Concept-based Analysis of Neural Networks via Vision-Language Models
2403.19837
0
0
Abstract
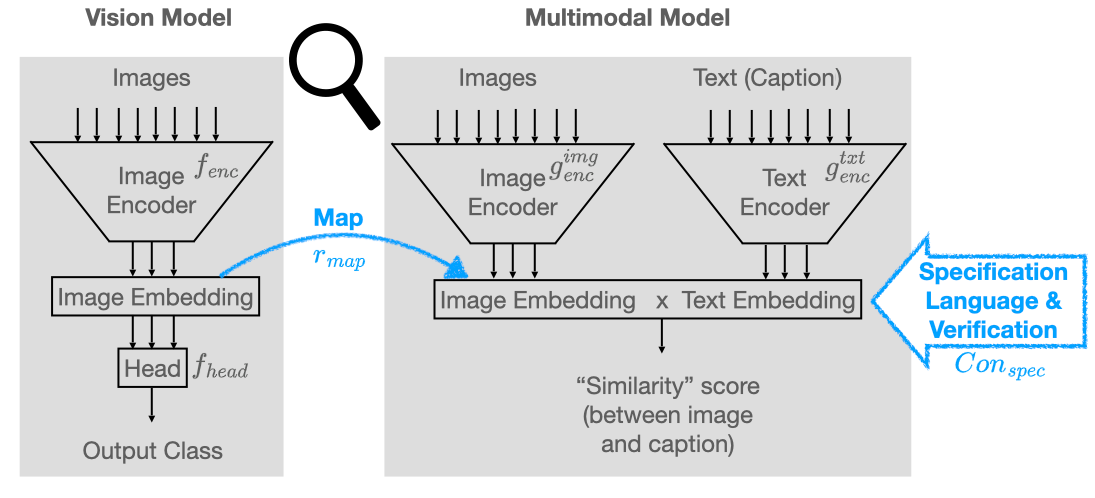
The analysis of vision-based deep neural networks (DNNs) is highly desirable but it is very challenging due to the difficulty of expressing formal specifications for vision tasks and the lack of efficient verification procedures. In this paper, we propose to leverage emerging multimodal, vision-language, foundation models (VLMs) as a lens through which we can reason about vision models. VLMs have been trained on a large body of images accompanied by their textual description, and are thus implicitly aware of high-level, human-understandable concepts describing the images. We describe a logical specification language $texttt{Con}
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents a concept-based analysis of neural networks using vision-language models.
- The researchers aim to better understand how neural networks make decisions by analyzing the concepts they rely on.
- They use vision-language models, which can connect visual and textual information, to probe the conceptual understanding of neural networks.
Plain English Explanation
Neural networks are powerful machine learning models that can perform impressive tasks like image recognition and language processing. However, it can be challenging to understand exactly how they work under the hood. This paper explores a new approach to analyzing neural networks by looking at the "concepts" they rely on.
Imagine you're trying to classify an image of a dog. A neural network might recognize features like the animal's shape, fur, and facial features to determine it's a dog. But what specific concepts is the network using to make that decision? The researchers in this paper use vision-language models - systems that can connect visual and textual information - to probe the internal workings of neural networks and uncover the key concepts they're based on.
By analyzing the language descriptions that align with the network's decisions, the researchers can see what higher-level ideas the network is picking up on, rather than just low-level visual features. This provides a new window into understanding how neural networks "think" and make their choices. Ultimately, this type of concept-based analysis could lead to more transparent and interpretable neural network models.
Technical Explanation
The paper first outlines the key components of a standard neural network classifier. It then introduces the concept of "vision-language models" - deep learning systems that can associate visual and textual information. The researchers leverage these vision-language models to analyze the conceptual underpinnings of neural network classifiers.
Specifically, they use a technique called "concept activation vectors" (CAVs), which quantify how strongly a neural network's internal representations align with specific linguistic concepts. By examining the CAVs, the researchers can identify the key concepts that most influence the network's decisions.
The paper describes experiments applying this concept-based analysis to various image classification tasks and neural network architectures. The results show that the identified concepts provide valuable insights into how the networks operate, beyond just their final outputs. The analysis reveals both expected conceptual associations as well as surprising ones that merit further investigation.
