Improving Concept Alignment in Vision-Language Concept Bottleneck Models
2405.01825
0
0
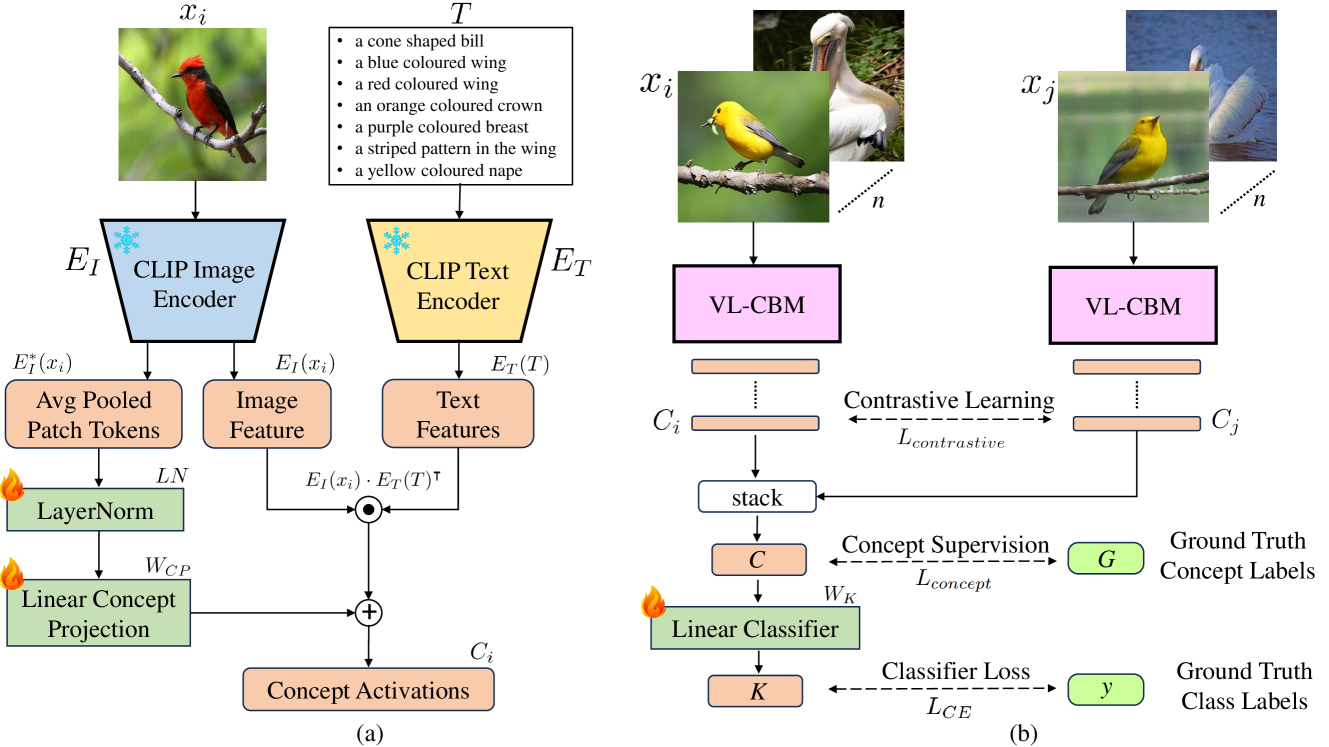
Abstract
Concept Bottleneck Models (CBM) map the input image to a high-level human-understandable concept space and then make class predictions based on these concepts. Recent approaches automate the construction of CBM by prompting Large Language Models (LLM) to generate text concepts and then use Vision Language Models (VLM) to obtain concept scores to train a CBM. However, it is desired to build CBMs with concepts defined by human experts instead of LLM generated concepts to make them more trustworthy. In this work, we take a closer inspection on the faithfulness of VLM concept scores for such expert-defined concepts in domains like fine-grain bird species classification and animal classification. Our investigations reveal that frozen VLMs, like CLIP, struggle to correctly associate a concept to the corresponding visual input despite achieving a high classification performance. To address this, we propose a novel Contrastive Semi-Supervised (CSS) learning method which uses a few labeled concept examples to improve concept alignment (activate truthful visual concepts) in CLIP model. Extensive experiments on three benchmark datasets show that our approach substantially increases the concept accuracy and classification accuracy, yet requires only a fraction of the human-annotated concept labels. To further improve the classification performance, we also introduce a new class-level intervention procedure for fine-grain classification problems that identifies the confounding classes and intervenes their concept space to reduce errors.
