StyleTalk++: A Unified Framework for Controlling the Speaking Styles of Talking Heads

0
Sign in to get full access
Overview
- A unified framework for controlling the speaking styles of talking head models
- Allows for fine-grained control over various aspects of facial animation, including head pose, eye gaze, and facial expressions
- Leverages a neural network architecture to generate realistic talking head animations from audio input
Plain English Explanation
StyleTalk++ is a new framework that gives users more control over the way a talking head model speaks and moves. Rather than just having a single, generic talking head, this system allows you to customize different aspects of the animation, like the head position, eye movements, and facial expressions.
The key idea is to use a neural network to generate these different elements of the talking head animation based on the audio input. So you can feed in a recorded audio clip, and the system will create a corresponding video of a talking head that matches the style and delivery of the speech. This could be useful for things like creating more engaging virtual assistants, realistic video avatars, or animated characters with a wide range of expressive abilities.
Technical Explanation
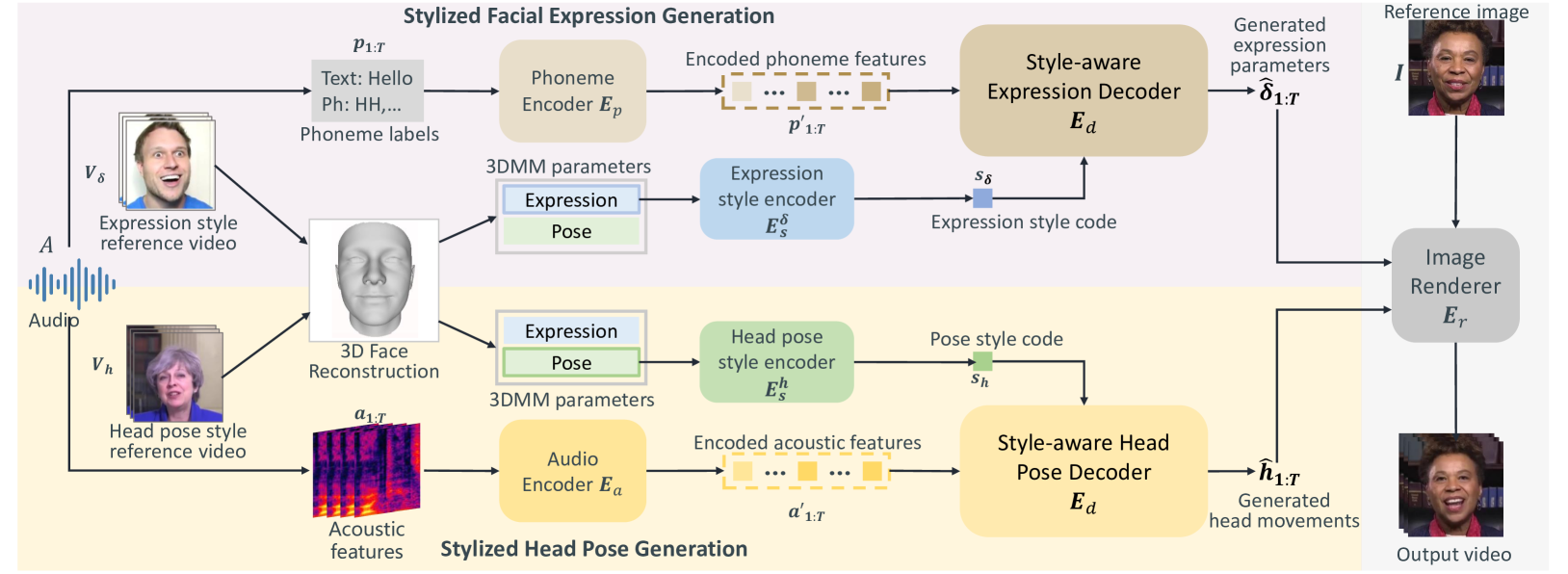
The StyleTalk++ framework uses a neural network architecture to generate talking head animations from audio input. The network is designed to disentangle and separately model different aspects of the facial animation, including head pose, eye gaze, and facial expressions.
The architecture consists of several key components:
- Audio Encoder: This module takes the input audio and extracts relevant features that capture the acoustic characteristics of the speech.
- Style Encoder: This component learns to encode the speaking style from the audio features, capturing things like rhythm, emphasis, and emotional tone.
- Animation Generators: These sub-networks use the audio features and style encoding to generate the specific animation elements, such as head pose, eye gaze, and facial expressions.
- Neural Renderer: The final module combines the various animation elements into a realistic talking head video.
By breaking down the animation into these distinct components, the StyleTalk++ framework allows for fine-grained control over the talking head's appearance and behavior. Users can adjust the style encoding to change the overall speaking style, or selectively modify individual animation elements to achieve their desired look and feel.
Critical Analysis
The StyleTalk++ paper presents a promising approach for enhancing the expressiveness and customizability of talking head models. By decoupling the various aspects of facial animation, the system provides a flexible and powerful way to control the speaking style and appearance of virtual characters.
However, the paper does acknowledge some limitations of the current system. For example, the model may struggle to maintain consistent facial identity across long video sequences, and the range of styles and emotions it can generate may be somewhat constrained by the training data.
Additionally, while the paper demonstrates the system's capabilities on a range of talking head examples, it would be valuable to see more thorough evaluations of the model's performance, such as user studies to assess the perceived realism and naturalness of the generated animations.
Further research could also explore ways to make the StyleTalk++ framework even more flexible and customizable, potentially by integrating it with other techniques for controlling facial animation or allowing users to fine-tune the model for their specific use cases.