Critical Analysis
The paper presents a compelling new approach for analyzing neural networks, moving beyond just evaluating their performance to gaining deeper insights into their decision-making mechanisms. The use of vision-language models is a clever way to bridge the gap between the network's internal representations and human-interpretable concepts.
That said, the concept-based analysis is still limited by the linguistic knowledge encoded in the vision-language models. There may be important conceptual factors that are not well captured by the current language models. Additionally, the experiments focus on image classification, and it's unclear how well this approach would generalize to other domains like natural language processing.
Further research is needed to fully understand the strengths and limitations of this concept-based analysis technique. Applying it to a wider range of neural network models and tasks, as well as exploring ways to expand the conceptual knowledge base, could lead to valuable refinements and extensions of this work.
Conclusion
This paper introduces a novel concept-based framework for analyzing neural networks using vision-language models. By uncovering the key conceptual underpinnings of neural network decisions, this approach offers a promising path toward more interpretable and transparent machine learning systems. While still an early-stage technique, the insights gained from this type of analysis could have far-reaching implications for the development of reliable and trustworthy AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Exploring the Frontier of Vision-Language Models: A Survey of Current Methodologies and Future Directions
Akash Ghosh, Arkadeep Acharya, Sriparna Saha, Vinija Jain, Aman Chadha
0
0
The advent of Large Language Models (LLMs) has significantly reshaped the trajectory of the AI revolution. Nevertheless, these LLMs exhibit a notable limitation, as they are primarily adept at processing textual information. To address this constraint, researchers have endeavored to integrate visual capabilities with LLMs, resulting in the emergence of Vision-Language Models (VLMs). These advanced models are instrumental in tackling more intricate tasks such as image captioning and visual question answering. In our comprehensive survey paper, we delve into the key advancements within the realm of VLMs. Our classification organizes VLMs into three distinct categories: models dedicated to vision-language understanding, models that process multimodal inputs to generate unimodal (textual) outputs and models that both accept and produce multimodal inputs and outputs.This classification is based on their respective capabilities and functionalities in processing and generating various modalities of data.We meticulously dissect each model, offering an extensive analysis of its foundational architecture, training data sources, as well as its strengths and limitations wherever possible, providing readers with a comprehensive understanding of its essential components. We also analyzed the performance of VLMs in various benchmark datasets. By doing so, we aim to offer a nuanced understanding of the diverse landscape of VLMs. Additionally, we underscore potential avenues for future research in this dynamic domain, anticipating further breakthroughs and advancements.
4/16/2024
🤔
