Concept-Attention Whitening for Interpretable Skin Lesion Diagnosis
2404.05997
0
0

Abstract
The black-box nature of deep learning models has raised concerns about their interpretability for successful deployment in real-world clinical applications. To address the concerns, eXplainable Artificial Intelligence (XAI) aims to provide clear and understandable explanations of the decision-making process. In the medical domain, concepts such as attributes of lesions or abnormalities serve as key evidence for deriving diagnostic results. However, existing concept-based models mainly depend on concepts that appear independently and require fine-grained concept annotations such as bounding boxes. A medical image usually contains multiple concepts and the fine-grained concept annotations are difficult to acquire. In this paper, we propose a novel Concept-Attention Whitening (CAW) framework for interpretable skin lesion diagnosis. CAW is comprised of a disease diagnosis branch and a concept alignment branch. In the former branch, we train the CNN with a CAW layer inserted to perform skin lesion diagnosis. The CAW layer decorrelates features and aligns image features to conceptual meanings via an orthogonal matrix. In the latter branch, we calculate the orthogonal matrix under the guidance of the concept attention mask. We particularly introduce a weakly-supervised concept mask generator that only leverages coarse concept labels for filtering local regions that are relevant to certain concepts, improving the optimization of the orthogonal matrix. Extensive experiments on two public skin lesion diagnosis datasets demonstrated that CAW not only enhanced interpretability but also maintained a state-of-the-art diagnostic performance.
Create account to get full access
Overview
- This paper proposes a novel approach called "Concept-Attention Whitening" to improve the interpretability of skin lesion diagnosis models.
- The key idea is to leverage concept attention mechanisms to identify and highlight the most relevant visual concepts for a given skin lesion classification task.
- The proposed method aims to provide better explanations for the model's predictions, making the decision-making process more transparent and trustworthy.
Plain English Explanation
The paper presents a new way to build AI models that can diagnose skin conditions, such as different types of skin cancer, more transparently. Traditional AI models for skin lesion diagnosis can be accurate, but it's often difficult to understand how they make their decisions.
The researchers' approach, called "Concept-Attention Whitening," tries to address this issue. The main idea is to have the model not only classify the skin condition, but also explicitly identify the key visual features (or "concepts") it's focusing on to make that diagnosis. This allows the model to explain its reasoning in a more interpretable way.
For example, if the model is diagnosing a skin lesion as melanoma, it could highlight specific visual patterns like irregular borders or color variation that are driving that classification. By making the model's decision-making process more transparent, the researchers aim to build trust and confidence in the technology, especially for high-stakes medical applications.
Technical Explanation
The proposed "Concept-Attention Whitening" approach consists of two main components:
-
Disease Diagnosis Branch: This is a standard convolutional neural network (CNN) classifier that takes an input skin lesion image and predicts the disease class.
-
Concept Attention Mechanism: This module runs in parallel with the disease classifier. It learns to identify the most relevant visual concepts (e.g., texture, color, shape) for the classification task and generates an attention map highlighting these key features.
The key innovation is that the concept attention mechanism is designed to be orthogonal to the disease classifier. This "whitening" process ensures the attention maps capture unique, non-redundant visual information that complements the disease predictions. [link to "Explaining Explainability: Understanding Concept Activation Vectors"]
The authors evaluate their approach on a challenging skin lesion diagnosis dataset, demonstrating improved classification performance and more interpretable model explanations compared to previous methods. [link to "Advancing Ante-hoc Explainable Models through Generative"]
Critical Analysis
The paper presents a compelling approach for improving the interpretability of skin lesion diagnosis models. By explicitly modeling the relevant visual concepts, the Concept-Attention Whitening method provides a level of transparency that is often lacking in black-box AI systems.
However, the authors acknowledge some limitations of their work. The concept attention mechanism is dependent on the availability of detailed, labeled concept information, which may not always be easy to obtain, especially for complex medical tasks. [link to "Enhancing Breast Cancer Diagnosis from Mammography: Evaluation and Integration"]
Additionally, while the authors demonstrate improved classification performance, it's unclear how much the interpretability gains translate to real-world clinical benefits. Further research is needed to understand the impact of these explanations on clinician trust, decision-making, and patient outcomes. [link to "Clinical-Oriented Multi-level Contrastive Learning Method"]
Conclusion
The Concept-Attention Whitening approach represents a promising step towards more interpretable and trustworthy AI-powered skin lesion diagnosis. By explicitly modeling the visual concepts driving the model's decisions, the researchers have developed a technique that can provide valuable insights to clinicians and patients alike.
As the field of [link to "Language-Informed Visual Concept Learning"] continues to advance, approaches like this that prioritize interpretability and transparency will become increasingly important, especially in high-stakes domains like healthcare. The authors' work highlights the potential for AI to enhance, rather than replace, human medical expertise when the decision-making process is made more accessible and understandable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Aligning Human Knowledge with Visual Concepts Towards Explainable Medical Image Classification
Yunhe Gao, Difei Gu, Mu Zhou, Dimitris Metaxas
0
0
Although explainability is essential in the clinical diagnosis, most deep learning models still function as black boxes without elucidating their decision-making process. In this study, we investigate the explainable model development that can mimic the decision-making process of human experts by fusing the domain knowledge of explicit diagnostic criteria. We introduce a simple yet effective framework, Explicd, towards Explainable language-informed criteria-based diagnosis. Explicd initiates its process by querying domain knowledge from either large language models (LLMs) or human experts to establish diagnostic criteria across various concept axes (e.g., color, shape, texture, or specific patterns of diseases). By leveraging a pretrained vision-language model, Explicd injects these criteria into the embedding space as knowledge anchors, thereby facilitating the learning of corresponding visual concepts within medical images. The final diagnostic outcome is determined based on the similarity scores between the encoded visual concepts and the textual criteria embeddings. Through extensive evaluation of five medical image classification benchmarks, Explicd has demonstrated its inherent explainability and extends to improve classification performance compared to traditional black-box models.
