Compress then Serve: Serving Thousands of LoRA Adapters with Little Overhead
2407.00066
0
0

Abstract
Fine-tuning large language models (LLMs) with low-rank adapters (LoRAs) has become common practice, often yielding numerous copies of the same LLM differing only in their LoRA updates. This paradigm presents challenges for systems that serve real-time responses to queries that each involve a different LoRA. Prior works optimize the design of such systems but still require continuous loading and offloading of LoRAs, as it is infeasible to store thousands of LoRAs in GPU memory. To mitigate this issue, we investigate the efficacy of compression when serving LoRA adapters. We consider compressing adapters individually via SVD and propose a method for joint compression of LoRAs into a shared basis paired with LoRA-specific scaling matrices. Our experiments with up to 500 LoRAs demonstrate that compressed LoRAs preserve performance while offering major throughput gains in realistic serving scenarios with over a thousand LoRAs, maintaining 75% of the throughput of serving a single LoRA.
Create account to get full access
Overview
- This paper presents a novel approach to serving thousands of Low-Rank Adaptation (LoRA) adapters with little overhead, addressing a key challenge in deploying large language models.
- The researchers introduce a compression technique called NoLA that can drastically reduce the storage and memory requirements of LoRA adapters.
- They also propose a batched low-rank adaptation method to efficiently serve multiple LoRA adapters simultaneously, enabling high-throughput inference.
- The authors demonstrate the effectiveness of their approach through extensive experiments, showing significant improvements in inference speed and memory usage compared to traditional LoRA deployments.
Plain English Explanation
Large language models have become increasingly powerful, but deploying them at scale can be challenging due to the significant storage and memory requirements of the models and their accompanying task-specific adapters. The LoRA technique was introduced as a way to efficiently adapt these models for specific tasks, but serving many LoRA adapters concurrently can still be computationally expensive.
The researchers in this paper have developed a solution to this problem. They've created a new compression technique called NoLA that can drastically reduce the size of LoRA adapters, making it much easier to store and serve them. They've also developed a way to batch multiple LoRA adapters together and serve them efficiently, without incurring a lot of overhead.
By combining these two innovations, the researchers have demonstrated that they can serve thousands of LoRA adapters with very little computational resources, making it much more practical to deploy large language models for a wide range of applications. This could have significant implications for the field of natural language processing, enabling more widespread use of these powerful models.
Technical Explanation
The paper introduces a novel approach to serving thousands of LoRA adapters with little overhead. LoRA is a technique for efficiently adapting large language models to specific tasks, but serving many LoRA adapters concurrently can be computationally expensive.
The researchers first present a compression technique called NoLA, which uses a linear combination of random matrices to represent the LoRA adapter parameters. This allows for significant compression of the adapter size, reducing storage and memory requirements.
Next, the authors propose a batched low-rank adaptation method to efficiently serve multiple LoRA adapters simultaneously. This approach enables high-throughput inference by processing multiple adapters in a single forward pass.
The paper includes extensive experiments that demonstrate the effectiveness of the proposed techniques. The researchers show that their approach can serve thousands of LoRA adapters with little overhead, achieving significant improvements in inference speed and memory usage compared to traditional LoRA deployments.
Critical Analysis
The paper presents a compelling solution to a practical challenge in deploying large language models at scale. The researchers' innovations, particularly the NoLA compression technique and the batched low-rank adaptation method, seem well-designed and effective based on the experimental results.
However, the paper does not provide much discussion of potential limitations or areas for further research. For example, it would be interesting to understand the impact of the compression on the performance of the LoRA adapters, or to explore the scalability of the approach to even larger numbers of adapters.
Additionally, the paper would benefit from a more thorough comparison to related work, such as the LoRA-XS technique for compressing LoRA adapters. This could help readers better understand the unique contributions of the proposed methods and how they relate to other approaches in the field.
Overall, the research presented in this paper represents an important step forward in enabling the widespread deployment of large language models, and the authors' innovations are likely to have a significant impact on the field of natural language processing.
Conclusion
This paper introduces a novel approach to serving thousands of LoRA adapters with little overhead, addressing a key challenge in deploying large language models at scale. The researchers' innovations, including the NoLA compression technique and the batched low-rank adaptation method, demonstrate significant improvements in inference speed and memory usage compared to traditional LoRA deployments.