Probing Conceptual Understanding of Large Visual-Language Models
Madeline Schiappa, Raiyaan Abdullah, Shehreen Azad, Jared Claypoole, Michael Cogswell, Ajay Divakaran, Yogesh Rawat
0
0
In recent years large visual-language (V+L) models have achieved great success in various downstream tasks. However, it is not well studied whether these models have a conceptual grasp of the visual content. In this work we focus on conceptual understanding of these large V+L models. To facilitate this study, we propose novel benchmarking datasets for probing three different aspects of content understanding, 1) textit{relations}, 2) textit{composition}, and 3) textit{context}. Our probes are grounded in cognitive science and help determine if a V+L model can, for example, determine if snow garnished with a man is implausible, or if it can identify beach furniture by knowing it is located on a beach. We experimented with many recent state-of-the-art V+L models and observe that these models mostly textit{fail to demonstrate} a conceptual understanding. This study reveals several interesting insights such as that textit{cross-attention} helps learning conceptual understanding, and that CNNs are better with textit{texture and patterns}, while Transformers are better at textit{color and shape}. We further utilize some of these insights and investigate a textit{simple finetuning technique} that rewards the three conceptual understanding measures with promising initial results. The proposed benchmarks will drive the community to delve deeper into conceptual understanding and foster advancements in the capabilities of large V+L models. The code and dataset is available at: url{https://tinyurl.com/vlm-robustness}
4/29/2024
Pre-trained Vision-Language Models Learn Discoverable Visual Concepts
Yuan Zang, Tian Yun, Hao Tan, Trung Bui, Chen Sun
0
0
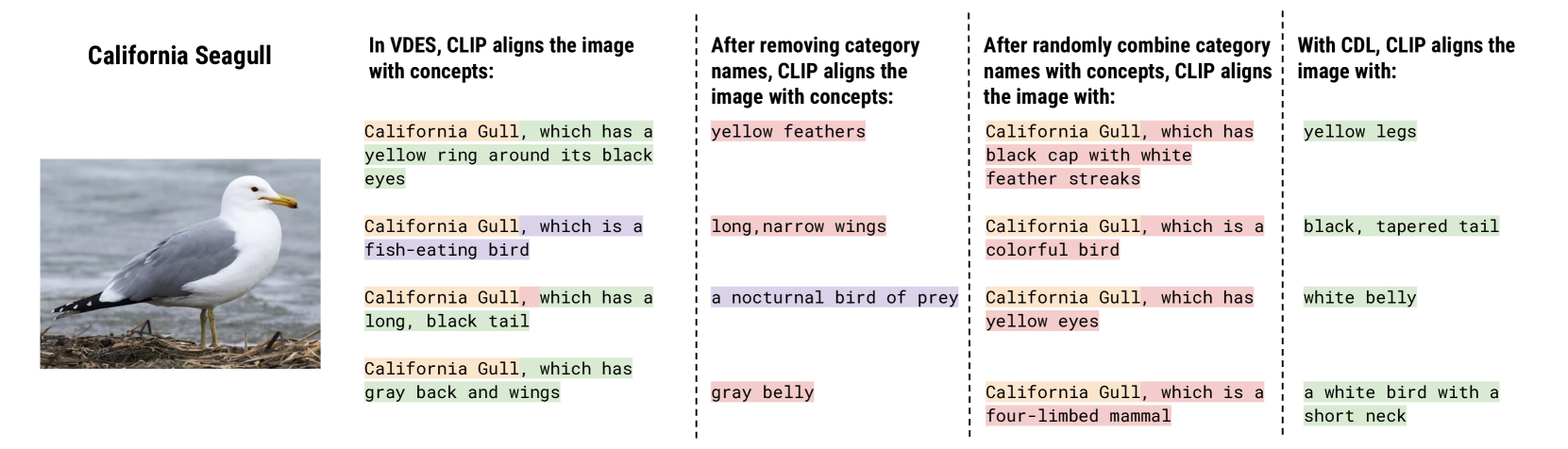
Do vision-language models (VLMs) pre-trained to caption an image of a durian learn visual concepts such as brown (color) and spiky (texture) at the same time? We aim to answer this question as visual concepts learned for free would enable wide applications such as neuro-symbolic reasoning or human-interpretable object classification. We assume that the visual concepts, if captured by pre-trained VLMs, can be extracted by their vision-language interface with text-based concept prompts. We observe that recent works prompting VLMs with concepts often differ in their strategies to define and evaluate the visual concepts, leading to conflicting conclusions. We propose a new concept definition strategy based on two observations: First, certain concept prompts include shortcuts that recognize correct concepts for wrong reasons; Second, multimodal information (e.g. visual discriminativeness, and textual knowledge) should be leveraged when selecting the concepts. Our proposed concept discovery and learning (CDL) framework is thus designed to identify a diverse list of generic visual concepts (e.g. spiky as opposed to spiky durian), which are ranked and selected based on visual and language mutual information. We carefully design quantitative and human evaluations of the discovered concepts on six diverse visual recognition datasets, which confirm that pre-trained VLMs do learn visual concepts that provide accurate and thorough descriptions for the recognized objects. All code and models are publicly released.
