A Survey of Multimodal Large Language Model from A Data-centric Perspective
2405.16640
0
0

Abstract
Human beings perceive the world through diverse senses such as sight, smell, hearing, and touch. Similarly, multimodal large language models (MLLMs) enhance the capabilities of traditional large language models by integrating and processing data from multiple modalities including text, vision, audio, video, and 3D environments. Data plays a pivotal role in the development and refinement of these models. In this survey, we comprehensively review the literature on MLLMs from a data-centric perspective. Specifically, we explore methods for preparing multimodal data during the pretraining and adaptation phases of MLLMs. Additionally, we analyze the evaluation methods for datasets and review benchmarks for evaluating MLLMs. Our survey also outlines potential future research directions. This work aims to provide researchers with a detailed understanding of the data-driven aspects of MLLMs, fostering further exploration and innovation in this field.
Create account to get full access
Overview
- Provides a comprehensive survey of multimodal large language models (MMoLLMs) from a data-centric perspective
- Discusses the backgrounds and categorization of MMoLLMs
- Examines the key properties, model architectures, and training approaches of MMoLLMs
- Analyzes the performance and practical considerations of MMoLLMs
- Identifies future research directions and open challenges in this rapidly evolving field
Plain English Explanation
Multimodal large language models (MMoLLMs) are a type of artificial intelligence system that can understand and generate content across multiple mediums, such as text, images, and even audio. This paper provides a detailed overview of the current state of MMoLLMs, looking at them from the perspective of the data used to train these models.
The paper first discusses the background and different ways that MMoLLMs can be categorized, such as by the types of modalities they can handle or the specific architectures used to combine these modalities. It then delves into the key properties of MMoLLMs, including how they are designed and trained, and the various trade-offs and practical considerations that come with using these models.
The plain English explanation of MMoLLMs provides a high-level understanding of these advanced AI systems, making the concepts more accessible to a general audience. By using analogies and simplifying the technical details, the explanation helps readers grasp the significance and potential applications of MMoLLMs without getting bogged down in complex terminology.
Technical Explanation
The paper begins by providing a background and categorization of multimodal large language models (MMoLLMs). It discusses how these models are designed to understand and generate content across multiple modalities, such as text, images, and audio. The authors then outline different ways to classify MMoLLMs, such as by the specific modalities they can handle or the architectural approaches used to fuse these modalities.
The paper then delves into the key properties, model architectures, and training approaches of MMoLLMs. It examines how these models are designed to efficiently process and generate multimodal content, as well as the trade-offs and practical considerations that come with using these advanced AI systems.
The authors also provide an in-depth analysis of the performance of MMoLLMs across various tasks and datasets, highlighting their strengths and limitations. Additionally, the paper discusses the methods and insights gained from studying the inner workings of these models.
Critical Analysis
The paper acknowledges several caveats and limitations of the current state of MMoLLMs. For example, it notes that the performance of these models can be heavily dependent on the quality and diversity of the training data, and that there are still challenges in scaling MMoLLMs to handle increasingly complex and diverse multimodal inputs.
Additionally, the paper raises concerns about the potential biases and ethical implications of using these powerful AI systems, particularly in areas such as content generation and decision-making. It encourages readers to think critically about the societal impact of MMoLLMs and to consider the importance of responsible development and deployment of these technologies.
Conclusion
This comprehensive survey of multimodal large language models provides a valuable resource for researchers, engineers, and policymakers interested in the development and application of these advanced AI systems. The paper's in-depth analysis of the key properties, architectures, and performance of MMoLLMs, as well as its discussion of the challenges and future research directions, offers a thorough understanding of the current state of the field.
