Concept Visualization: Explaining the CLIP Multi-modal Embedding Using WordNet
2405.14563
0
0
🛠️
Abstract
Advances in multi-modal embeddings, and in particular CLIP, have recently driven several breakthroughs in Computer Vision (CV). CLIP has shown impressive performance on a variety of tasks, yet, its inherently opaque architecture may hinder the application of models employing CLIP as backbone, especially in fields where trust and model explainability are imperative, such as in the medical domain. Current explanation methodologies for CV models rely on Saliency Maps computed through gradient analysis or input perturbation. However, these Saliency Maps can only be computed to explain classes relevant to the end task, often smaller in scope than the backbone training classes. In the context of models implementing CLIP as their vision backbone, a substantial portion of the information embedded within the learned representations is thus left unexplained. In this work, we propose Concept Visualization (ConVis), a novel saliency methodology that explains the CLIP embedding of an image by exploiting the multi-modal nature of the embeddings. ConVis makes use of lexical information from WordNet to compute task-agnostic Saliency Maps for any concept, not limited to concepts the end model was trained on. We validate our use of WordNet via an out of distribution detection experiment, and test ConVis on an object localization benchmark, showing that Concept Visualizations correctly identify and localize the image's semantic content. Additionally, we perform a user study demonstrating that our methodology can give users insight on the model's functioning.
Create account to get full access
Overview
- Recent advances in multi-modal embeddings, particularly CLIP, have led to breakthroughs in computer vision (CV).
- While CLIP has shown impressive performance, its opaque architecture can hinder the use of models that rely on it, especially in domains where trust and explainability are crucial, like healthcare.
- Current explainability methods for CV models, such as saliency maps, can only explain the model's understanding of classes relevant to the end task, missing key information in the CLIP embeddings.
Plain English Explanation
Multi-modal embeddings, which combine information from different data types like images and text, have recently driven significant progress in computer vision. One particularly successful example is CLIP, a model that can understand the relationship between images and their descriptions. CLIP has shown impressive performance on a variety of visual tasks, but its inner workings are not entirely transparent, which can be a problem in fields where it's important to understand and trust the model's decisions, like healthcare.
Current methods for explaining computer vision models rely on saliency maps, which highlight the parts of an image that are most important for the model's predictions. However, these saliency maps can only show what the model has learned about the specific classes it was trained on, missing a lot of the information encoded in the CLIP embeddings.
To address this, the researchers developed a new technique called Concept Visualization (ConVis) that uses the multi-modal nature of CLIP to explain its understanding of an image in a more comprehensive way. ConVis looks at the relationships between the image and a broad range of concepts from a lexical database called WordNet, rather than just the classes the model was trained on. This allows ConVis to shed light on a wider range of the information captured in the CLIP embeddings.
Technical Explanation
The researchers propose Concept Visualization (ConVis), a novel saliency methodology that explains the CLIP embedding of an image by exploiting the multi-modal nature of the embeddings. ConVis makes use of lexical information from WordNet to compute task-agnostic Saliency Maps for any concept, not limited to concepts the end model was trained on.
The authors validate their use of WordNet via an out-of-distribution detection experiment, and test ConVis on an object localization benchmark, showing that Concept Visualizations correctly identify and localize the image's semantic content. Additionally, they perform a user study demonstrating that their methodology can give users insight on the model's functioning.
Critical Analysis
The paper presents a promising approach for improving the explainability of models that use CLIP as a backbone, which is an important consideration for the deployment of such models, especially in sensitive domains. However, the authors acknowledge that ConVis is limited to explaining the information already present in the CLIP embeddings, and does not address potential issues with the concept alignment or skewed perceptions of CLIP itself.
Further research could explore ways to integrate ConVis with other explainability techniques or develop methods to directly improve the concept understanding of models like CLIP. Additionally, testing ConVis on a wider range of tasks and domains would help validate its broader applicability.
