A Comprehensive Taxonomy and Analysis of Talking Head Synthesis: Techniques for Portrait Generation, Driving Mechanisms, and Editing

0
Sign in to get full access
Overview
- This paper provides a comprehensive taxonomy and analysis of talking head synthesis techniques, including techniques for portrait generation, driving mechanisms, and editing.
- The paper covers a wide range of methods and approaches used in the field of talking head synthesis, offering a detailed overview of the state-of-the-art.
- The goal is to help researchers and practitioners better understand the landscape of talking head synthesis and identify promising directions for future research and development.
Plain English Explanation
Talking head synthesis refers to the process of creating realistic-looking and -sounding animated characters that can interact with users through speech and facial expressions. This paper examines the various techniques used to achieve this, from generating photorealistic portraits to driving the animation using different mechanisms.
The paper organizes these techniques into a comprehensive taxonomy, providing a clear and structured overview of the field. This can help researchers and developers better understand the current state of the art and identify promising areas for further exploration.
For example, the paper discusses methods for generating high-fidelity talking portrait models that can be seamlessly integrated into various applications, such as virtual assistants, social media, and video conferencing. It also explores techniques for controlling the speaking style and emotional expression of the animated characters, allowing for more natural and engaging interactions.
Additionally, the paper covers editing and manipulation capabilities, which enable users to customize the appearance and behavior of the talking heads to suit their specific needs or preferences. This can be particularly useful in applications where personalization is important, such as in the entertainment or education sectors.
By presenting this taxonomy and analysis, the paper aims to serve as a valuable resource for the research community, helping to advance the field of talking head synthesis and unlock new possibilities for realistic and engaging human-computer interactions.
Technical Explanation
The paper presents a comprehensive taxonomy and analysis of talking head synthesis techniques, covering three key areas: portrait generation, driving mechanisms, and editing.
In the portrait generation section, the paper examines methods for creating high-fidelity, photorealistic talking head models. This includes techniques such as 3D face reconstruction, neural rendering, and disentangled representation learning. These approaches aim to capture the intricate details and nuances of human facial features and expressions, enabling the synthesis of highly realistic talking heads.
The driving mechanisms section explores how these talking head models can be animated and controlled. The paper covers techniques such as speech-driven animation, emotion-based expression control, and hierarchical audio-visual synthesis. These methods allow for the seamless integration of audio and visual elements, enabling the talking heads to respond naturalistically to user input and engage in dynamic, lifelike interactions.
Finally, the paper explores editing and manipulation capabilities, which enable users to customize the appearance and behavior of the talking heads. This includes techniques for adjusting facial features, modifying speaking styles, and blending different emotional expressions. These editing tools can be valuable in a wide range of applications, from entertainment and virtual communication to education and training.
Throughout the paper, the authors provide a detailed analysis of the state-of-the-art in each of these areas, highlighting the key technical advancements, strengths, and limitations of the various approaches. This comprehensive taxonomy serves as a valuable resource for researchers and practitioners working in the field of talking head synthesis, helping to guide future research and development efforts.
Critical Analysis
The paper provides a thorough and insightful overview of the current landscape of talking head synthesis, covering a wide range of techniques and approaches. The taxonomic organization of the content is particularly useful, as it helps readers navigate the complex and rapidly evolving field.
One potential area for further exploration mentioned in the paper is the incorporation of more advanced multimodal inputs, such as gestures, eye movements, and body language, to create even more realistic and engaging talking head interactions. While the current state-of-the-art focuses primarily on speech and facial expressions, expanding the repertoire of controllable features could lead to more natural and immersive user experiences.
Additionally, the paper acknowledges the potential for bias and ethical concerns in the development of talking head synthesis systems, particularly around issues of representation and privacy. As these technologies become more widely adopted, it will be crucial for researchers and developers to consider the societal implications and work to address any potential harms or unintended consequences.
Overall, this paper serves as an excellent starting point for those interested in understanding the current state of the art in talking head synthesis. By providing a comprehensive taxonomy and analysis, the authors have laid the groundwork for further advancements in this rapidly evolving field.
Conclusion
This paper presents a comprehensive taxonomy and analysis of talking head synthesis techniques, covering the key areas of portrait generation, driving mechanisms, and editing. The authors provide a detailed overview of the state-of-the-art in each of these domains, highlighting the latest advancements and the tradeoffs associated with various approaches.