Conclusion
StyleTalk++ represents an important step forward in the development of more expressive and controllable talking head models. By leveraging a neural network architecture that can independently generate different aspects of facial animation, the framework provides users with a powerful tool for creating engaging and personalized virtual characters.
As this technology continues to evolve, we may see it applied in a wide range of applications, from virtual assistants and video avatars to animated characters in games and films. The ability to fine-tune the speaking style and appearance of these virtual entities could lead to more immersive and natural interactions, ultimately enhancing the way we communicate and engage with technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
StyleTalk++: A Unified Framework for Controlling the Speaking Styles of Talking Heads
Suzhen Wang, Yifeng Ma, Yu Ding, Zhipeng Hu, Changjie Fan, Tangjie Lv, Zhidong Deng, Xin Yu
Individuals have unique facial expression and head pose styles that reflect their personalized speaking styles. Existing one-shot talking head methods cannot capture such personalized characteristics and therefore fail to produce diverse speaking styles in the final videos. To address this challenge, we propose a one-shot style-controllable talking face generation method that can obtain speaking styles from reference speaking videos and drive the one-shot portrait to speak with the reference speaking styles and another piece of audio. Our method aims to synthesize the style-controllable coefficients of a 3D Morphable Model (3DMM), including facial expressions and head movements, in a unified framework. Specifically, the proposed framework first leverages a style encoder to extract the desired speaking styles from the reference videos and transform them into style codes. Then, the framework uses a style-aware decoder to synthesize the coefficients of 3DMM from the audio input and style codes. During decoding, our framework adopts a two-branch architecture, which generates the stylized facial expression coefficients and stylized head movement coefficients, respectively. After obtaining the coefficients of 3DMM, an image renderer renders the expression coefficients into a specific person's talking-head video. Extensive experiments demonstrate that our method generates visually authentic talking head videos with diverse speaking styles from only one portrait image and an audio clip.
Read more9/17/2024
🛸
0
Listen, Disentangle, and Control: Controllable Speech-Driven Talking Head Generation
Changpeng Cai, Guinan Guo, Jiao Li, Junhao Su, Chenghao He, Jing Xiao, Yuanxu Chen, Lei Dai, Feiyu Zhu
Most earlier investigations on talking face generation have focused on the synchronization of lip motion and speech content. However, human head pose and facial emotions are equally important characteristics of natural human faces. While audio-driven talking face generation has seen notable advancements, existing methods either overlook facial emotions or are limited to specific individuals and cannot be applied to arbitrary subjects. In this paper, we propose a one-shot Talking Head Generation framework (SPEAK) that distinguishes itself from general Talking Face Generation by enabling emotional and postural control. Specifically, we introduce the Inter-Reconstructed Feature Disentanglement (IRFD) method to decouple human facial features into three latent spaces. We then design a face editing module that modifies speech content and facial latent codes into a single latent space. Subsequently, we present a novel generator that employs modified latent codes derived from the editing module to regulate emotional expression, head poses, and speech content in synthesizing facial animations. Extensive trials demonstrate that our method can generate realistic talking head with coordinated lip motions, authentic facial emotions, and smooth head movements. The demo video is available at the anonymous link: https://anonymous.4open.science/r/SPEAK-F56E
Read more8/28/2024
🛸
0
DiffPoseTalk: Speech-Driven Stylistic 3D Facial Animation and Head Pose Generation via Diffusion Models
Zhiyao Sun, Tian Lv, Sheng Ye, Matthieu Lin, Jenny Sheng, Yu-Hui Wen, Minjing Yu, Yong-Jin Liu
The generation of stylistic 3D facial animations driven by speech presents a significant challenge as it requires learning a many-to-many mapping between speech, style, and the corresponding natural facial motion. However, existing methods either employ a deterministic model for speech-to-motion mapping or encode the style using a one-hot encoding scheme. Notably, the one-hot encoding approach fails to capture the complexity of the style and thus limits generalization ability. In this paper, we propose DiffPoseTalk, a generative framework based on the diffusion model combined with a style encoder that extracts style embeddings from short reference videos. During inference, we employ classifier-free guidance to guide the generation process based on the speech and style. In particular, our style includes the generation of head poses, thereby enhancing user perception. Additionally, we address the shortage of scanned 3D talking face data by training our model on reconstructed 3DMM parameters from a high-quality, in-the-wild audio-visual dataset. Extensive experiments and user study demonstrate that our approach outperforms state-of-the-art methods. The code and dataset are at https://diffposetalk.github.io .
Read more5/15/2024
🛸
0
TalkCLIP: Talking Head Generation with Text-Guided Expressive Speaking Styles
Yifeng Ma, Suzhen Wang, Yu Ding, Bowen Ma, Tangjie Lv, Changjie Fan, Zhipeng Hu, Zhidong Deng, Xin Yu
Audio-driven talking head generation has drawn growing attention. To produce talking head videos with desired facial expressions, previous methods rely on extra reference videos to provide expression information, which may be difficult to find and hence limits their usage. In this work, we propose TalkCLIP, a framework that can generate talking heads where the expressions are specified by natural language, hence allowing for specifying expressions more conveniently. To model the mapping from text to expressions, we first construct a text-video paired talking head dataset where each video has diverse text descriptions that depict both coarse-grained emotions and fine-grained facial movements. Leveraging the proposed dataset, we introduce a CLIP-based style encoder that projects natural language-based descriptions to the representations of expressions. TalkCLIP can even infer expressions for descriptions unseen during training. TalkCLIP can also use text to modulate expression intensity and edit expressions. Extensive experiments demonstrate that TalkCLIP achieves the advanced capability of generating photo-realistic talking heads with vivid facial expressions guided by text descriptions.
Read more8/13/2024