By bridging the gap between technical details and practical implications, this paper serves as an important reference for those seeking to harness the power of MMoLLMs while also considering the ethical and societal considerations that come with deploying such transformative technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

The Revolution of Multimodal Large Language Models: A Survey
Davide Caffagni, Federico Cocchi, Luca Barsellotti, Nicholas Moratelli, Sara Sarto, Lorenzo Baraldi, Lorenzo Baraldi, Marcella Cornia, Rita Cucchiara
0
0
Connecting text and visual modalities plays an essential role in generative intelligence. For this reason, inspired by the success of large language models, significant research efforts are being devoted to the development of Multimodal Large Language Models (MLLMs). These models can seamlessly integrate visual and textual modalities, while providing a dialogue-based interface and instruction-following capabilities. In this paper, we provide a comprehensive review of recent visual-based MLLMs, analyzing their architectural choices, multimodal alignment strategies, and training techniques. We also conduct a detailed analysis of these models across a wide range of tasks, including visual grounding, image generation and editing, visual understanding, and domain-specific applications. Additionally, we compile and describe training datasets and evaluation benchmarks, conducting comparisons among existing models in terms of performance and computational requirements. Overall, this survey offers a comprehensive overview of the current state of the art, laying the groundwork for future MLLMs.
6/7/2024

A Review of Multi-Modal Large Language and Vision Models
Kilian Carolan, Laura Fennelly, Alan F. Smeaton
0
0
