Confronting Reward Overoptimization for Diffusion Models: A Perspective of Inductive and Primacy Biases
2402.08552
0
0
🐍
Abstract
Bridging the gap between diffusion models and human preferences is crucial for their integration into practical generative workflows. While optimizing downstream reward models has emerged as a promising alignment strategy, concerns arise regarding the risk of excessive optimization with learned reward models, which potentially compromises ground-truth performance. In this work, we confront the reward overoptimization problem in diffusion model alignment through the lenses of both inductive and primacy biases. We first identify a mismatch between current methods and the temporal inductive bias inherent in the multi-step denoising process of diffusion models, as a potential source of reward overoptimization. Then, we surprisingly discover that dormant neurons in our critic model act as a regularization against reward overoptimization while active neurons reflect primacy bias. Motivated by these observations, we propose Temporal Diffusion Policy Optimization with critic active neuron Reset (TDPO-R), a policy gradient algorithm that exploits the temporal inductive bias of diffusion models and mitigates the primacy bias stemming from active neurons. Empirical results demonstrate the superior efficacy of our methods in mitigating reward overoptimization. Code is avaliable at https://github.com/ZiyiZhang27/tdpo.
Create account to get full access
Overview
- Bridging the gap between diffusion models and human preferences is crucial for their practical use.
- Optimizing reward models is a promising alignment strategy, but there are concerns about reward overoptimization compromising performance.
- This paper addresses the reward overoptimization problem in diffusion model alignment through the lenses of inductive and primacy biases.
Plain English Explanation
Diffusion models are a powerful type of generative model that can create new images, text, and other data. However, integrating these models into real-world applications can be challenging, as they may not always align with what humans prefer.
One approach to address this is optimizing reward models, where a model is trained to predict how much humans will like the output. This can help diffusion models generate content that is more aligned with human preferences. However, there are concerns that this approach could lead to "reward overoptimization," where the model becomes too focused on maximizing the reward at the expense of other important factors.
In this paper, the researchers explore two potential sources of reward overoptimization: inductive bias and primacy bias. Inductive bias refers to the model's inherent tendency to learn certain patterns, while primacy bias means the model may prioritize early training data or signals over later ones.
The researchers find that the temporal nature of the diffusion process can lead to a mismatch between current methods and the model's inductive bias, contributing to reward overoptimization. They also discover that "dormant neurons" in the reward model can act as a regularizer against this issue, while "active neurons" reflect primacy bias.
Inspired by these insights, the researchers propose a new algorithm called Temporal Diffusion Policy Optimization with critic active neuron Reset (TDPO-R). This approach aims to exploit the temporal inductive bias of diffusion models and mitigate the primacy bias from active neurons. Their experiments show that TDPO-R is effective in reducing reward overoptimization.
Technical Explanation
The paper begins by acknowledging the importance of bridging the gap between diffusion models and human preferences for their integration into practical generative workflows. While optimizing downstream reward models has emerged as a promising alignment strategy, the authors raise concerns about the risk of excessive optimization with learned reward models, which could potentially compromise ground-truth performance.
To address this reward overoptimization problem, the researchers examine the issue through the lenses of both inductive and primacy biases. First, they identify a mismatch between current methods and the temporal inductive bias inherent in the multi-step denoising process of diffusion models as a potential source of reward overoptimization.
Surprisingly, the authors then discover that dormant neurons in the critic model act as a regularization against reward overoptimization, while active neurons reflect primacy bias. Motivated by these observations, they propose the TDPO-R algorithm, which exploits the temporal inductive bias of diffusion models and mitigates the primacy bias stemming from active neurons.
The empirical results presented in the paper demonstrate the superior efficacy of the TDPO-R method in mitigating reward overoptimization compared to other approaches.
Critical Analysis
The paper provides a thoughtful and well-designed approach to addressing the important challenge of aligning diffusion models with human preferences. The researchers' insights into the roles of inductive and primacy biases in the reward overoptimization problem are particularly interesting and could have broader implications for the field of AI alignment.
However, one potential limitation of the work is that it focuses primarily on the reward model optimization process, without delving deeply into the implications for the broader diffusion model training and deployment. It would be valuable to understand how the proposed TDPO-R algorithm might interact with or complement other techniques for aligning diffusion models, such as pixel-wise reinforcement learning or distributional preference reward modeling.
Additionally, while the paper presents promising empirical results, it would be helpful to see further evaluation of the method's scalability, robustness, and generalizability to a wider range of diffusion model architectures and application domains.
Conclusion
This paper tackles the crucial challenge of bridging the gap between diffusion models and human preferences, which is essential for the practical integration of these powerful generative models. By addressing the reward overoptimization problem through the lens of inductive and primacy biases, the researchers have developed a novel algorithm, TDPO-R, that demonstrates promising results in mitigating this issue.