Conclusion
This work presents Concept Visualization (ConVis), a novel technique for explaining the inner workings of CLIP, a powerful multi-modal embedding model that has driven significant advances in computer vision. ConVis leverages the rich semantic information in WordNet to provide task-agnostic explanations of CLIP's understanding of images, going beyond the limitations of previous explainability methods. While more research is needed, ConVis represents an important step towards making models like CLIP more transparent and trustworthy, especially in high-stakes domains where explainability is crucial.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Understanding Multimodal Deep Neural Networks: A Concept Selection View
Chenming Shang, Hengyuan Zhang, Hao Wen, Yujiu Yang
0
0
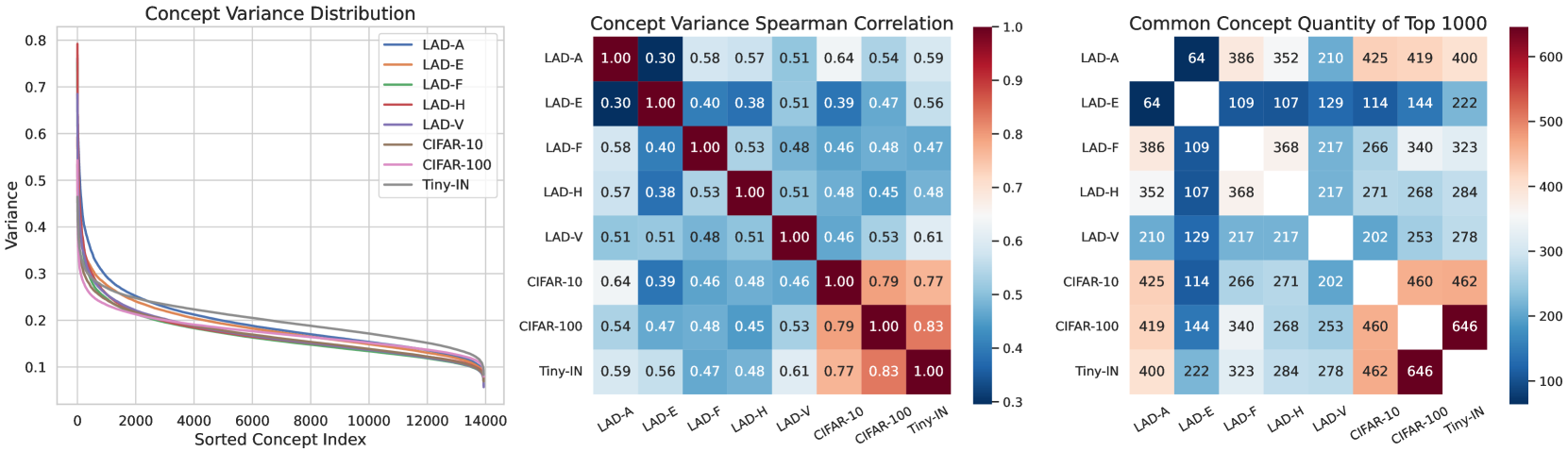
The multimodal deep neural networks, represented by CLIP, have generated rich downstream applications owing to their excellent performance, thus making understanding the decision-making process of CLIP an essential research topic. Due to the complex structure and the massive pre-training data, it is often regarded as a black-box model that is too difficult to understand and interpret. Concept-based models map the black-box visual representations extracted by deep neural networks onto a set of human-understandable concepts and use the concepts to make predictions, enhancing the transparency of the decision-making process. However, these methods involve the datasets labeled with fine-grained attributes by expert knowledge, which incur high costs and introduce excessive human prior knowledge and bias. In this paper, we observe the long-tail distribution of concepts, based on which we propose a two-stage Concept Selection Model (CSM) to mine core concepts without introducing any human priors. The concept greedy rough selection algorithm is applied to extract head concepts, and then the concept mask fine selection method performs the extraction of core concepts. Experiments show that our approach achieves comparable performance to end-to-end black-box models, and human evaluation demonstrates that the concepts discovered by our method are interpretable and comprehensible for humans.
