LoRA-XS: Low-Rank Adaptation with Extremely Small Number of Parameters
2405.17604
0
0
🌀
Abstract
The recent trend in scaling language models has led to a growing demand for parameter-efficient tuning (PEFT) methods such as LoRA (Low-Rank Adaptation). LoRA consistently matches or surpasses the full fine-tuning baseline with fewer parameters. However, handling numerous task-specific or user-specific LoRA modules on top of a base model still presents significant storage challenges. To address this, we introduce LoRA-XS (Low-Rank Adaptation with eXtremely Small number of parameters), a novel approach leveraging Singular Value Decomposition (SVD) for parameter-efficient fine-tuning. LoRA-XS introduces a small r x r weight matrix between frozen LoRA matrices, which are constructed by SVD of the original weight matrix. Training only r x r weight matrices ensures independence from model dimensions, enabling more parameter-efficient fine-tuning, especially for larger models. LoRA-XS achieves a remarkable reduction of trainable parameters by over 100x in 7B models compared to LoRA. Our benchmarking across various scales, including GLUE, GSM8k, and MATH benchmarks, shows that our approach outperforms LoRA and recent state-of-the-art approaches like VeRA in terms of parameter efficiency while maintaining competitive performance.
Create account to get full access
Overview
- Introduces the challenges of fine-tuning large language models (LLMs) with high parameter counts
- Discusses a technique called Parameter-Efficient Fine-Tuning (PEFT) that aims to address these challenges
- Covers key PEFT methods like LoRA, Batch-LoRA, and A-LoRA
- Highlights the potential benefits of these techniques for fine-tuning large LLMs with reduced computational and storage requirements
Plain English Explanation
Large language models (LLMs) have made impressive advancements in natural language processing, but they often require a huge number of parameters, making it challenging to fine-tune them for specific tasks. LoRA, Batch-LoRA, and A-LoRA are techniques that aim to address this problem by allowing for efficient fine-tuning of LLMs with significantly fewer parameters. This can help reduce the computational and storage requirements for adapting these powerful models to specialized applications.
Technical Explanation
The paper introduces Parameter-Efficient Fine-Tuning (PEFT), a set of techniques that enable efficient fine-tuning of large language models. The key methods covered are:
- LoRA: This approach adds a low-rank update to the model's weight matrices, allowing for significant parameter reduction while maintaining performance.
- Batch-LoRA: An extension of LoRA that performs batched low-rank updates, further improving efficiency and scalability.
- A-LoRA: An allocation-aware variant of LoRA that dynamically adapts the low-rank update size for different layers, leading to even greater parameter efficiency.
The paper presents experiments demonstrating the effectiveness of these PEFT techniques, showing that they can achieve comparable performance to full fine-tuning while using a fraction of the parameters. This has important implications for the practical deployment of large LLMs, as it reduces the computational and storage challenges associated with fine-tuning these models.
Critical Analysis
The paper provides a thorough and technical explanation of the PEFT methods, highlighting their potential to address the fine-tuning challenges of large language models. However, the research does not explore some potential limitations or drawbacks:
- The impact of the PEFT techniques on model robustness, generalization, and out-of-distribution performance is not discussed in depth.
- The paper focuses on language modeling tasks, and it's unclear how well the PEFT methods would perform on other types of NLP problems or multimodal tasks.
- The paper does not delve into the theoretical underpinnings of why the PEFT techniques are effective, leaving some open questions about the fundamental principles behind their success.
Further research could explore these aspects to provide a more comprehensive understanding of the PEFT methods and their broader implications for the field of large language model adaptation.
