A Comprehensive Survey on Deep Multimodal Learning with Missing Modality

0
Sign in to get full access
Overview
- This paper provides a comprehensive survey on deep multimodal learning with missing modality.
- It covers the key concepts, techniques, and challenges in this field.
- The survey examines the state-of-the-art approaches and identifies areas for future research.
Plain English Explanation
Multimodal learning involves training artificial intelligence (AI) systems to understand and process information from multiple sources, such as text, images, and audio. This is important because real-world data is often a combination of different modalities.
One of the key challenges in multimodal learning is dealing with missing modality, where one or more of the expected data sources is not available. The paper examines various techniques that have been developed to address this issue, such as knowledge transfer and imputation methods.
The paper also discusses the importance of representation learning in multimodal systems, which involves learning efficient and effective ways to combine information from different modalities. This is crucial for building multimodal large language models that can understand and generate human-like language.
Overall, the survey provides a deep dive into the current state of the art in deep multimodal learning and highlights the key challenges and opportunities in this rapidly evolving field.
Technical Explanation
The paper begins by introducing the concept of multimodal learning, which involves training AI systems to process and understand information from multiple data sources, such as text, images, and audio. The authors highlight the importance of this approach, as real-world data is often a combination of different modalities.
One of the core challenges addressed in the survey is missing modality, where one or more of the expected data sources is not available during training or inference. The paper examines various techniques that have been developed to address this issue, including imputation methods, which aim to estimate the missing data, and knowledge transfer, where information learned from one modality is used to enhance the performance of the model on another modality.
The survey also delves into the role of representation learning in multimodal systems. This involves learning efficient and effective ways to combine information from different modalities, which is crucial for building powerful multimodal large language models that can understand and generate human-like language.
The paper provides a comprehensive overview of the state-of-the-art approaches in deep multimodal learning, covering a wide range of applications, such as multimedia analysis, audio signal processing, and multimodal sentiment analysis. The authors also identify key challenges and opportunities for future research in this rapidly evolving field.
Critical Analysis
The paper provides a thorough and well-researched overview of the current state of deep multimodal learning with missing modality. The authors have done an excellent job of summarizing the key concepts, techniques, and challenges in this field, and their discussion of the role of representation learning and multimodal large language models is particularly insightful.
One potential limitation of the survey is that it may not cover the most recent developments in the field, as the paper is a pre-print and the research landscape is rapidly evolving. Additionally, the paper does not delve deeply into the practical implementation details or performance benchmarks of the various approaches discussed, which could be useful for readers interested in applying these techniques in their own work.
That said, the paper is a valuable resource for researchers and practitioners working in the field of multimodal learning, as it provides a comprehensive and well-structured overview of the current state of the art. The authors' identification of future research directions, such as the need for more robust and generalizable multimodal models, is also particularly valuable for guiding the ongoing development of this important area of AI research.
Conclusion
This comprehensive survey on deep multimodal learning with missing modality provides a valuable overview of the key concepts, techniques, and challenges in this rapidly evolving field. The paper examines the importance of multimodal learning, the challenges posed by missing modality, and the role of representation learning and multimodal large language models.
The authors have done an excellent job of summarizing the state-of-the-art approaches and identifying areas for future research, making this survey a valuable resource for researchers and practitioners working in the field of AI and multimodal learning. While the paper may not cover the most recent developments, its in-depth discussion of the core concepts and techniques in this area is highly informative and can help guide the ongoing advancement of this important area of study.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Comprehensive Survey on Deep Multimodal Learning with Missing Modality
Renjie Wu, Hu Wang, Hsiang-Ting Chen
During multimodal model training and reasoning, data samples may miss certain modalities and lead to compromised model performance due to sensor limitations, cost constraints, privacy concerns, data loss, and temporal and spatial factors. This survey provides an overview of recent progress in Multimodal Learning with Missing Modality (MLMM), focusing on deep learning techniques. It is the first comprehensive survey that covers the historical background and the distinction between MLMM and standard multimodal learning setups, followed by a detailed analysis of current MLMM methods, applications, and datasets, concluding with a discussion about challenges and potential future directions in the field.
Read more9/16/2024
0
Multimodal Sentiment Analysis with Missing Modality: A Knowledge-Transfer Approach
Weide Liu, Huijing Zhan, Hao Chen, Fengmao Lv
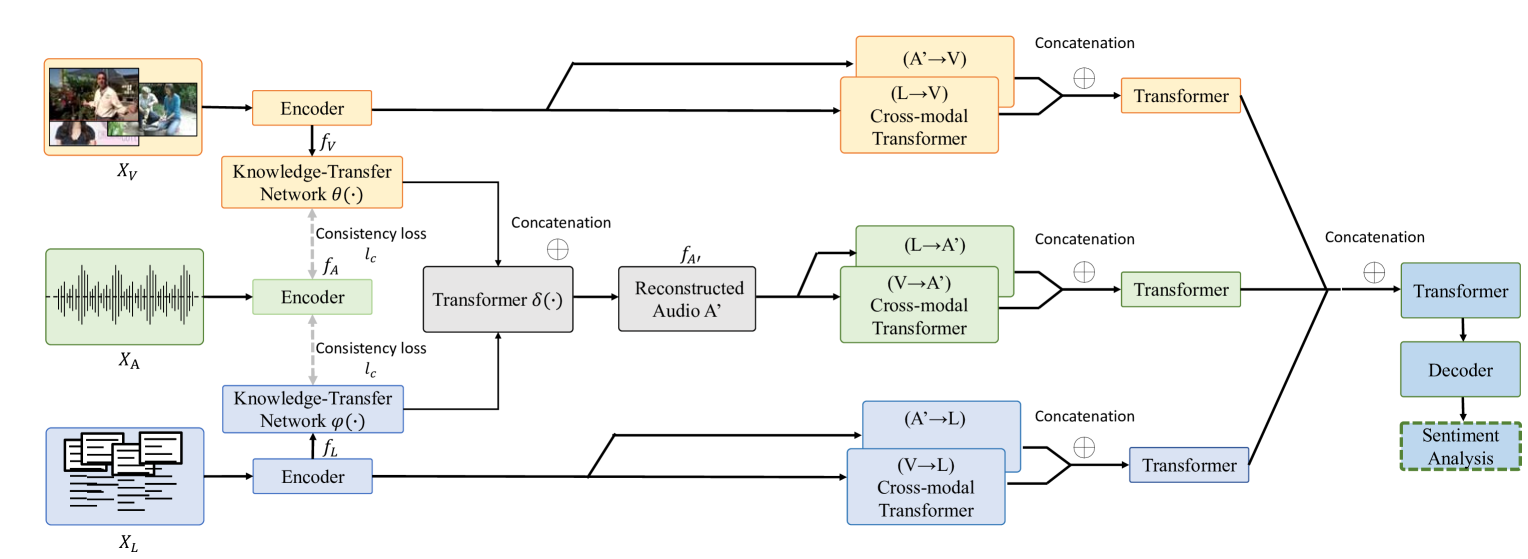
Multimodal sentiment analysis aims to identify the emotions expressed by individuals through visual, language, and acoustic cues. However, most of the existing research efforts assume that all modalities are available during both training and testing, making their algorithms susceptible to the missing modality scenario. In this paper, we propose a novel knowledge-transfer network to translate between different modalities to reconstruct the missing audio modalities. Moreover, we develop a cross-modality attention mechanism to retain the maximal information of the reconstructed and observed modalities for sentiment prediction. Extensive experiments on three publicly available datasets demonstrate significant improvements over baselines and achieve comparable results to the previous methods with complete multi-modality supervision.
Read more7/12/2024