4/16/2024
Concept-based Analysis of Neural Networks via Vision-Language Models
Ravi Mangal, Nina Narodytska, Divya Gopinath, Boyue Caroline Hu, Anirban Roy, Susmit Jha, Corina Pasareanu
0
0
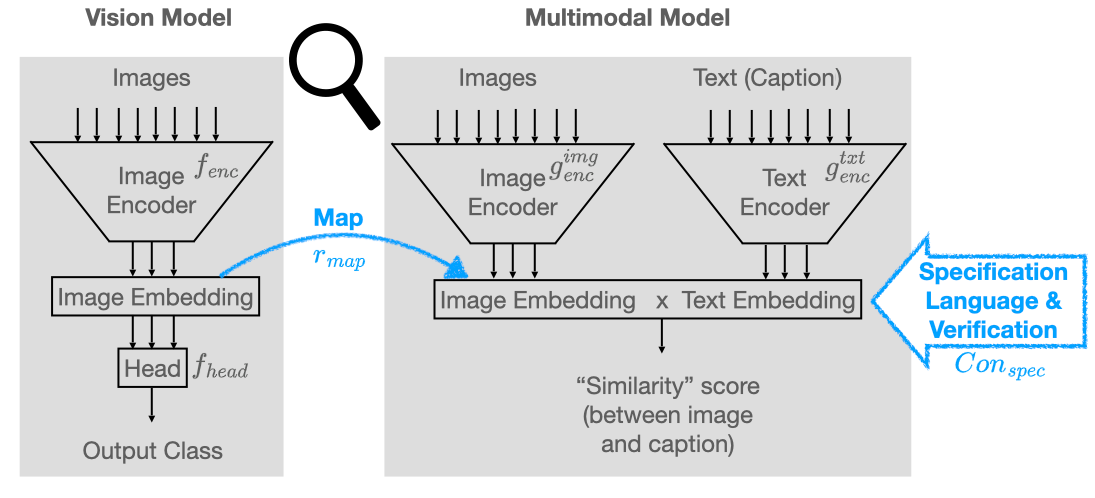
The analysis of vision-based deep neural networks (DNNs) is highly desirable but it is very challenging due to the difficulty of expressing formal specifications for vision tasks and the lack of efficient verification procedures. In this paper, we propose to leverage emerging multimodal, vision-language, foundation models (VLMs) as a lens through which we can reason about vision models. VLMs have been trained on a large body of images accompanied by their textual description, and are thus implicitly aware of high-level, human-understandable concepts describing the images. We describe a logical specification language $texttt{Con}_{texttt{spec}}$ designed to facilitate writing specifications in terms of these concepts. To define and formally check $texttt{Con}_{texttt{spec}}$ specifications, we build a map between the internal representations of a given vision model and a VLM, leading to an efficient verification procedure of natural-language properties for vision models. We demonstrate our techniques on a ResNet-based classifier trained on the RIVAL-10 dataset using CLIP as the multimodal model.
4/12/2024
🔍
Refining Skewed Perceptions in Vision-Language Models through Visual Representations
Haocheng Dai, Sarang Joshi
0
0
Large vision-language models (VLMs), such as CLIP, have become foundational, demonstrating remarkable success across a variety of downstream tasks. Despite their advantages, these models, akin to other foundational systems, inherit biases from the disproportionate distribution of real-world data, leading to misconceptions about the actual environment. Prevalent datasets like ImageNet are often riddled with non-causal, spurious correlations that can diminish VLM performance in scenarios where these contextual elements are absent. This study presents an investigation into how a simple linear probe can effectively distill task-specific core features from CLIP's embedding for downstream applications. Our analysis reveals that the CLIP text representations are often tainted by spurious correlations, inherited in the biased pre-training dataset. Empirical evidence suggests that relying on visual representations from CLIP, as opposed to text embedding, is more practical to refine the skewed perceptions in VLMs, emphasizing the superior utility of visual representations in overcoming embedded biases. Our codes will be available here.
