ConDL: Detector-Free Dense Image Matching

0

Sign in to get full access
Overview
- ConDL: Detector-Free Dense Image Matching is a research paper that proposes a novel approach for dense image matching without the need for keypoint detectors.
- The paper introduces a contrastive learning-based method to learn dense descriptors directly from image pairs, enabling dense correspondence estimation between images.
- The proposed method outperforms existing detector-free dense matching approaches on several benchmarks, demonstrating its effectiveness.
Plain English Explanation
In the world of computer vision, dense image matching is a crucial task that involves finding corresponding points between two images. This information can be used for various applications, such as 3D reconstruction, object tracking, and image alignment. Traditional approaches often rely on keypoint detectors to identify distinctive features in the images, which can be computationally expensive and may not always be accurate.
The researchers behind the ConDL paper have developed a novel method that eliminates the need for keypoint detectors. Instead, they use a contrastive learning-based approach to directly learn dense descriptors from image pairs. This means that the system can discover and match corresponding points without the intermediate step of detecting keypoints.
The key idea is to train the model to learn a feature representation that can capture the distinctive properties of each pixel in the image. By comparing the features of corresponding pixels in a pair of images, the model can establish dense correspondences without relying on predefined keypoints. This approach is more flexible and can potentially capture a richer set of correspondences, leading to improved performance on various tasks.
The researchers have evaluated their method on several benchmarks and found that it outperforms existing detector-free dense matching approaches. This suggests that their contrastive learning-based technique is a promising direction for advancing the field of dense image matching.
Technical Explanation
The ConDL paper proposes a Detector-Free Dense Image Matching method that leverages contrastive learning to learn dense descriptors directly from image pairs. The key idea is to train a neural network to learn a feature representation that can capture the distinctive properties of each pixel in the image, enabling dense correspondence estimation without the need for keypoint detectors.
The authors introduce a Contrastive Descriptor Learning (ConDL) framework that consists of two main components: a feature extraction backbone and a contrastive learning module. The feature extraction backbone, which can be any standard convolutional neural network, is used to generate dense feature maps for the input images. The contrastive learning module then compares the features of corresponding pixels in a pair of images, encouraging the model to learn a representation that can effectively capture dense correspondences.
During training, the model is presented with pairs of images and their corresponding ground-truth dense matches. The contrastive learning objective encourages the model to learn features that are similar for corresponding pixels and dissimilar for non-corresponding pixels. This allows the model to discover and match distinctive patterns in the images, without the need for predefined keypoints.
The authors evaluate their ConDL method on several dense matching benchmarks, including FreeReg and CycleCorrespondence. The results show that their approach outperforms existing detector-free dense matching methods, demonstrating the effectiveness of the contrastive learning-based technique.
Critical Analysis
The ConDL paper presents a promising approach for dense image matching that avoids the need for keypoint detectors. By directly learning dense descriptors through contrastive learning, the method can potentially capture a more comprehensive set of correspondences compared to traditional keypoint-based approaches.
One potential limitation of the proposed method is its reliance on ground-truth dense matches for training. In real-world scenarios, obtaining accurate dense correspondence annotations can be challenging and labor-intensive. The authors acknowledge this issue and suggest exploring self-supervised or weakly-supervised approaches as a future research direction.
Additionally, the paper focuses on evaluating the method on relatively small-scale datasets. It would be valuable to see how the ConDL approach performs on larger and more diverse datasets, as well as in more complex real-world applications, such as large-scale 3D reconstruction or object tracking.
Another area for further investigation is the robustness of the learned descriptors to various image transformations and perturbations. Ensuring that the dense correspondences are stable and reliable under different conditions is crucial for practical applications.
Overall, the ConDL paper presents an interesting and promising approach to address the limitations of traditional keypoint-based dense matching methods. The contrastive learning-based technique shows strong potential, and further research in this direction could lead to significant advancements in the field of dense image matching.
Conclusion
The ConDL paper introduces a novel Detector-Free Dense Image Matching method that leverages contrastive learning to directly learn dense descriptors from image pairs. This approach eliminates the need for keypoint detectors, which can be computationally expensive and may not always be accurate.
The proposed ConDL framework outperforms existing detector-free dense matching methods on several benchmarks, demonstrating the effectiveness of the contrastive learning-based technique. This suggests that the method could be a promising direction for advancing the field of dense image matching and enabling a wide range of applications, such as 3D reconstruction, object tracking, and image alignment.
While the paper presents a strong initial contribution, there are opportunities for further research, such as exploring self-supervised or weakly-supervised approaches to address the challenge of obtaining accurate dense correspondence annotations, and evaluating the method on larger and more diverse datasets. Addressing these areas could lead to even more robust and practical dense image matching solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ConDL: Detector-Free Dense Image Matching
Monika Kwiatkowski, Simon Matern, Olaf Hellwich
In this work, we introduce a deep-learning framework designed for estimating dense image correspondences. Our fully convolutional model generates dense feature maps for images, where each pixel is associated with a descriptor that can be matched across multiple images. Unlike previous methods, our model is trained on synthetic data that includes significant distortions, such as perspective changes, illumination variations, shadows, and specular highlights. Utilizing contrastive learning, our feature maps achieve greater invariance to these distortions, enabling robust matching. Notably, our method eliminates the need for a keypoint detector, setting it apart from many existing image-matching techniques.
Read more8/7/2024