Large Language Models (LLMs) have recently emerged as a focal point of research and application, driven by their unprecedented ability to understand and generate text with human-like quality. Even more recently, LLMs have been extended into multi-modal large language models (MM-LLMs) which extends their capabilities to deal with image, video and audio information, in addition to text. This opens up applications like text-to-video generation, image captioning, text-to-speech, and more and is achieved either by retro-fitting an LLM with multi-modal capabilities, or building a MM-LLM from scratch. This paper provides an extensive review of the current state of those LLMs with multi-modal capabilities as well as the very recent MM-LLMs. It covers the historical development of LLMs especially the advances enabled by transformer-based architectures like OpenAI's GPT series and Google's BERT, as well as the role of attention mechanisms in enhancing model performance. The paper includes coverage of the major and most important of the LLMs and MM-LLMs and also covers the techniques of model tuning, including fine-tuning and prompt engineering, which tailor pre-trained models to specific tasks or domains. Ethical considerations and challenges, such as data bias and model misuse, are also analysed to underscore the importance of responsible AI development and deployment. Finally, we discuss the implications of open-source versus proprietary models in AI research. Through this review, we provide insights into the transformative potential of MM-LLMs in various applications.
4/3/2024
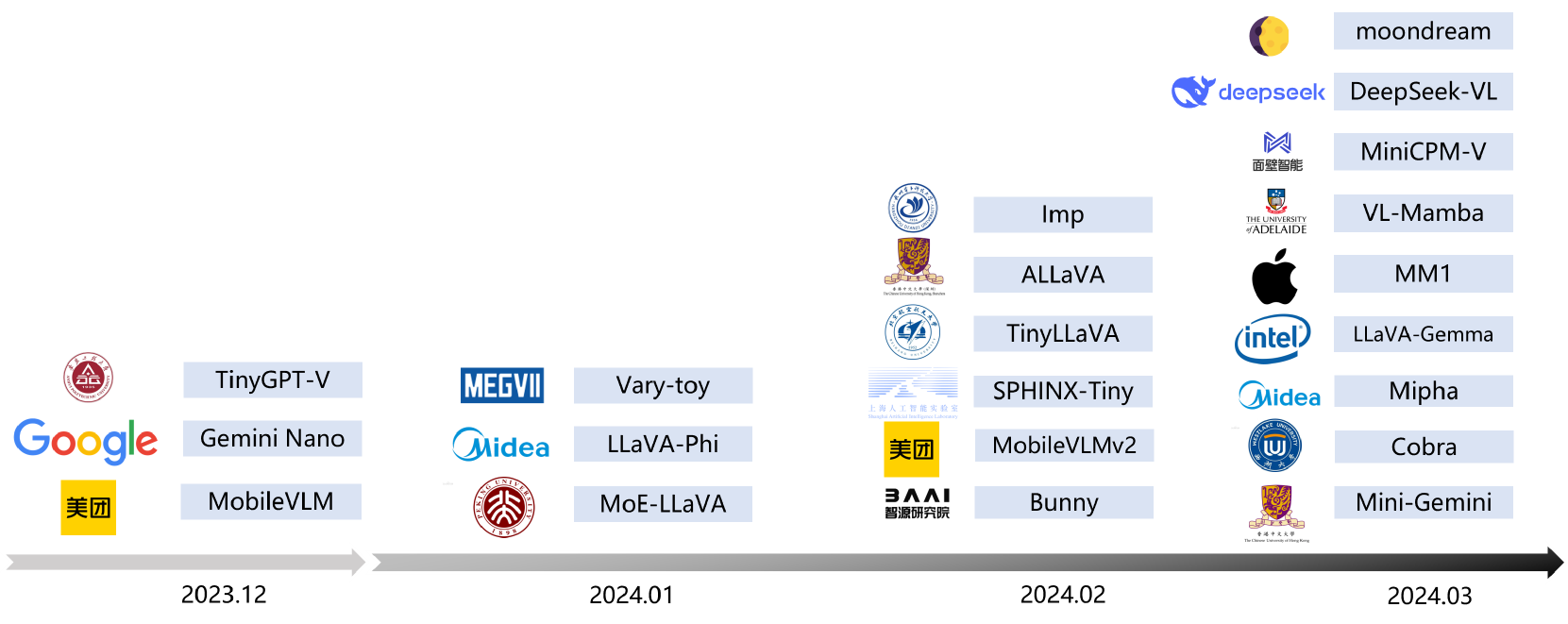
Efficient Multimodal Large Language Models: A Survey
Yizhang Jin, Jian Li, Yexin Liu, Tianjun Gu, Kai Wu, Zhengkai Jiang, Muyang He, Bo Zhao, Xin Tan, Zhenye Gan, Yabiao Wang, Chengjie Wang, Lizhuang Ma
0
0
In the past year, Multimodal Large Language Models (MLLMs) have demonstrated remarkable performance in tasks such as visual question answering, visual understanding and reasoning. However, the extensive model size and high training and inference costs have hindered the widespread application of MLLMs in academia and industry. Thus, studying efficient and lightweight MLLMs has enormous potential, especially in edge computing scenarios. In this survey, we provide a comprehensive