5/24/2024
Improving Concept Alignment in Vision-Language Concept Bottleneck Models
Nithish Muthuchamy Selvaraj, Xiaobao Guo, Bingquan Shen, Adams Wai-Kin Kong, Alex Kot
0
0
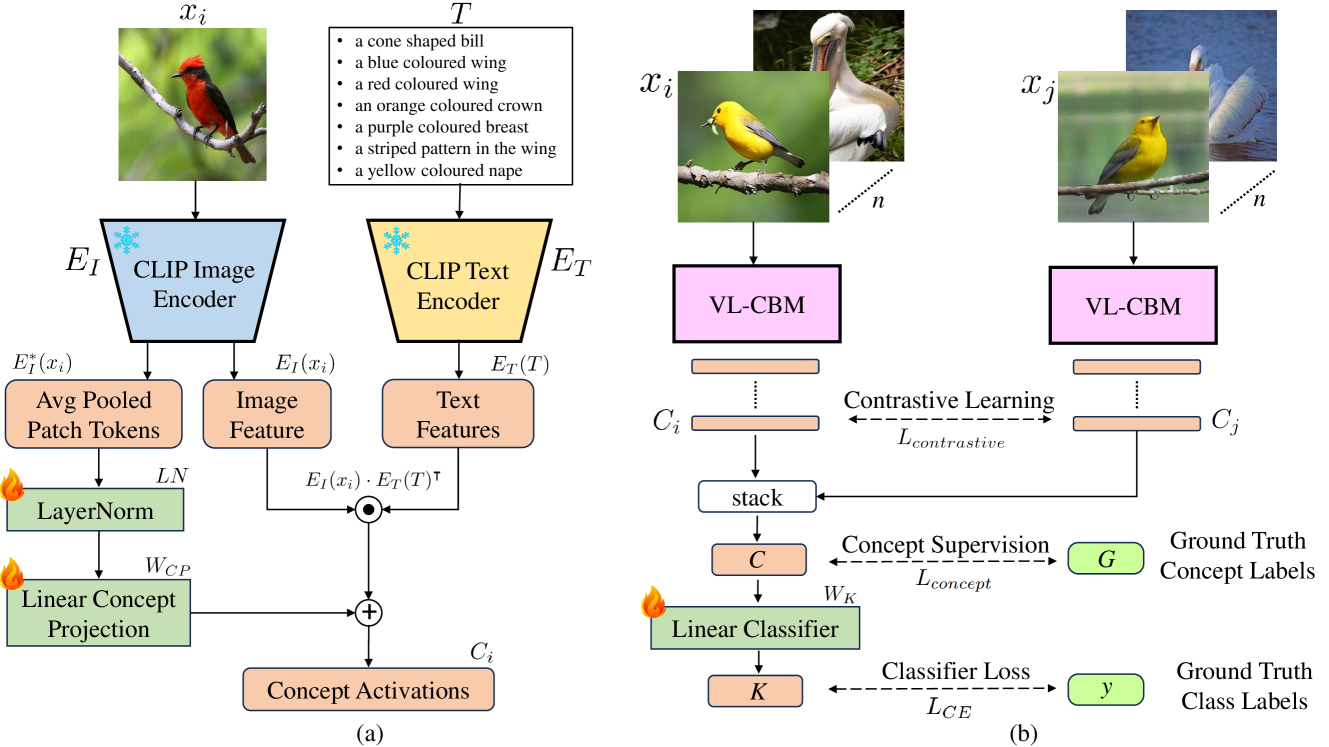
Concept Bottleneck Models (CBM) map the input image to a high-level human-understandable concept space and then make class predictions based on these concepts. Recent approaches automate the construction of CBM by prompting Large Language Models (LLM) to generate text concepts and then use Vision Language Models (VLM) to obtain concept scores to train a CBM. However, it is desired to build CBMs with concepts defined by human experts instead of LLM generated concepts to make them more trustworthy. In this work, we take a closer inspection on the faithfulness of VLM concept scores for such expert-defined concepts in domains like fine-grain bird species classification and animal classification. Our investigations reveal that frozen VLMs, like CLIP, struggle to correctly associate a concept to the corresponding visual input despite achieving a high classification performance. To address this, we propose a novel Contrastive Semi-Supervised (CSS) learning method which uses a few labeled concept examples to improve concept alignment (activate truthful visual concepts) in CLIP model. Extensive experiments on three benchmark datasets show that our approach substantially increases the concept accuracy and classification accuracy, yet requires only a fraction of the human-annotated concept labels. To further improve the classification performance, we also introduce a new class-level intervention procedure for fine-grain classification problems that identifies the confounding classes and intervenes their concept space to reduce errors.
5/6/2024