By organizing the content in a clear and structured manner, the paper serves as a valuable resource for researchers and practitioners working in the field of talking head synthesis. It can help guide future research and development efforts, as well as inform the design and implementation of more realistic and engaging human-computer interactions.
While the current techniques have made significant strides in terms of realism and interactivity, the paper also identifies areas for further exploration, such as incorporating more advanced multimodal inputs and addressing potential ethical concerns. As the field continues to evolve, this taxonomy and analysis will remain a crucial reference point for those looking to push the boundaries of talking head synthesis and unlock new possibilities for virtual communication and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Comprehensive Taxonomy and Analysis of Talking Head Synthesis: Techniques for Portrait Generation, Driving Mechanisms, and Editing
Ming Meng, Yufei Zhao, Bo Zhang, Yonggui Zhu, Weimin Shi, Maxwell Wen, Zhaoxin Fan
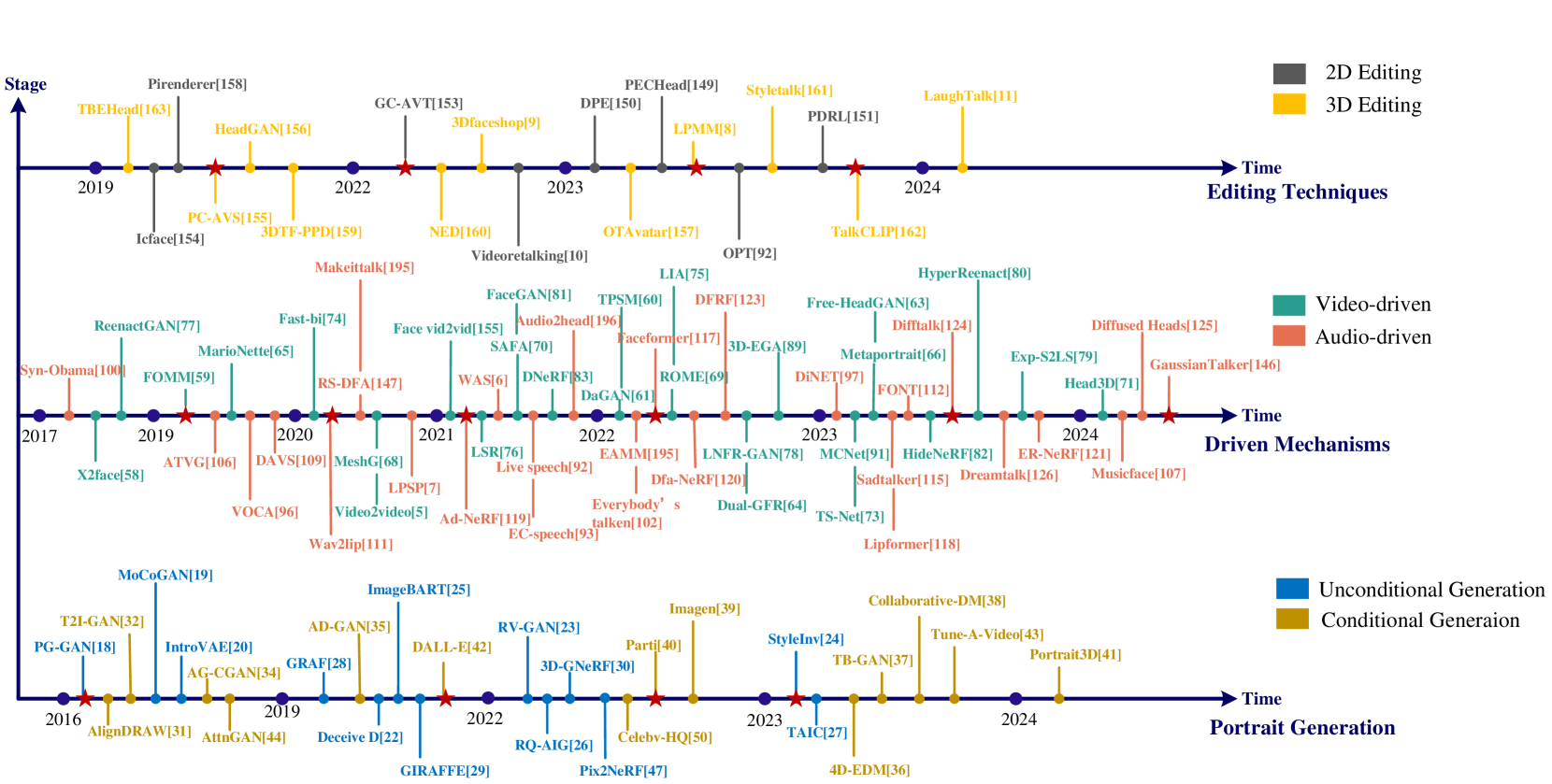
Talking head synthesis, an advanced method for generating portrait videos from a still image driven by specific content, has garnered widespread attention in virtual reality, augmented reality and game production. Recently, significant breakthroughs have been made with the introduction of novel models such as the transformer and the diffusion model. Current methods can not only generate new content but also edit the generated material. This survey systematically reviews the technology, categorizing it into three pivotal domains: portrait generation, driven mechanisms, and editing techniques. We summarize milestone studies and critically analyze their innovations and shortcomings within each domain. Additionally, we organize an extensive collection of datasets and provide a thorough performance analysis of current methodologies based on various evaluation metrics, aiming to furnish a clear framework and robust data support for future research. Finally, we explore application scenarios of talking head synthesis, illustrate them with specific cases, and examine potential future directions.
Read more6/19/2024
🛸
0
Listen, Disentangle, and Control: Controllable Speech-Driven Talking Head Generation
Changpeng Cai, Guinan Guo, Jiao Li, Junhao Su, Chenghao He, Jing Xiao, Yuanxu Chen, Lei Dai, Feiyu Zhu
