study that evaluates supervised and semi-supervised, traditional and deep machine learning (ML) techniques for log-based anomaly detection (LAD).
- The researchers assess the techniques based on four criteria: detection accuracy, time performance, sensitivity of detection accuracy and time performance to hyperparameter tuning.
- The key findings suggest that supervised traditional and deep ML techniques perform similarly in terms of detection accuracy and prediction time, but supervised traditional ML techniques are less sensitive to hyperparameter tuning than deep learning techniques.
- Additionally, the paper finds that semi-supervised techniques yield significantly worse detection accuracy than supervised techniques.
Plain English Explanation
As the complexity of computer systems continues to grow, the need for automated techniques to analyze log files and detect anomalies has become increasingly important. Log-based Anomaly Detection (LAD) is a widely studied approach to this problem, with a focus on using deep learning techniques.
However, this paper argues that traditional machine learning (ML) techniques may also perform well in many cases, depending on the context and datasets. Additionally, semi-supervised techniques deserve attention, as they can have practical advantages over supervised techniques.
The researchers in this paper conducted a comprehensive study to evaluate both supervised and semi-supervised, traditional and deep ML techniques for LAD. They looked at four key factors:
- Detection Accuracy: How well the techniques could identify anomalies in the log data.
- Time Performance: How quickly the techniques could train and make predictions.
- Sensitivity to Hyperparameter Tuning: How much the detection accuracy and time performance depended on carefully adjusting the model's hyperparameters.
The results show that supervised traditional and deep ML techniques perform similarly in terms of detection accuracy and prediction time. However, the supervised traditional ML techniques were less sensitive to hyperparameter tuning than the deep learning techniques. This is an important practical consideration, as hyperparameter tuning can be time-consuming and challenging for engineers.
Additionally, the paper found that semi-supervised techniques, which use unlabeled data to supplement the labeled data, performed significantly worse in terms of detection accuracy compared to the supervised techniques.
Overall, this research provides valuable insights for practitioners and researchers working on log anomaly detection and anomaly detection in time series data. By evaluating a range of techniques and considering practical factors beyond just detection accuracy, the paper helps inform the selection of appropriate ML models for real-world log analysis tasks.
Technical Explanation
The paper presents a comprehensive empirical study that evaluates supervised and semi-supervised, traditional and deep machine learning (ML) techniques for the task of log-based anomaly detection (LAD). The researchers assess the techniques based on four evaluation criteria: detection accuracy, time performance (training and prediction times), and the sensitivity of detection accuracy and time performance to hyperparameter tuning.
The experiment design involved testing a variety of supervised and semi-supervised techniques, including traditional ML models (e.g., logistic regression, decision trees, random forests) and deep learning models (e.g., multilayer perceptrons, convolutional neural networks, recurrent neural networks). The researchers used several publicly available log datasets to train and evaluate the models.
The key findings from the study are:
- Supervised traditional and deep ML techniques performed similarly in terms of detection accuracy and prediction time.
- Supervised traditional ML techniques were generally less sensitive to hyperparameter tuning than deep learning techniques with respect to detection accuracy.
- Semi-supervised techniques yielded significantly worse detection accuracy compared to supervised techniques.
The researchers attribute the performance similarity between supervised traditional and deep ML techniques to the fact that deep learning's advantages may not always manifest in the context of LAD, depending on the dataset and problem at hand. The sensitivity analysis results highlight the practical importance of considering factors beyond just detection accuracy when selecting ML models for real-world log analysis tasks, as hyperparameter tuning can be time-consuming and challenging for engineers.
The paper also discusses the limitations of the study, such as the use of only publicly available datasets, and suggests directions for future research, such as exploring the effectiveness of semi-supervised techniques in different contexts or investigating the impact of log preprocessing techniques on model performance.
Critical Analysis
The paper presents a well-designed and comprehensive study that provides valuable insights into the performance of various machine learning techniques for log-based anomaly detection. The key strengths of the research include the breadth of techniques evaluated, the use of multiple datasets, and the consideration of practical factors such as time performance and sensitivity to hyperparameter tuning.