6/11/2024

A Self-explaining Neural Architecture for Generalizable Concept Learning
Sanchit Sinha, Guangzhi Xiong, Aidong Zhang
0
0
With the wide proliferation of Deep Neural Networks in high-stake applications, there is a growing demand for explainability behind their decision-making process. Concept learning models attempt to learn high-level 'concepts' - abstract entities that align with human understanding, and thus provide interpretability to DNN architectures. However, in this paper, we demonstrate that present SOTA concept learning approaches suffer from two major problems - lack of concept fidelity wherein the models fail to learn consistent concepts among similar classes and limited concept interoperability wherein the models fail to generalize learned concepts to new domains for the same task. Keeping these in mind, we propose a novel self-explaining architecture for concept learning across domains which - i) incorporates a new concept saliency network for representative concept selection, ii) utilizes contrastive learning to capture representative domain invariant concepts, and iii) uses a novel prototype-based concept grounding regularization to improve concept alignment across domains. We demonstrate the efficacy of our proposed approach over current SOTA concept learning approaches on four widely used real-world datasets. Empirical results show that our method improves both concept fidelity measured through concept overlap and concept interoperability measured through domain adaptation performance.
5/7/2024
❗
Advancing Ante-Hoc Explainable Models through Generative Adversarial Networks
Tanmay Garg, Deepika Vemuri, Vineeth N Balasubramanian
0
0
This paper presents a novel concept learning framework for enhancing model interpretability and performance in visual classification tasks. Our approach appends an unsupervised explanation generator to the primary classifier network and makes use of adversarial training. During training, the explanation module is optimized to extract visual concepts from the classifier's latent representations, while the GAN-based module aims to discriminate images generated from concepts, from true images. This joint training scheme enables the model to implicitly align its internally learned concepts with human-interpretable visual properties. Comprehensive experiments demonstrate the robustness of our approach, while producing coherent concept activations. We analyse the learned concepts, showing their semantic concordance with object parts and visual attributes. We also study how perturbations in the adversarial training protocol impact both classification and concept acquisition. In summary, this work presents a significant step towards building inherently interpretable deep vision models with task-aligned concept representations - a key enabler for developing trustworthy AI for real-world perception tasks.
4/4/2024
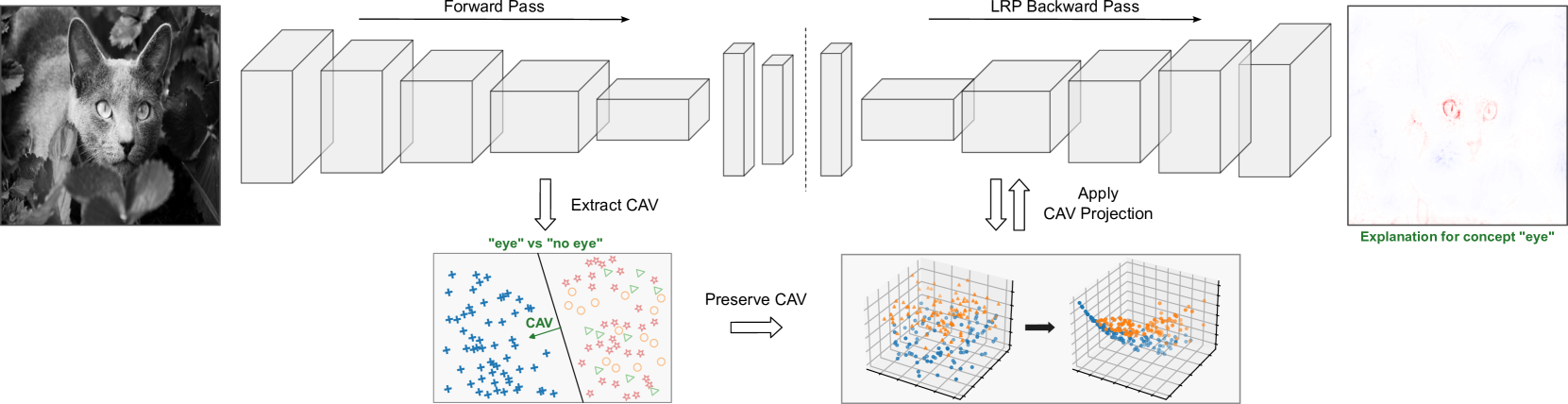
Locally Testing Model Detections for Semantic Global Concepts
Franz Motzkus, Georgii Mikriukov, Christian Hellert, Ute Schmid
0
0
Ensuring the quality of black-box Deep Neural Networks (DNNs) has become ever more significant, especially in safety-critical domains such as automated driving. While global concept encodings generally enable a user to test a model for a specific concept, linking global concept encodings to the local processing of single network inputs reveals their strengths and limitations. Our proposed framework global-to-local Concept Attribution (glCA) uses approaches from local (why a specific prediction originates) and global (how a model works generally) eXplainable Artificial Intelligence (xAI) to test DNNs for a predefined semantical concept locally. The approach allows for conditioning local, post-hoc explanations on predefined semantic concepts encoded as linear directions in the model's latent space. Pixel-exact scoring concerning the global concept usage assists the tester in further understanding the model processing of single data points for the selected concept. Our approach has the advantage of fully covering the model-internal encoding of the semantic concept and allowing the localization of relevant concept-related information. The results show major differences in the local perception and usage of individual global concept encodings and demand for further investigations regarding obtaining thorough semantic concept encodings.
5/30/2024