Most earlier investigations on talking face generation have focused on the synchronization of lip motion and speech content. However, human head pose and facial emotions are equally important characteristics of natural human faces. While audio-driven talking face generation has seen notable advancements, existing methods either overlook facial emotions or are limited to specific individuals and cannot be applied to arbitrary subjects. In this paper, we propose a one-shot Talking Head Generation framework (SPEAK) that distinguishes itself from general Talking Face Generation by enabling emotional and postural control. Specifically, we introduce the Inter-Reconstructed Feature Disentanglement (IRFD) method to decouple human facial features into three latent spaces. We then design a face editing module that modifies speech content and facial latent codes into a single latent space. Subsequently, we present a novel generator that employs modified latent codes derived from the editing module to regulate emotional expression, head poses, and speech content in synthesizing facial animations. Extensive trials demonstrate that our method can generate realistic talking head with coordinated lip motions, authentic facial emotions, and smooth head movements. The demo video is available at the anonymous link: https://anonymous.4open.science/r/SPEAK-F56E
Read more8/28/2024

0
Talk3D: High-Fidelity Talking Portrait Synthesis via Personalized 3D Generative Prior
Jaehoon Ko, Kyusun Cho, Joungbin Lee, Heeji Yoon, Sangmin Lee, Sangjun Ahn, Seungryong Kim
Recent methods for audio-driven talking head synthesis often optimize neural radiance fields (NeRF) on a monocular talking portrait video, leveraging its capability to render high-fidelity and 3D-consistent novel-view frames. However, they often struggle to reconstruct complete face geometry due to the absence of comprehensive 3D information in the input monocular videos. In this paper, we introduce a novel audio-driven talking head synthesis framework, called Talk3D, that can faithfully reconstruct its plausible facial geometries by effectively adopting the pre-trained 3D-aware generative prior. Given the personalized 3D generative model, we present a novel audio-guided attention U-Net architecture that predicts the dynamic face variations in the NeRF space driven by audio. Furthermore, our model is further modulated by audio-unrelated conditioning tokens which effectively disentangle variations unrelated to audio features. Compared to existing methods, our method excels in generating realistic facial geometries even under extreme head poses. We also conduct extensive experiments showing our approach surpasses state-of-the-art benchmarks in terms of both quantitative and qualitative evaluations.