Create account to get full access
Overview
- This paper introduces a method to improve the alignment between visual concepts and their corresponding language representations in vision-language models.
- The authors propose a semi-supervised approach that leverages both labeled and unlabeled data to better associate visual features with their semantic meanings.
- The method aims to enhance the interpretability and robustness of vision-language models, particularly those that use a concept bottleneck architecture.
Plain English Explanation
Vision-language models are a type of artificial intelligence that can understand and process both visual and textual information. These models are often used for tasks like image captioning, where the AI generates a descriptive sentence about an image.
One challenge with these models is that the connection between the visual features they learn and the corresponding language concepts can be unclear. This makes it difficult to interpret how the model is making its decisions and understand its reasoning.
The researchers in this paper present a new approach to improve the alignment between the visual and language representations in these models. Their key insight is to leverage both labeled and unlabeled data during training.
Specifically, they use a semi-supervised learning technique that encourages the visual features to be more closely associated with their corresponding language concepts. This helps the model learn a stronger connection between what it sees in an image and the words it uses to describe it.
By improving this concept alignment, the researchers aim to make the vision-language models more interpretable and robust. This could be especially useful in sensitive applications, where it's important to understand how the AI is arriving at its decisions.
Technical Explanation
The core of the researchers' approach is a semi-supervised concept alignment method for vision-language models that use a concept bottleneck architecture.
In this architecture, the model first learns to predict a set of discrete visual concepts from the input image. These concept predictions are then used as an intermediate representation to predict the final output, such as an image caption.
The key innovation is an additional loss term that encourages the model to align the predicted visual concepts with their corresponding language representations. This is done by leveraging both labeled data, where the ground-truth concepts are known, as well as unlabeled data, where the model must discover the concept-language associations on its own.
Specifically, the authors introduce a contrastive loss that pulls the language representation of a predicted concept closer to the ground-truth language representation (for labeled data), while pushing it away from language representations of other concepts (for both labeled and unlabeled data). This helps the model learn a tighter coupling between the visual and language domains.
The authors evaluate their approach on several vision-language benchmarks and find that it leads to improved performance, interpretability, and robustness compared to baseline concept bottleneck models. For example, the model becomes less susceptible to concept association bias, where it incorrectly associates visual features with language concepts.
Critical Analysis
The researchers present a compelling approach to address a key challenge in vision-language models: improving the alignment between visual and language representations. Their semi-supervised concept alignment method is a creative solution that leverages both labeled and unlabeled data to learn more coherent associations between visual features and language concepts.
One potential limitation of the work is that it focuses on a specific architectural choice (the concept bottleneck model) and may not generalize as well to other vision-language model designs. It would be interesting to see if the concept alignment techniques could be applied more broadly to other types of multimodal models.
Additionally, while the authors demonstrate improvements in interpretability and robustness, further research is needed to fully understand the extent and limits of these benefits. For example, it's unclear how the model would behave in more complex, real-world scenarios with higher levels of cross-modal hard negatives.
Overall, this work represents an important step forward in improving the intervention efficacy of vision-language models via concept realignment. The authors' insights into semi-supervised learning for multimodal representations could inspire further research in this direction and lead to more interpretable and robust AI systems.
Conclusion
This paper introduces a novel semi-supervised approach to improve the alignment between visual concepts and their corresponding language representations in vision-language models. By leveraging both labeled and unlabeled data, the method learns tighter couplings between the visual and language domains, enhancing the interpretability and robustness of the models.
The researchers demonstrate the effectiveness of their concept alignment technique on several benchmarks, showing improvements in performance, interpretability, and resilience to concept association bias. This work represents an important step forward in making vision-language models more transparent and trustworthy, which could be particularly valuable in sensitive applications.
