CondTSF: One-line Plugin of Dataset Condensation for Time Series Forecasting

0

Sign in to get full access
Overview
- This paper proposes a one-line plugin called CondTSF that applies dataset condensation techniques to time series forecasting tasks.
- Dataset condensation aims to generate a small, synthetic dataset that can train machine learning models as effectively as the original, much larger dataset.
- The authors demonstrate that CondTSF can improve the performance of time series forecasting models while significantly reducing the required training data.
Plain English Explanation
Time series forecasting is the task of predicting future values based on historical data. This is an important problem with applications in areas like finance, weather prediction, and supply chain management. However, building accurate time series forecasting models often requires large datasets, which can be expensive and time-consuming to collect.
<a href="https://aimodels.fyi/papers/arxiv/calibrated-dataset-condensation-faster-hyperparameter-search">Dataset condensation</a> is a technique that addresses this challenge. The idea is to generate a small, synthetic dataset that can train machine learning models just as effectively as the original, much larger dataset. This means you can train your models on the condensed dataset instead, saving time and resources.
The paper introduces CondTSF, a one-line plugin that applies dataset condensation specifically to time series forecasting tasks. By using CondTSF, the authors show that you can reduce the amount of training data needed for time series forecasting while maintaining or even improving model performance.
Technical Explanation
The key innovation in this paper is the CondTSF plugin, which extends dataset condensation techniques to the time series forecasting domain. The authors build on previous work in <a href="https://aimodels.fyi/papers/arxiv/elucidating-design-space-dataset-condensation">dataset condensation</a> and <a href="https://aimodels.fyi/papers/arxiv/multisize-dataset-condensation">multi-size dataset condensation</a> to develop a method that can generate a small, synthetic dataset that captures the essential patterns in the original time series data.
The CondTSF plugin can be easily integrated into existing time series forecasting pipelines, requiring only a single line of code. It first generates a condensed dataset using the original time series data, and then trains the forecasting model on this smaller dataset instead of the full original data.
The authors evaluate CondTSF on several benchmark time series forecasting datasets and show that it can achieve comparable or better performance than training on the full original datasets, while using only a fraction of the data. This suggests that CondTSF can be a powerful tool for improving the efficiency and reducing the data requirements of time series forecasting models.
Critical Analysis
The authors provide a thorough empirical evaluation of CondTSF, demonstrating its effectiveness across multiple datasets and forecasting models. However, they do not delve into the specific mechanisms or design choices behind the condensation process. Further research could explore the <a href="https://aimodels.fyi/papers/arxiv/enabling-device-learning-via-experience-replay-efficient">inner workings</a> of the condensation algorithm and how it can be optimized for time series data.
Additionally, the paper does not address potential issues with dataset shift or distribution mismatch between the condensed and original datasets. It would be valuable to investigate the robustness of CondTSF to these types of distributional changes, which can be a common challenge in real-world time series forecasting applications.
Overall, the CondTSF plugin presents a promising approach to reducing the data requirements for time series forecasting, but further research is needed to fully understand its limitations and explore ways to <a href="https://aimodels.fyi/papers/arxiv/koopcon-new-approach-towards-smarter-less-complex">improve its performance and applicability</a>.
Conclusion
This paper introduces CondTSF, a one-line plugin that applies dataset condensation techniques to time series forecasting tasks. By generating a small, synthetic dataset that can train forecasting models as effectively as the original, much larger dataset, CondTSF has the potential to significantly improve the efficiency and reduce the data requirements of time series forecasting. The authors demonstrate the effectiveness of CondTSF on several benchmark datasets, opening up new avenues for more efficient and data-efficient time series forecasting in a variety of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CondTSF: One-line Plugin of Dataset Condensation for Time Series Forecasting
Jianrong Ding, Zhanyu Liu, Guanjie Zheng, Haiming Jin, Linghe Kong
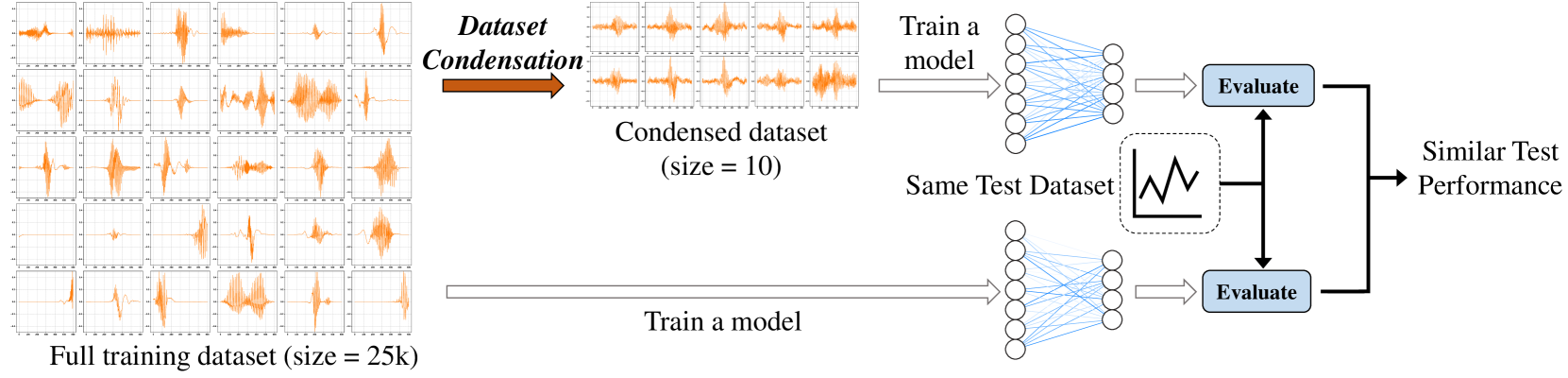
Dataset condensation is a newborn technique that generates a small dataset that can be used in training deep neural networks to lower training costs. The objective of dataset condensation is to ensure that the model trained with the synthetic dataset can perform comparably to the model trained with full datasets. However, existing methods predominantly concentrate on classification tasks, posing challenges in their adaptation to time series forecasting (TS-forecasting). This challenge arises from disparities in the evaluation of synthetic data. In classification, the synthetic data is considered well-distilled if the model trained with the full dataset and the model trained with the synthetic dataset yield identical labels for the same input, regardless of variations in output logits distribution. Conversely, in TS-forecasting, the effectiveness of synthetic data distillation is determined by the distance between predictions of the two models. The synthetic data is deemed well-distilled only when all data points within the predictions are similar. Consequently, TS-forecasting has a more rigorous evaluation methodology compared to classification. To mitigate this gap, we theoretically analyze the optimization objective of dataset condensation for TS-forecasting and propose a new one-line plugin of dataset condensation designated as Dataset Condensation for Time Series Forecasting (CondTSF) based on our analysis. Plugging CondTSF into previous dataset condensation methods facilitates a reduction in the distance between the predictions of the model trained with the full dataset and the model trained with the synthetic dataset, thereby enhancing performance. We conduct extensive experiments on eight commonly used time series datasets. CondTSF consistently improves the performance of all previous dataset condensation methods across all datasets, particularly at low condensing ratios.
Read more6/12/2024
0
Dataset Condensation for Time Series Classification via Dual Domain Matching
Zhanyu Liu, Ke Hao, Guanjie Zheng, Yanwei Yu
Time series data has been demonstrated to be crucial in various research fields. The management of large quantities of time series data presents challenges in terms of deep learning tasks, particularly for training a deep neural network. Recently, a technique named textit{Dataset Condensation} has emerged as a solution to this problem. This technique generates a smaller synthetic dataset that has comparable performance to the full real dataset in downstream tasks such as classification. However, previous methods are primarily designed for image and graph datasets, and directly adapting them to the time series dataset leads to suboptimal performance due to their inability to effectively leverage the rich information inherent in time series data, particularly in the frequency domain. In this paper, we propose a novel framework named Dataset textit{textbf{Cond}}ensation for textit{textbf{T}}ime textit{textbf{S}}eries textit{textbf{C}}lassification via Dual Domain Matching (textbf{CondTSC}) which focuses on the time series classification dataset condensation task. Different from previous methods, our proposed framework aims to generate a condensed dataset that matches the surrogate objectives in both the time and frequency domains. Specifically, CondTSC incorporates multi-view data augmentation, dual domain training, and dual surrogate objectives to enhance the dataset condensation process in the time and frequency domains. Through extensive experiments, we demonstrate the effectiveness of our proposed framework, which outperforms other baselines and learns a condensed synthetic dataset that exhibits desirable characteristics such as conforming to the distribution of the original data.
Read more6/11/2024