Read more4/1/2024
0
StyleTalk++: A Unified Framework for Controlling the Speaking Styles of Talking Heads
Suzhen Wang, Yifeng Ma, Yu Ding, Zhipeng Hu, Changjie Fan, Tangjie Lv, Zhidong Deng, Xin Yu
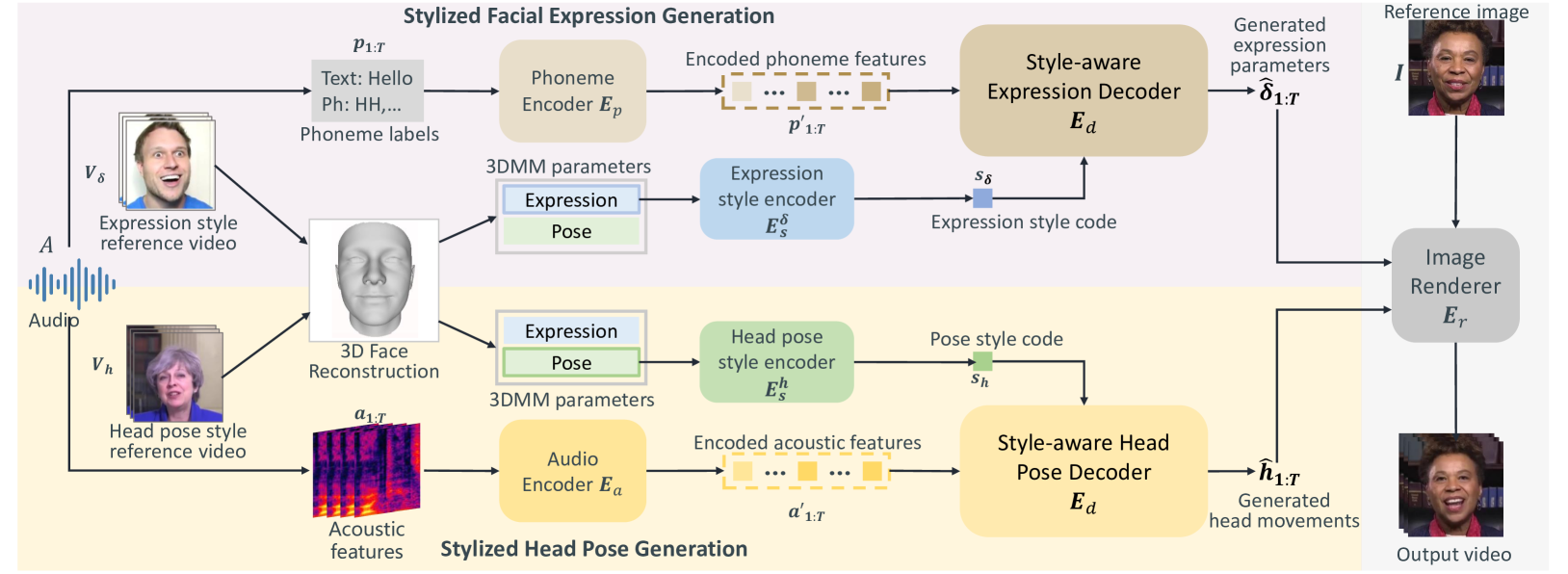
Individuals have unique facial expression and head pose styles that reflect their personalized speaking styles. Existing one-shot talking head methods cannot capture such personalized characteristics and therefore fail to produce diverse speaking styles in the final videos. To address this challenge, we propose a one-shot style-controllable talking face generation method that can obtain speaking styles from reference speaking videos and drive the one-shot portrait to speak with the reference speaking styles and another piece of audio. Our method aims to synthesize the style-controllable coefficients of a 3D Morphable Model (3DMM), including facial expressions and head movements, in a unified framework. Specifically, the proposed framework first leverages a style encoder to extract the desired speaking styles from the reference videos and transform them into style codes. Then, the framework uses a style-aware decoder to synthesize the coefficients of 3DMM from the audio input and style codes. During decoding, our framework adopts a two-branch architecture, which generates the stylized facial expression coefficients and stylized head movement coefficients, respectively. After obtaining the coefficients of 3DMM, an image renderer renders the expression coefficients into a specific person's talking-head video. Extensive experiments demonstrate that our method generates visually authentic talking head videos with diverse speaking styles from only one portrait image and an audio clip.
Read more9/17/2024