While the current focus is on a specific architectural choice, the insights from this paper could inspire further research into improving the concept-based analysis of neural networks and enhancing the intervention efficacy of multimodal AI systems more broadly.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Semi-supervised Concept Bottleneck Models
Lijie Hu, Tianhao Huang, Huanyi Xie, Chenyang Ren, Zhengyu Hu, Lu Yu, Di Wang
0
0
Concept Bottleneck Models (CBMs) have garnered increasing attention due to their ability to provide concept-based explanations for black-box deep learning models while achieving high final prediction accuracy using human-like concepts. However, the training of current CBMs heavily relies on the accuracy and richness of annotated concepts in the dataset. These concept labels are typically provided by experts, which can be costly and require significant resources and effort. Additionally, concept saliency maps frequently misalign with input saliency maps, causing concept predictions to correspond to irrelevant input features - an issue related to annotation alignment. To address these limitations, we propose a new framework called SSCBM (Semi-supervised Concept Bottleneck Model). Our SSCBM is suitable for practical situations where annotated data is scarce. By leveraging joint training on both labeled and unlabeled data and aligning the unlabeled data at the concept level, we effectively solve these issues. We proposed a strategy to generate pseudo labels and an alignment loss. Experiments demonstrate that our SSCBM is both effective and efficient. With only 20% labeled data, we achieved 93.19% (96.39% in a fully supervised setting) concept accuracy and 75.51% (79.82% in a fully supervised setting) prediction accuracy.
6/28/2024

Improving Intervention Efficacy via Concept Realignment in Concept Bottleneck Models
Nishad Singhi, Jae Myung Kim, Karsten Roth, Zeynep Akata
0
0
Concept Bottleneck Models (CBMs) ground image classification on human-understandable concepts to allow for interpretable model decisions. Crucially, the CBM design inherently allows for human interventions, in which expert users are given the ability to modify potentially misaligned concept choices to influence the decision behavior of the model in an interpretable fashion. However, existing approaches often require numerous human interventions per image to achieve strong performances, posing practical challenges in scenarios where obtaining human feedback is expensive. In this paper, we find that this is noticeably driven by an independent treatment of concepts during intervention, wherein a change of one concept does not influence the use of other ones in the model's final decision. To address this issue, we introduce a trainable concept intervention realignment module, which leverages concept relations to realign concept assignments post-intervention. Across standard, real-world benchmarks, we find that concept realignment can significantly improve intervention efficacy; significantly reducing the number of interventions needed to reach a target classification performance or concept prediction accuracy. In addition, it easily integrates into existing concept-based architectures without requiring changes to the models themselves. This reduced cost of human-model collaboration is crucial to enhancing the feasibility of CBMs in resource-constrained environments.
5/3/2024

Conceptual Learning via Embedding Approximations for Reinforcing Interpretability and Transparency
Maor Dikter, Tsachi Blau, Chaim Baskin
0
0
Concept bottleneck models (CBMs) have emerged as critical tools in domains where interpretability is paramount. These models rely on predefined textual descriptions, referred to as concepts, to inform their decision-making process and offer more accurate reasoning. As a result, the selection of concepts used in the model is of utmost significance. This study proposes underline{textbf{C}}onceptual underline{textbf{L}}earning via underline{textbf{E}}mbedding underline{textbf{A}}pproximations for underline{textbf{R}}einforcing Interpretability and Transparency, abbreviated as CLEAR, a framework for constructing a CBM for image classification. Using score matching and Langevin sampling, we approximate the embedding of concepts within the latent space of a vision-language model (VLM) by learning the scores associated with the joint distribution of images and concepts. A concept selection process is then employed to optimize the similarity between the learned embeddings and the predefined ones. The derived bottleneck offers insights into the CBM's decision-making process, enabling more comprehensive interpretations. Our approach was evaluated through extensive experiments and achieved state-of-the-art performance on various benchmarks. The code for our experiments is available at https://github.com/clearProject/CLEAR/tree/main
6/14/2024

Enhancing Fine-Grained Image Classifications via Cascaded Vision Language Models
Canshi Wei
0
0
Fine-grained image classification, particularly in zero/few-shot scenarios, presents a significant challenge for vision-language models (VLMs), such as CLIP. These models often struggle with the nuanced task of distinguishing between semantically similar classes due to limitations in their pre-trained recipe, which lacks supervision signals for fine-grained categorization. This paper introduces CascadeVLM, an innovative framework that overcomes the constraints of previous CLIP-based methods by effectively leveraging the granular knowledge encapsulated within large vision-language models (LVLMs). Experiments across various fine-grained image datasets demonstrate that CascadeVLM significantly outperforms existing models, specifically on the Stanford Cars dataset, achieving an impressive 85.6% zero-shot accuracy. Performance gain analysis validates that LVLMs produce more accurate predictions for challenging images that CLIPs are uncertain about, bringing the overall accuracy boost. Our framework sheds light on a holistic integration of VLMs and LVLMs for effective and efficient fine-grained image classification.
5/21/2024