The insights gained from this work could have broader implications for the field of AI alignment, potentially informing the development of more robust and human-centered generative models. As the use of diffusion models continues to grow, research like this will be increasingly important in ensuring these models are aligned with human values and preferences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
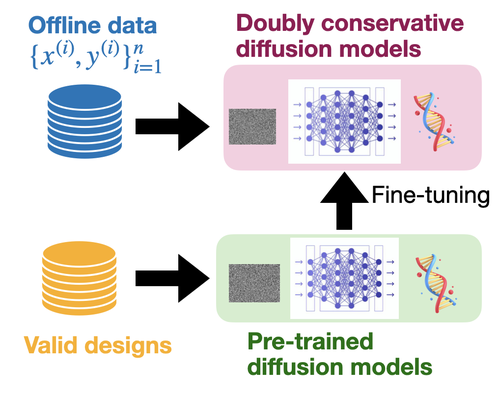
Bridging Model-Based Optimization and Generative Modeling via Conservative Fine-Tuning of Diffusion Models
Masatoshi Uehara, Yulai Zhao, Ehsan Hajiramezanali, Gabriele Scalia, Gokcen Eraslan, Avantika Lal, Sergey Levine, Tommaso Biancalani
0
0
AI-driven design problems, such as DNA/protein sequence design, are commonly tackled from two angles: generative modeling, which efficiently captures the feasible design space (e.g., natural images or biological sequences), and model-based optimization, which utilizes reward models for extrapolation. To combine the strengths of both approaches, we adopt a hybrid method that fine-tunes cutting-edge diffusion models by optimizing reward models through RL. Although prior work has explored similar avenues, they primarily focus on scenarios where accurate reward models are accessible. In contrast, we concentrate on an offline setting where a reward model is unknown, and we must learn from static offline datasets, a common scenario in scientific domains. In offline scenarios, existing approaches tend to suffer from overoptimization, as they may be misled by the reward model in out-of-distribution regions. To address this, we introduce a conservative fine-tuning approach, BRAID, by optimizing a conservative reward model, which includes additional penalization outside of offline data distributions. Through empirical and theoretical analysis, we demonstrate the capability of our approach to outperform the best designs in offline data, leveraging the extrapolation capabilities of reward models while avoiding the generation of invalid designs through pre-trained diffusion models.
6/4/2024
🔗
A Dense Reward View on Aligning Text-to-Image Diffusion with Preference
Shentao Yang, Tianqi Chen, Mingyuan Zhou
0
0
Aligning text-to-image diffusion model (T2I) with preference has been gaining increasing research attention. While prior works exist on directly optimizing T2I by preference data, these methods are developed under the bandit assumption of a latent reward on the entire diffusion reverse chain, while ignoring the sequential nature of the generation process. This may harm the efficacy and efficiency of preference alignment. In this paper, we take on a finer dense reward perspective and derive a tractable alignment objective that emphasizes the initial steps of the T2I reverse chain. In particular, we introduce temporal discounting into DPO-style explicit-reward-free objectives, to break the temporal symmetry therein and suit the T2I generation hierarchy. In experiments on single and multiple prompt generation, our method is competitive with strong relevant baselines, both quantitatively and qualitatively. Further investigations are conducted to illustrate the insight of our approach.
5/14/2024

Robust Preference Optimization through Reward Model Distillation
Adam Fisch, Jacob Eisenstein, Vicky Zayats, Alekh Agarwal, Ahmad Beirami, Chirag Nagpal, Pete Shaw, Jonathan Berant
0
0
Language model (LM) post-training (or alignment) involves maximizing a reward function that is derived from preference annotations. Direct Preference Optimization (DPO) is a popular offline alignment method that trains a policy directly on preference data without the need to train a reward model or apply reinforcement learning. However, typical preference datasets have only a single, or at most a few, annotation per preference pair, which causes DPO to overconfidently assign rewards that trend towards infinite magnitude. This frequently leads to degenerate policies, sometimes causing even the probabilities of the preferred generations to go to zero. In this work, we analyze this phenomenon and propose distillation to get a better proxy for the true preference distribution over generation pairs: we train the LM to produce probabilities that match the distribution induced by a reward model trained on the preference data. Moreover, to account for uncertainty in the reward model we are distilling from, we optimize against a family of reward models that, as a whole, is likely to include at least one reasonable proxy for the preference distribution. Our results show that distilling from such a family of reward models leads to improved robustness to distribution shift in preference annotations, while preserving the simple supervised nature of DPO.
5/30/2024

Diffusion-RPO: Aligning Diffusion Models through Relative Preference Optimization
Yi Gu, Zhendong Wang, Yueqin Yin, Yujia Xie, Mingyuan Zhou
0
0
Aligning large language models with human preferences has emerged as a critical focus in language modeling research. Yet, integrating preference learning into Text-to-Image (T2I) generative models is still relatively uncharted territory. The Diffusion-DPO technique made initial strides by employing pairwise preference learning in diffusion models tailored for specific text prompts. We introduce Diffusion-RPO, a new method designed to align diffusion-based T2I models with human preferences more effectively. This approach leverages both prompt-image pairs with identical prompts and those with semantically related content across various modalities. Furthermore, we have developed a new evaluation metric, style alignment, aimed at overcoming the challenges of high costs, low reproducibility, and limited interpretability prevalent in current evaluations of human preference alignment. Our findings demonstrate that Diffusion-RPO outperforms established methods such as Supervised Fine-Tuning and Diffusion-DPO in tuning Stable Diffusion versions 1.5 and XL-1.0, achieving superior results in both automated evaluations of human preferences and style alignment. Our code is available at https://github.com/yigu1008/Diffusion-RPO
6/11/2024