0
From Efficient Multimodal Models to World Models: A Survey
Xinji Mai, Zeng Tao, Junxiong Lin, Haoran Wang, Yang Chang, Yanlan Kang, Yan Wang, Wenqiang Zhang
Multimodal Large Models (MLMs) are becoming a significant research focus, combining powerful large language models with multimodal learning to perform complex tasks across different data modalities. This review explores the latest developments and challenges in MLMs, emphasizing their potential in achieving artificial general intelligence and as a pathway to world models. We provide an overview of key techniques such as Multimodal Chain of Thought (M-COT), Multimodal Instruction Tuning (M-IT), and Multimodal In-Context Learning (M-ICL). Additionally, we discuss both the fundamental and specific technologies of multimodal models, highlighting their applications, input/output modalities, and design characteristics. Despite significant advancements, the development of a unified multimodal model remains elusive. We discuss the integration of 3D generation and embodied intelligence to enhance world simulation capabilities and propose incorporating external rule systems for improved reasoning and decision-making. Finally, we outline future research directions to address these challenges and advance the field.
Read more7/2/2024

0
A Survey of Multimodal Large Language Model from A Data-centric Perspective
Tianyi Bai, Hao Liang, Binwang Wan, Yanran Xu, Xi Li, Shiyu Li, Ling Yang, Bozhou Li, Yifan Wang, Bin Cui, Ping Huang, Jiulong Shan, Conghui He, Binhang Yuan, Wentao Zhang
Multimodal large language models (MLLMs) enhance the capabilities of standard large language models by integrating and processing data from multiple modalities, including text, vision, audio, video, and 3D environments. Data plays a pivotal role in the development and refinement of these models. In this survey, we comprehensively review the literature on MLLMs from a data-centric perspective. Specifically, we explore methods for preparing multimodal data during the pretraining and adaptation phases of MLLMs. Additionally, we analyze the evaluation methods for the datasets and review the benchmarks for evaluating MLLMs. Our survey also outlines potential future research directions. This work aims to provide researchers with a detailed understanding of the data-driven aspects of MLLMs, fostering further exploration and innovation in this field.
Read more7/19/2024