These advancements have the potential to enable more widespread use of powerful large language models in a wide range of applications, furthering the progress of natural language processing and artificial intelligence. While the paper could benefit from a more thorough discussion of limitations and future research directions, the core contributions represent an important step forward in the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📶
S-LoRA: Serving Thousands of Concurrent LoRA Adapters
Ying Sheng, Shiyi Cao, Dacheng Li, Coleman Hooper, Nicholas Lee, Shuo Yang, Christopher Chou, Banghua Zhu, Lianmin Zheng, Kurt Keutzer, Joseph E. Gonzalez, Ion Stoica
0
0
The pretrain-then-finetune paradigm is commonly adopted in the deployment of large language models. Low-Rank Adaptation (LoRA), a parameter-efficient fine-tuning method, is often employed to adapt a base model to a multitude of tasks, resulting in a substantial collection of LoRA adapters derived from one base model. We observe that this paradigm presents significant opportunities for batched inference during serving. To capitalize on these opportunities, we present S-LoRA, a system designed for the scalable serving of many LoRA adapters. S-LoRA stores all adapters in the main memory and fetches the adapters used by the currently running queries to the GPU memory. To efficiently use the GPU memory and reduce fragmentation, S-LoRA proposes Unified Paging. Unified Paging uses a unified memory pool to manage dynamic adapter weights with different ranks and KV cache tensors with varying sequence lengths. Additionally, S-LoRA employs a novel tensor parallelism strategy and highly optimized custom CUDA kernels for heterogeneous batching of LoRA computation. Collectively, these features enable S-LoRA to serve thousands of LoRA adapters on a single GPU or across multiple GPUs with a small overhead. Compared to state-of-the-art libraries such as HuggingFace PEFT and vLLM (with naive support of LoRA serving), S-LoRA can improve the throughput by up to 4 times and increase the number of served adapters by several orders of magnitude. As a result, S-LoRA enables scalable serving of many task-specific fine-tuned models and offers the potential for large-scale customized fine-tuning services. The code is available at https://github.com/S-LoRA/S-LoRA
6/6/2024
👀
NOLA: Compressing LoRA using Linear Combination of Random Basis
Soroush Abbasi Koohpayegani, KL Navaneet, Parsa Nooralinejad, Soheil Kolouri, Hamed Pirsiavash
0
0