and systematic review of the current state of efficient MLLMs. Specifically, we summarize the timeline of representative efficient MLLMs, research state of efficient structures and strategies, and the applications. Finally, we discuss the limitations of current efficient MLLM research and promising future directions. Please refer to our GitHub repository for more details: https://github.com/lijiannuist/Efficient-Multimodal-LLMs-Survey.
5/20/2024
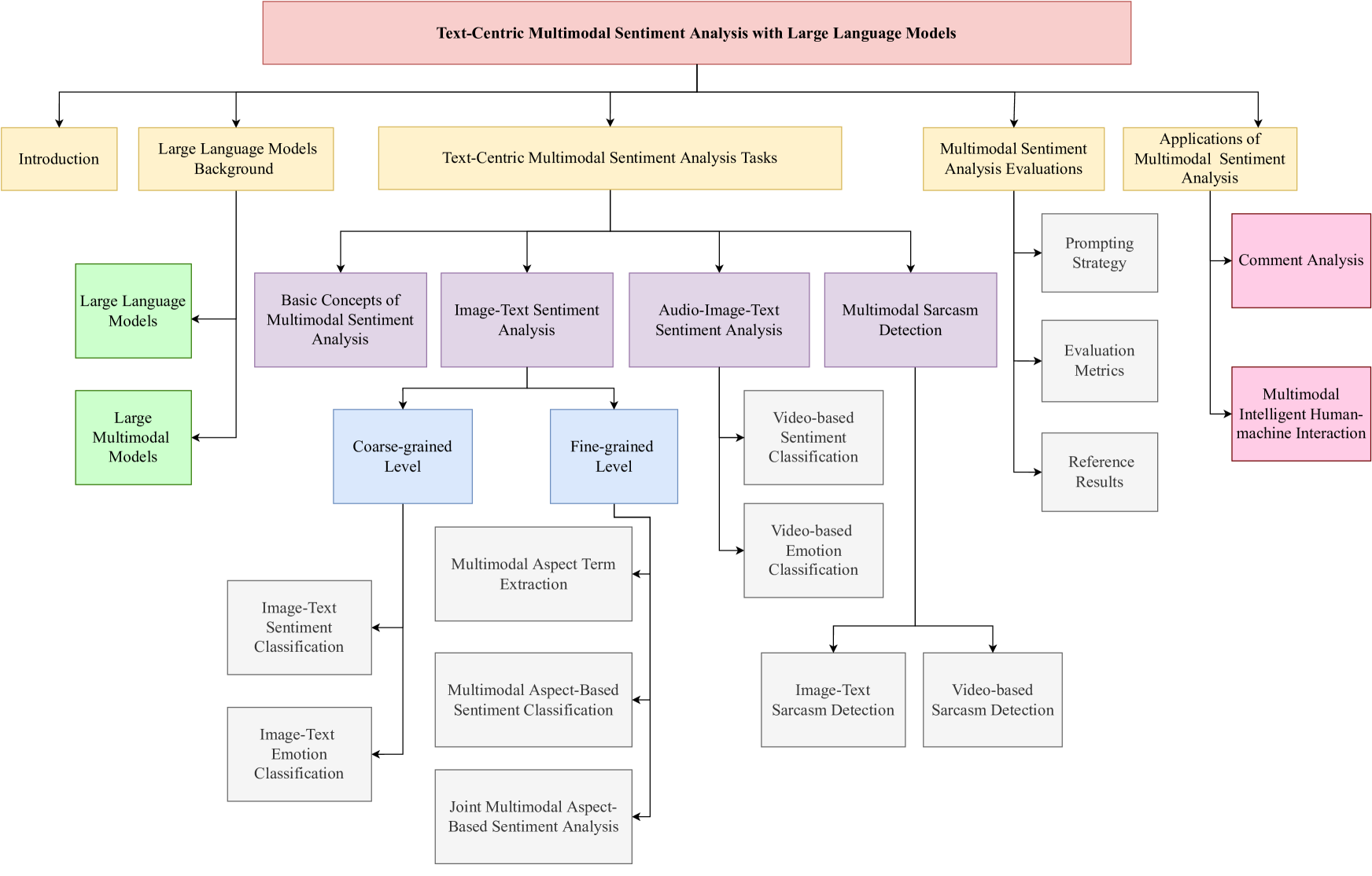
Large Language Models Meet Text-Centric Multimodal Sentiment Analysis: A Survey
Hao Yang, Yanyan Zhao, Yang Wu, Shilong Wang, Tian Zheng, Hongbo Zhang, Wanxiang Che, Bing Qin
0
0
Compared to traditional sentiment analysis, which only considers text, multimodal sentiment analysis needs to consider emotional signals from multimodal sources simultaneously and is therefore more consistent with the way how humans process sentiment in real-world scenarios. It involves processing emotional information from various sources such as natural language, images, videos, audio, physiological signals, etc. However, although other modalities also contain diverse emotional cues, natural language usually contains richer contextual information and therefore always occupies a crucial position in multimodal sentiment analysis. The emergence of ChatGPT has opened up immense potential for applying large language models (LLMs) to text-centric multimodal tasks. However, it is still unclear how existing LLMs can adapt better to text-centric multimodal sentiment analysis tasks. This survey aims to (1) present a comprehensive review of recent research in text-centric multimodal sentiment analysis tasks, (2) examine the potential of LLMs for text-centric multimodal sentiment analysis, outlining their approaches, advantages, and limitations, (3) summarize the application scenarios of LLM-based multimodal sentiment analysis technology, and (4) explore the challenges and potential research directions for multimodal sentiment analysis in the future.
6/13/2024