One potential limitation of the study is the use of only publicly available datasets, which may not fully capture the diversity of real-world log data. It would be interesting to see the researchers evaluate the techniques on proprietary datasets from different industries or domains to further validate the findings.
Additionally, the paper could have explored the impact of log preprocessing techniques, such as feature engineering or data transformation, on the performance of the different ML models. Effective log representation is known to be a crucial factor in the success of log-based anomaly detection, and incorporating this aspect could have provided a more comprehensive understanding of the problem.
While the paper acknowledges the limitations of focusing solely on detection accuracy as an evaluation metric, it would have been valuable to investigate other practical considerations, such as the interpretability of the models or the ease of deployment and maintenance in production environments. These factors can be crucial for real-world applications of log anomaly detection systems.
Overall, the paper presents a rigorous and insightful study that advances the understanding of machine learning techniques for log-based anomaly detection. The findings regarding the performance and sensitivity to hyperparameter tuning of supervised traditional and deep learning models, as well as the limitations of semi-supervised techniques, provide a solid foundation for future research and practical applications in this domain.
Conclusion
This comprehensive empirical study evaluates the performance of supervised and semi-supervised, traditional and deep machine learning techniques for log-based anomaly detection. The key findings suggest that supervised traditional and deep ML models perform similarly in terms of detection accuracy and time performance, but supervised traditional ML techniques are less sensitive to hyperparameter tuning than deep learning techniques.
The research highlights the importance of considering factors beyond just detection accuracy when selecting appropriate ML models for real-world log analysis tasks. By providing a deeper understanding of the trade-offs and practical considerations, this work can inform the decisions of practitioners and researchers working on log anomaly detection and broader time series anomaly detection problems.
Future research directions could explore the effectiveness of these techniques on a wider range of log data, including proprietary datasets, as well as the impact of advanced log preprocessing methods on model performance. Expanding the evaluation criteria to include factors such as model interpretability and ease of deployment could also yield valuable insights for practical applications.
Overall, this study represents a significant contribution to the field of log-based anomaly detection, offering a nuanced, empirical approach that can guide the development of more robust and practical anomaly detection systems for complex computer systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
❗
0
A Comprehensive Study of Machine Learning Techniques for Log-Based Anomaly Detection
Shan Ali, Chaima Boufaied, Domenico Bianculli, Paula Branco, Lionel Briand
Growth in system complexity increases the need for automated techniques dedicated to different log analysis tasks such as Log-based Anomaly Detection (LAD). The latter has been widely addressed in the literature, mostly by means of a variety of deep learning techniques. Despite their many advantages, that focus on deep learning techniques is somewhat arbitrary as traditional Machine Learning (ML) techniques may perform well in many cases, depending on the context and datasets. In the same vein, semi-supervised techniques deserve the same attention as supervised techniques since the former have clear practical advantages. Further, current evaluations mostly rely on the assessment of detection accuracy. However, this is not enough to decide whether or not a specific ML technique is suitable to address the LAD problem in a given context. Other aspects to consider include training and prediction times as well as the sensitivity to hyperparameter tuning, which in practice matters to engineers. In this paper, we present a comprehensive empirical study, in which we evaluate supervised and semi-supervised, traditional and deep ML techniques w.r.t. four evaluation criteria: detection accuracy, time performance, sensitivity of detection accuracy and time performance to hyperparameter tuning. The experimental results show that supervised traditional and deep ML techniques fare similarly in terms of their detection accuracy and prediction time. Moreover, overall, sensitivity analysis to hyperparameter tuning w.r.t. detection accuracy shows that supervised traditional ML techniques are less sensitive than deep learning techniques. Further, semi-supervised techniques yield significantly worse detection accuracy than supervised techniques.