Fine-tuning Large Language Models (LLMs) and storing them for each downstream task or domain is impractical because of the massive model size (e.g., 350GB in GPT-3). Current literature, such as LoRA, showcases the potential of low-rank modifications to the original weights of an LLM, enabling efficient adaptation and storage for task-specific models. These methods can reduce the number of parameters needed to fine-tune an LLM by several orders of magnitude. Yet, these methods face two primary limitations: (1) the parameter count is lower-bounded by the rank one decomposition, and (2) the extent of reduction is heavily influenced by both the model architecture and the chosen rank. We introduce NOLA, which overcomes the rank one lower bound present in LoRA. It achieves this by re-parameterizing the low-rank matrices in LoRA using linear combinations of randomly generated matrices (basis) and optimizing the linear mixture coefficients only. This approach allows us to decouple the number of trainable parameters from both the choice of rank and the network architecture. We present adaptation results using GPT-2, LLaMA-2, and ViT in natural language and computer vision tasks. NOLA performs as well as LoRA models with much fewer number of parameters compared to LoRA with rank one, the best compression LoRA can archive. Particularly, on LLaMA-2 70B, our method is almost 20 times more compact than the most compressed LoRA without degradation in accuracy. Our code is available here: https://github.com/UCDvision/NOLA
5/1/2024
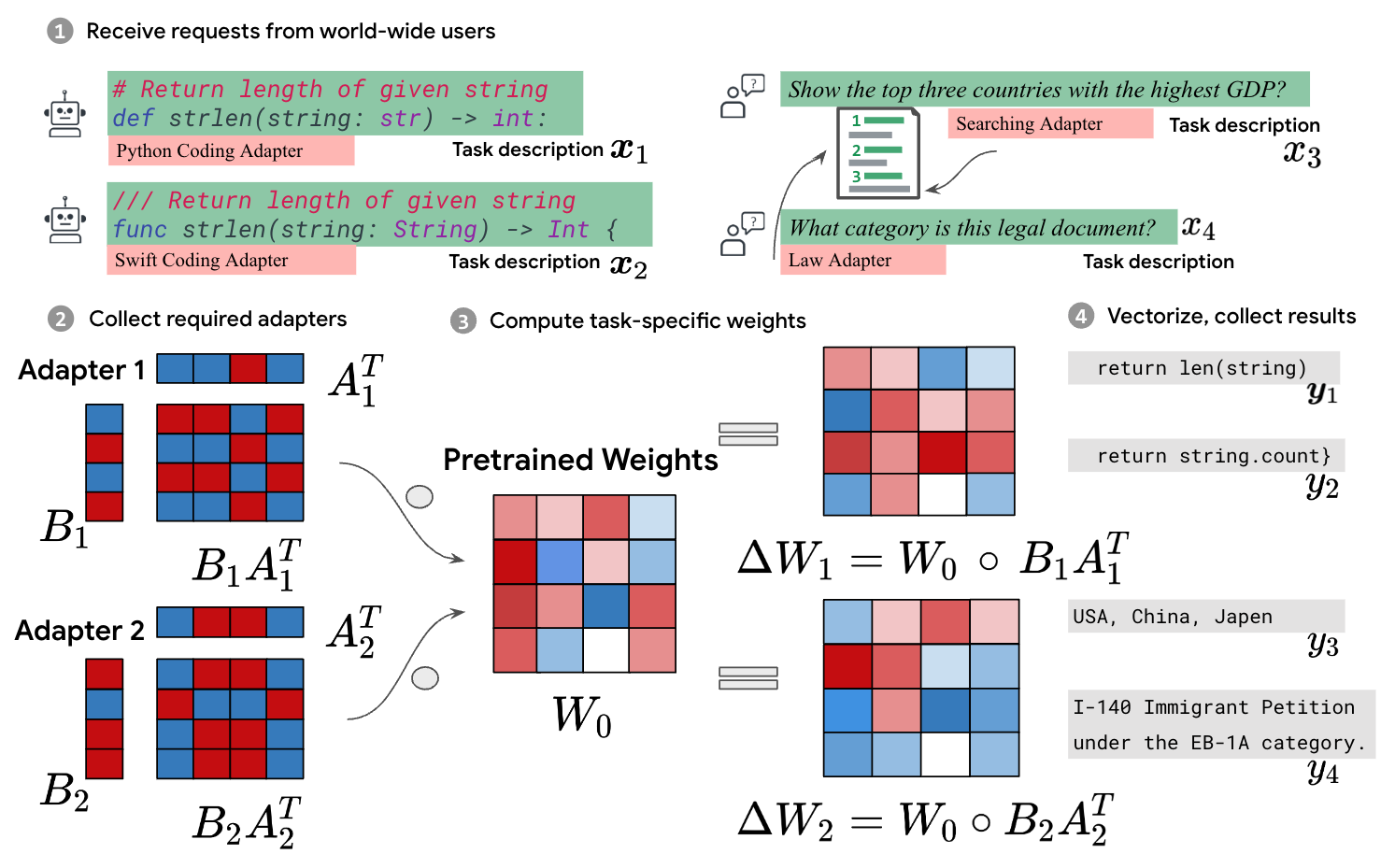
Batched Low-Rank Adaptation of Foundation Models
Yeming Wen, Swarat Chaudhuri
0
0
Low-Rank Adaptation (LoRA) has recently gained attention for fine-tuning foundation models by incorporating trainable low-rank matrices, thereby reducing the number of trainable parameters. While LoRA offers numerous advantages, its applicability for real-time serving to a diverse and global user base is constrained by its incapability to handle multiple task-specific adapters efficiently. This imposes a performance bottleneck in scenarios requiring personalized, task-specific adaptations for each incoming request. To mitigate this constraint, we introduce Fast LoRA (FLoRA), a framework in which each input example in a minibatch can be associated with its unique low-rank adaptation weights, allowing for efficient batching of heterogeneous requests. We empirically demonstrate that FLoRA retains the performance merits of LoRA, showcasing competitive results on the MultiPL-E code generation benchmark spanning over 8 languages and a multilingual speech recognition task across 6 languages.
4/29/2024
⚙️
A Note on LoRA
Vlad Fomenko, Han Yu, Jongho Lee, Stanley Hsieh, Weizhu Chen
0
0
LoRA (Low-Rank Adaptation) has emerged as a preferred method for efficiently adapting Large Language Models (LLMs) with remarkable simplicity and efficacy. This note extends the original LoRA paper by offering new perspectives that were not initially discussed and presents a series of insights for deploying LoRA at scale. Without introducing new experiments, we aim to improve the understanding and application of LoRA.
4/9/2024