0
Calibrated Dataset Condensation for Faster Hyperparameter Search
Mucong Ding, Yuancheng Xu, Tahseen Rabbani, Xiaoyu Liu, Brian Gravelle, Teresa Ranadive, Tai-Ching Tuan, Furong Huang
Dataset condensation can be used to reduce the computational cost of training multiple models on a large dataset by condensing the training dataset into a small synthetic set. State-of-the-art approaches rely on matching the model gradients between the real and synthetic data. However, there is no theoretical guarantee of the generalizability of the condensed data: data condensation often generalizes poorly across hyperparameters/architectures in practice. This paper considers a different condensation objective specifically geared toward hyperparameter search. We aim to generate a synthetic validation dataset so that the validation-performance rankings of the models, with different hyperparameters, on the condensed and original datasets are comparable. We propose a novel hyperparameter-calibrated dataset condensation (HCDC) algorithm, which obtains the synthetic validation dataset by matching the hyperparameter gradients computed via implicit differentiation and efficient inverse Hessian approximation. Experiments demonstrate that the proposed framework effectively maintains the validation-performance rankings of models and speeds up hyperparameter/architecture search for tasks on both images and graphs.
Read more5/29/2024

0
Elucidating the Design Space of Dataset Condensation
Shitong Shao, Zikai Zhou, Huanran Chen, Zhiqiang Shen
Dataset condensation, a concept within data-centric learning, efficiently transfers critical attributes from an original dataset to a synthetic version, maintaining both diversity and realism. This approach significantly improves model training efficiency and is adaptable across multiple application areas. Previous methods in dataset condensation have faced challenges: some incur high computational costs which limit scalability to larger datasets (e.g., MTT, DREAM, and TESLA), while others are restricted to less optimal design spaces, which could hinder potential improvements, especially in smaller datasets (e.g., SRe2L, G-VBSM, and RDED). To address these limitations, we propose a comprehensive design framework that includes specific, effective strategies like implementing soft category-aware matching and adjusting the learning rate schedule. These strategies are grounded in empirical evidence and theoretical backing. Our resulting approach, Elucidate Dataset Condensation (EDC), establishes a benchmark for both small and large-scale dataset condensation. In our testing, EDC achieves state-of-the-art accuracy, reaching 48.6% on ImageNet-1k with a ResNet-18 model at an IPC of 10, which corresponds to a compression ratio of 0.78%. This performance exceeds those of SRe2L, G-VBSM, and RDED by margins of 27.3%, 17.2%, and 6.6%, respectively.
Read more5/7/2024