Read more5/21/2024
❗
0
On the Effectiveness of Log Representation for Log-based Anomaly Detection
Xingfang Wu, Heng Li, Foutse Khomh
Logs are an essential source of information for people to understand the running status of a software system. Due to the evolving modern software architecture and maintenance methods, more research efforts have been devoted to automated log analysis. In particular, machine learning (ML) has been widely used in log analysis tasks. In ML-based log analysis tasks, converting textual log data into numerical feature vectors is a critical and indispensable step. However, the impact of using different log representation techniques on the performance of the downstream models is not clear, which limits researchers and practitioners' opportunities of choosing the optimal log representation techniques in their automated log analysis workflows. Therefore, this work investigates and compares the commonly adopted log representation techniques from previous log analysis research. Particularly, we select six log representation techniques and evaluate them with seven ML models and four public log datasets (i.e., HDFS, BGL, Spirit and Thunderbird) in the context of log-based anomaly detection. We also examine the impacts of the log parsing process and the different feature aggregation approaches when they are employed with log representation techniques. From the experiments, we provide some heuristic guidelines for future researchers and developers to follow when designing an automated log analysis workflow. We believe our comprehensive comparison of log representation techniques can help researchers and practitioners better understand the characteristics of different log representation techniques and provide them with guidance for selecting the most suitable ones for their ML-based log analysis workflow.
Read more4/9/2024

0
Semi-supervised learning via DQN for log anomaly detection
Yingying He, Xiaobing Pei
Log anomaly detection is a critical component in modern software system security and maintenance, serving as a crucial support and basis for system monitoring, operation, and troubleshooting. It aids operations personnel in timely identification and resolution of issues. However, current methods in log anomaly detection still face challenges such as underutilization of unlabeled data, imbalance between normal and anomaly class data, and high rates of false positives and false negatives, leading to insufficient effectiveness in anomaly recognition. In this study, we propose a semi-supervised log anomaly detection method named DQNLog, which integrates deep reinforcement learning