0
Are Semi-Dense Detector-Free Methods Good at Matching Local Features?
Matthieu Vilain, R'emi Giraud, Hugo Germain, Guillaume Bourmaud
Semi-dense detector-free approaches (SDF), such as LoFTR, are currently among the most popular image matching methods. While SDF methods are trained to establish correspondences between two images, their performances are almost exclusively evaluated using relative pose estimation metrics. Thus, the link between their ability to establish correspondences and the quality of the resulting estimated pose has thus far received little attention. This paper is a first attempt to study this link. We start with proposing a novel structured attention-based image matching architecture (SAM). It allows us to show a counter-intuitive result on two datasets (MegaDepth and HPatches): on the one hand SAM either outperforms or is on par with SDF methods in terms of pose/homography estimation metrics, but on the other hand SDF approaches are significantly better than SAM in terms of matching accuracy. We then propose to limit the computation of the matching accuracy to textured regions, and show that in this case SAM often surpasses SDF methods. Our findings highlight a strong correlation between the ability to establish accurate correspondences in textured regions and the accuracy of the resulting estimated pose/homography. Our code will be made available.
Read more6/4/2024
0
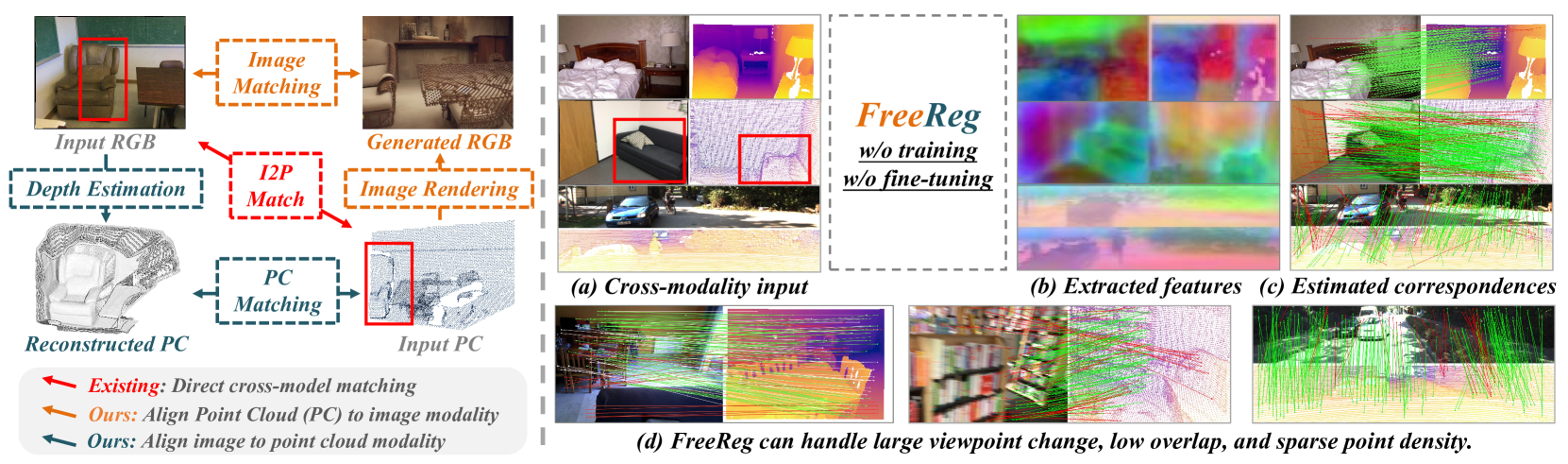
FreeReg: Image-to-Point Cloud Registration Leveraging Pretrained Diffusion Models and Monocular Depth Estimators
Haiping Wang, Yuan Liu, Bing Wang, Yujing Sun, Zhen Dong, Wenping Wang, Bisheng Yang
Matching cross-modality features between images and point clouds is a fundamental problem for image-to-point cloud registration. However, due to the modality difference between images and points, it is difficult to learn robust and discriminative cross-modality features by existing metric learning methods for feature matching. Instead of applying metric learning on cross-modality data, we propose to unify the modality between images and point clouds by pretrained large-scale models first, and then establish robust correspondence within the same modality. We show that the intermediate features, called diffusion features, extracted by depth-to-image diffusion models are semantically consistent between images and point clouds, which enables the building of coarse but robust cross-modality correspondences. We further extract geometric features on depth maps produced by the monocular depth estimator. By matching such geometric features, we significantly improve the accuracy of the coarse correspondences produced by diffusion features. Extensive experiments demonstrate that without any task-specific training, direct utilization of both features produces accurate image-to-point cloud registration. On three public indoor and outdoor benchmarks, the proposed method averagely achieves a 20.6 percent improvement in Inlier Ratio, a three-fold higher Inlier Number, and a 48.6 percent improvement in Registration Recall than existing state-of-the-arts.
Read more4/16/2024
⚙️
0
iMatching: Imperative Correspondence Learning
Zitong Zhan, Dasong Gao, Yun-Jou Lin, Youjie Xia, Chen Wang
Learning feature correspondence is a foundational task in computer vision, holding immense importance for downstream applications such as visual odometry and 3D reconstruction. Despite recent progress in data-driven models, feature correspondence learning is still limited by the lack of accurate per-pixel correspondence labels. To overcome this difficulty, we introduce a new self-supervised scheme, imperative learning (IL), for training feature correspondence. It enables correspondence learning on arbitrary uninterrupted videos without any camera pose or depth labels, heralding a new era for self-supervised correspondence learning. Specifically, we formulated the problem of correspondence learning as a bilevel optimization, which takes the reprojection error from bundle adjustment as a supervisory signal for the model. To avoid large memory and computation overhead, we leverage the stationary point to effectively back-propagate the implicit gradients through bundle adjustment. Through extensive experiments, we demonstrate superior performance on tasks including feature matching and pose estimation, in which we obtained an average of 30% accuracy gain over the state-of-the-art matching models. This preprint corresponds to the Accepted Manuscript in European Conference on Computer Vision (ECCV) 2024.
Read more8/1/2024