4/22/2024
Improving Concept Alignment in Vision-Language Concept Bottleneck Models
Nithish Muthuchamy Selvaraj, Xiaobao Guo, Bingquan Shen, Adams Wai-Kin Kong, Alex Kot
0
0
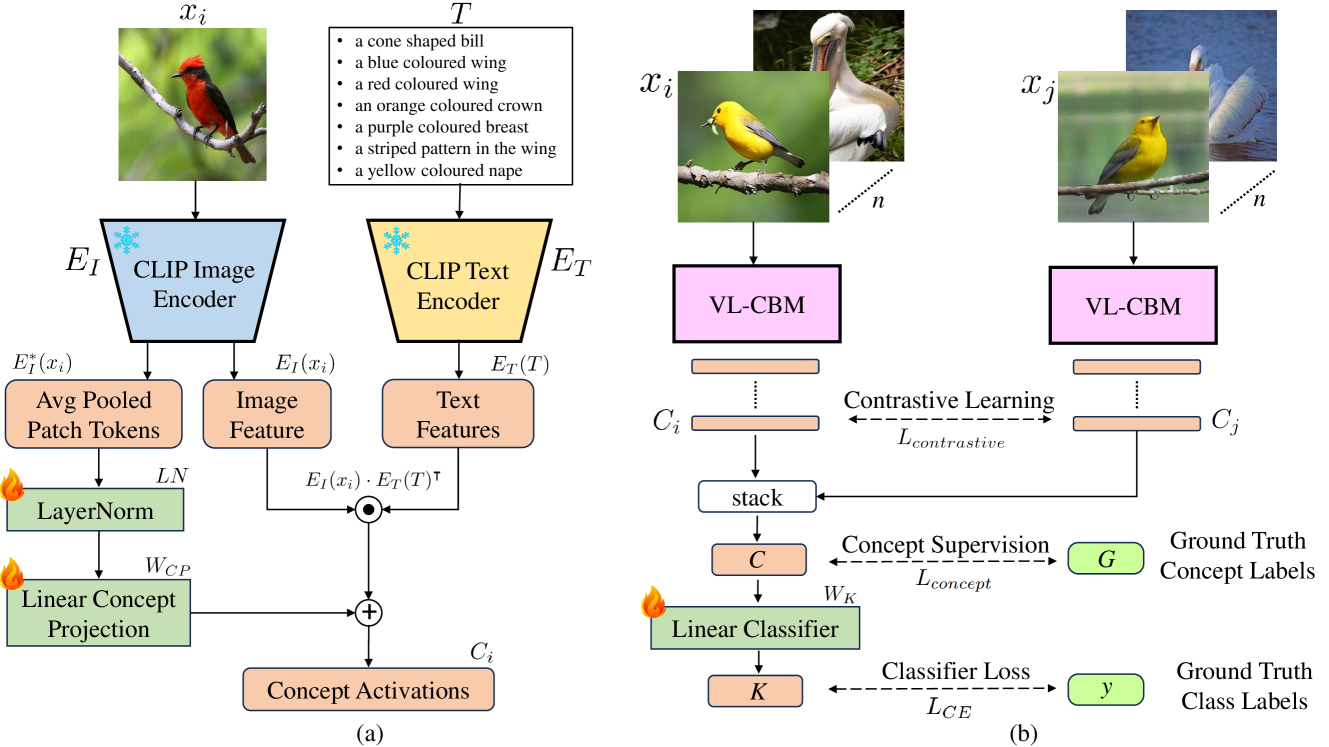
Concept Bottleneck Models (CBM) map the input image to a high-level human-understandable concept space and then make class predictions based on these concepts. Recent approaches automate the construction of CBM by prompting Large Language Models (LLM) to generate text concepts and then use Vision Language Models (VLM) to obtain concept scores to train a CBM. However, it is desired to build CBMs with concepts defined by human experts instead of LLM generated concepts to make them more trustworthy. In this work, we take a closer inspection on the faithfulness of VLM concept scores for such expert-defined concepts in domains like fine-grain bird species classification and animal classification. Our investigations reveal that frozen VLMs, like CLIP, struggle to correctly associate a concept to the corresponding visual input despite achieving a high classification performance. To address this, we propose a novel Contrastive Semi-Supervised (CSS) learning method which uses a few labeled concept examples to improve concept alignment (activate truthful visual concepts) in CLIP model. Extensive experiments on three benchmark datasets show that our approach substantially increases the concept accuracy and classification accuracy, yet requires only a fraction of the human-annotated concept labels. To further improve the classification performance, we also introduce a new class-level intervention procedure for fine-grain classification problems that identifies the confounding classes and intervenes their concept space to reduce errors.
5/6/2024