Conclusion
The Parameter-Efficient Fine-Tuning (PEFT) techniques presented in this paper, including LoRA, Batch-LoRA, and A-LoRA, offer a promising approach to addressing the challenges of fine-tuning large language models. By significantly reducing the number of parameters required for adaptation, these methods can facilitate the practical deployment of powerful LLMs in a wide range of applications, with important implications for the field of natural language processing and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🐍
VB-LoRA: Extreme Parameter Efficient Fine-Tuning with Vector Banks
Yang Li, Shaobo Han, Shihao Ji
0
0
As the adoption of large language models increases and the need for per-user or per-task model customization grows, the parameter-efficient fine-tuning (PEFT) methods, such as low-rank adaptation (LoRA) and its variants, incur substantial storage and transmission costs. To further reduce stored parameters, we introduce a divide-and-share paradigm that breaks the barriers of low-rank decomposition across matrix dimensions, modules and layers by sharing parameters globally via a vector bank. As an instantiation of the paradigm to LoRA, our proposed VB-LoRA composites all the low-rank matrices of LoRA from a shared vector bank with a differentiable top-$k$ admixture module. VB-LoRA achieves extreme parameter efficiency while maintaining comparable or better performance compared to state-of-the-art PEFT methods. Extensive experiments demonstrate the effectiveness of VB-LoRA on natural language understanding, natural language generation, and instruction tuning tasks. When fine-tuning the Llama2-13B model, VB-LoRA only uses 0.4% of LoRA's stored parameters, yet achieves superior results. Our source code is available at https://github.com/leo-yangli/VB-LoRA.
5/29/2024
🌿
LoRA Land: 310 Fine-tuned LLMs that Rival GPT-4, A Technical Report
Justin Zhao, Timothy Wang, Wael Abid, Geoffrey Angus, Arnav Garg, Jeffery Kinnison, Alex Sherstinsky, Piero Molino, Travis Addair, Devvret Rishi
0
0
Low Rank Adaptation (LoRA) has emerged as one of the most widely adopted methods for Parameter Efficient Fine-Tuning (PEFT) of Large Language Models (LLMs). LoRA reduces the number of trainable parameters and memory usage while achieving comparable performance to full fine-tuning. We aim to assess the viability of training and serving LLMs fine-tuned with LoRA in real-world applications. First, we measure the quality of LLMs fine-tuned with quantized low rank adapters across 10 base models and 31 tasks for a total of 310 models. We find that 4-bit LoRA fine-tuned models outperform base models by 34 points and GPT-4 by 10 points on average. Second, we investigate the most effective base models for fine-tuning and assess the correlative and predictive capacities of task complexity heuristics in forecasting the outcomes of fine-tuning. Finally, we evaluate the