to enhance anomaly detection performance by leveraging a small amount of labeled data and large-scale unlabeled data. To address issues of imbalanced data and insufficient labeling, we design a state transition function biased towards anomalies based on cosine similarity, aiming to capture semantic-similar anomalies rather than favoring the majority class. To enhance the model's capability in learning anomalies, we devise a joint reward function that encourages the model to utilize labeled anomalies and explore unlabeled anomalies, thereby reducing false positives and false negatives. Additionally, to prevent the model from deviating from normal trajectories due to misestimation, we introduce a regularization term in the loss function to ensure the model retains prior knowledge during updates. We evaluate DQNLog on three widely used datasets, demonstrating its ability to effectively utilize large-scale unlabeled data and achieve promising results across all experimental datasets.
Read more7/31/2024
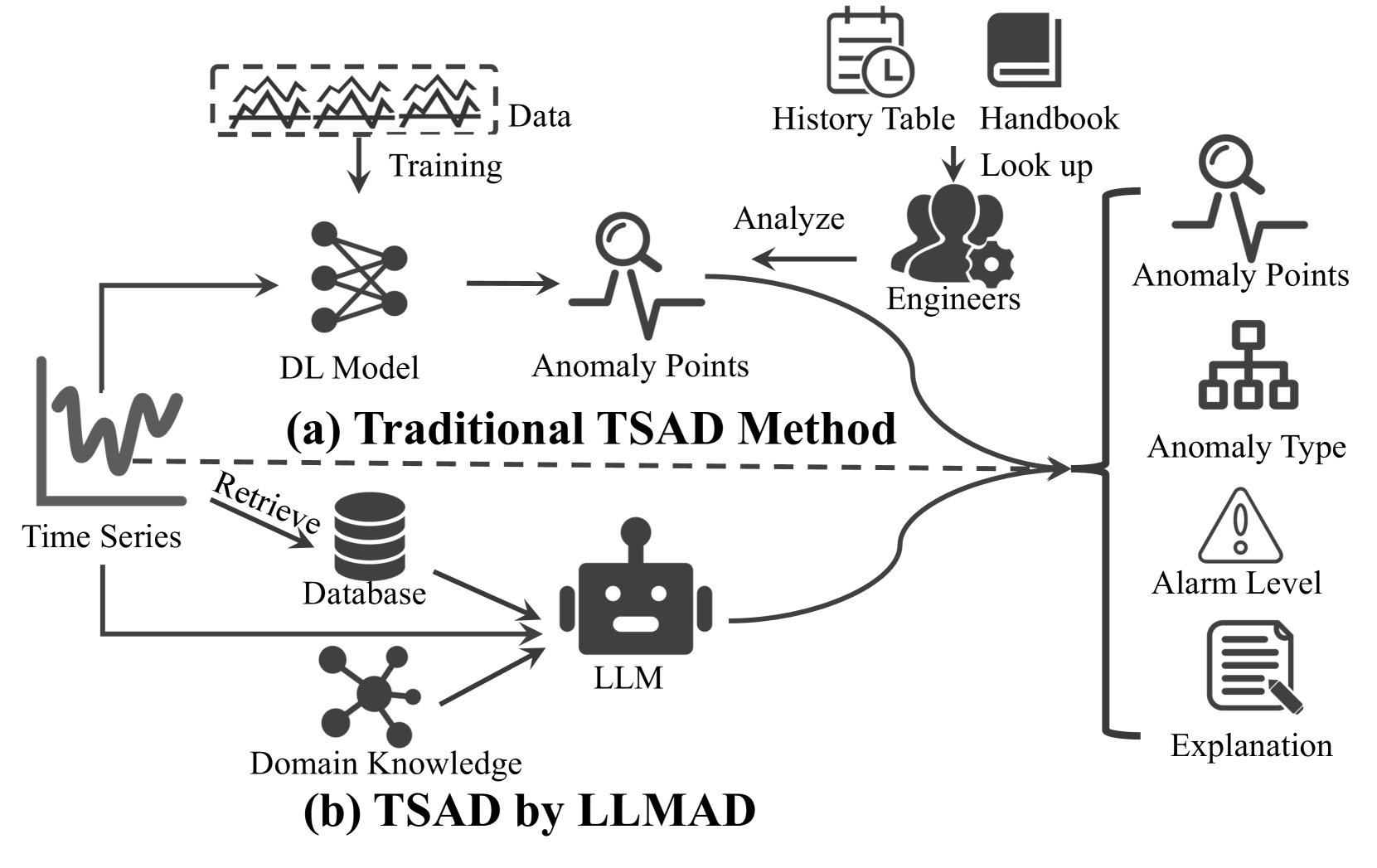
0
Large Language Models can Deliver Accurate and Interpretable Time Series Anomaly Detection
Jun Liu, Chaoyun Zhang, Jiaxu Qian, Minghua Ma, Si Qin, Chetan Bansal, Qingwei Lin, Saravan Rajmohan, Dongmei Zhang
Time series anomaly detection (TSAD) plays a crucial role in various industries by identifying atypical patterns that deviate from standard trends, thereby maintaining system integrity and enabling prompt response measures. Traditional TSAD models, which often rely on deep learning, require extensive training data and operate as black boxes, lacking interpretability for detected anomalies. To address these challenges, we propose LLMAD, a novel TSAD method that employs Large Language Models (LLMs) to deliver accurate and interpretable TSAD results. LLMAD innovatively applies LLMs for in-context anomaly detection by retrieving both positive and negative similar time series segments, significantly enhancing LLMs' effectiveness. Furthermore, LLMAD employs the Anomaly Detection Chain-of-Thought (AnoCoT) approach to mimic expert logic for its decision-making process. This method further enhances its performance and enables LLMAD to provide explanations for their detections through versatile perspectives, which are particularly important for user decision-making. Experiments on three datasets indicate that our LLMAD achieves detection performance comparable to state-of-the-art deep learning methods while offering remarkable interpretability for detections. To the best of our knowledge, this is the first work that directly employs LLMs for TSAD.
Read more5/27/2024