latency and concurrency capabilities of LoRAX, an open-source Multi-LoRA inference server that facilitates the deployment of multiple LoRA fine-tuned models on a single GPU using shared base model weights and dynamic adapter loading. LoRAX powers LoRA Land, a web application that hosts 25 LoRA fine-tuned Mistral-7B LLMs on a single NVIDIA A100 GPU with 80GB memory. LoRA Land highlights the quality and cost-effectiveness of employing multiple specialized LLMs over a single, general-purpose LLM.
5/3/2024
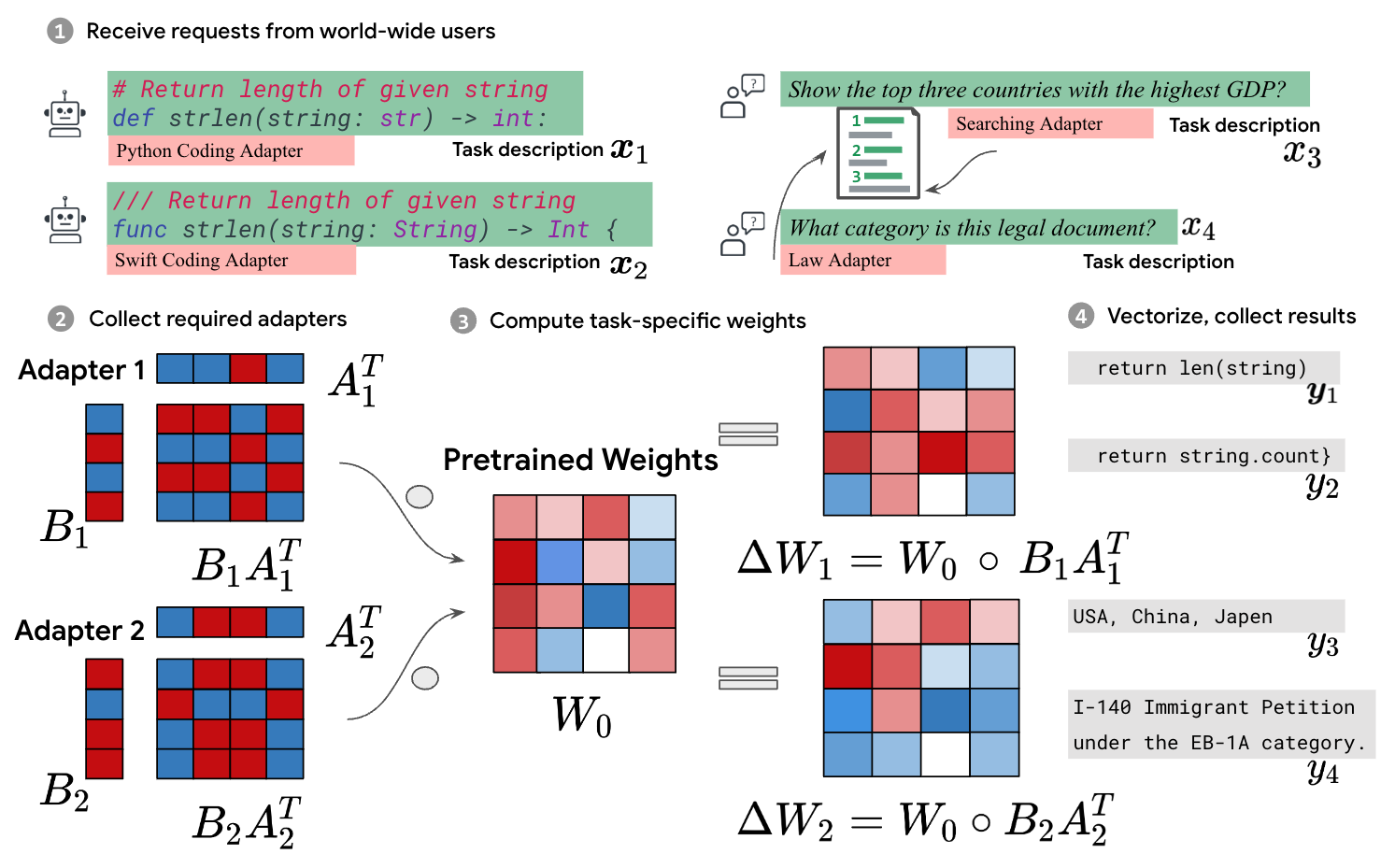
Batched Low-Rank Adaptation of Foundation Models
Yeming Wen, Swarat Chaudhuri
0
0
Low-Rank Adaptation (LoRA) has recently gained attention for fine-tuning foundation models by incorporating trainable low-rank matrices, thereby reducing the number of trainable parameters. While LoRA offers numerous advantages, its applicability for real-time serving to a diverse and global user base is constrained by its incapability to handle multiple task-specific adapters efficiently. This imposes a performance bottleneck in scenarios requiring personalized, task-specific adaptations for each incoming request. To mitigate this constraint, we introduce Fast LoRA (FLoRA), a framework in which each input example in a minibatch can be associated with its unique low-rank adaptation weights, allowing for efficient batching of heterogeneous requests. We empirically demonstrate that FLoRA retains the performance merits of LoRA, showcasing competitive results on the MultiPL-E code generation benchmark spanning over 8 languages and a multilingual speech recognition task across 6 languages.
4/29/2024

OLoRA: Orthonormal Low-Rank Adaptation of Large Language Models
Kerim Buyukakyuz
0
0
The advent of large language models (LLMs) has revolutionized natural language processing, enabling unprecedented capabilities in understanding and generating human-like text. However, the computational cost and convergence times associated with fine-tuning these models remain significant challenges. Low-Rank Adaptation (LoRA) has emerged as a promising method to mitigate these issues by introducing efficient fine-tuning techniques with a reduced number of trainable parameters. In this paper, we present OLoRA, an enhancement to the LoRA method that leverages orthonormal matrix initialization through QR decomposition. OLoRA significantly accelerates the convergence of LLM training while preserving the efficiency benefits of LoRA, such as the number of trainable parameters and GPU memory footprint. Our empirical evaluations demonstrate that OLoRA not only converges faster but also exhibits improved performance compared to standard LoRA across a variety of language modeling tasks. This advancement opens new avenues for more efficient and accessible fine-tuning of LLMs, potentially enabling broader adoption and innovation in natural language applications.
6/5/2024