Bridging Model-Based Optimization and Generative Modeling via Conservative Fine-Tuning of Diffusion Models
2405.19673
0
0
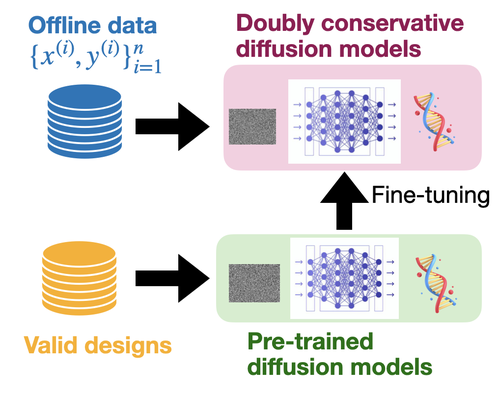
Abstract
AI-driven design problems, such as DNA/protein sequence design, are commonly tackled from two angles: generative modeling, which efficiently captures the feasible design space (e.g., natural images or biological sequences), and model-based optimization, which utilizes reward models for extrapolation. To combine the strengths of both approaches, we adopt a hybrid method that fine-tunes cutting-edge diffusion models by optimizing reward models through RL. Although prior work has explored similar avenues, they primarily focus on scenarios where accurate reward models are accessible. In contrast, we concentrate on an offline setting where a reward model is unknown, and we must learn from static offline datasets, a common scenario in scientific domains. In offline scenarios, existing approaches tend to suffer from overoptimization, as they may be misled by the reward model in out-of-distribution regions. To address this, we introduce a conservative fine-tuning approach, BRAID, by optimizing a conservative reward model, which includes additional penalization outside of offline data distributions. Through empirical and theoretical analysis, we demonstrate the capability of our approach to outperform the best designs in offline data, leveraging the extrapolation capabilities of reward models while avoiding the generation of invalid designs through pre-trained diffusion models.
Create account to get full access
Overview
- This paper explores a novel approach called "conservative fine-tuning" to bridge the gap between model-based optimization and generative modeling using diffusion models.
- The authors demonstrate how this technique can be used to enhance the performance of diffusion models on various tasks, including image generation, image-to-image translation, and out-of-distribution data generation.
- The proposed method aims to preserve the strong generalization capabilities of pre-trained diffusion models while enabling them to better adapt to specific tasks or datasets.
Plain English Explanation
Diffusion models are a type of powerful machine learning model that can generate high-quality images and other types of data. However, these models can be challenging to fine-tune or optimize for specific tasks, as they are often trained on a wide range of data and may not perform as well on more specialized datasets or applications.
The researchers in this paper have developed a new technique called "conservative fine-tuning" that helps bridge the gap between model-based optimization and generative modeling using diffusion models. The key idea is to fine-tune the diffusion model in a way that preserves its strong generalization capabilities while also enabling it to better adapt to the specific task or dataset at hand.
For example, imagine you have a pre-trained diffusion model that can generate high-quality images of landscapes. You might want to use this model to generate images of a specific type of building, like a skyscraper. The conservative fine-tuning approach allows you to fine-tune the model on a dataset of skyscraper images without significantly degrading its ability to generate other types of landscapes.
By using this technique, the authors demonstrate that diffusion models can be made more versatile and effective at a variety of tasks, including image generation, image-to-image translation, and generating data that is outside the distribution of the original training data. This could have important applications in areas like content creation, data augmentation, and scientific modeling.
Technical Explanation
The key innovation of this paper is the "conservative fine-tuning" approach, which the authors use to fine-tune pre-trained diffusion models for specific tasks or datasets. Traditional fine-tuning methods can often lead to significant degradation in the model's generalization capabilities, as the fine-tuning process can overfit the model to the new task or dataset.
To address this, the authors propose a conservative fine-tuning strategy that aims to preserve the strong generalization properties of the pre-trained diffusion model while still enabling it to adapt to the new task or dataset. The core idea is to constrain the fine-tuning process to only make small, conservative updates to the model parameters, rather than allowing for large, unconstrained changes.
Specifically, the authors introduce a "conservative loss" function that encourages the fine-tuned model to remain close to the pre-trained model in terms of its parameter values and output distributions. This is achieved by adding a penalty term to the standard fine-tuning loss that measures the distance between the fine-tuned model and the pre-trained model.
The authors demonstrate the effectiveness of their conservative fine-tuning approach on a range of tasks, including image generation, image-to-image translation, and out-of-distribution data generation. They show that their method can significantly outperform traditional fine-tuning techniques, as well as other state-of-the-art methods for adapting diffusion models to specific tasks.
Critical Analysis
One potential limitation of the conservative fine-tuning approach is that it may not be as effective for tasks that require more substantial changes to the model's architecture or behavior. The authors acknowledge this in the paper, noting that the conservative fine-tuning strategy is most suitable for tasks that require only modest adaptations to the pre-trained model.
Additionally, the authors do not provide a detailed analysis of the computational and memory overhead associated with their approach. Fine-tuning diffusion models can be computationally intensive, and the additional constraints and penalty terms introduced by the conservative fine-tuning method may further increase the computational burden.
Another area for potential further research is the extent to which the conservative fine-tuning approach can be generalized to other types of generative models, such as generative adversarial networks (GANs) or variational autoencoders (VAEs). The authors primarily focus on diffusion models in this work, but it would be interesting to see if the core principles of their approach could be applied to a broader class of generative modeling techniques.
Conclusion
Overall, this paper presents a promising new approach for fine-tuning pre-trained diffusion models to enhance their performance on specific tasks or datasets. By incorporating a "conservative" fine-tuning strategy, the authors demonstrate that it is possible to preserve the strong generalization capabilities of diffusion models while still enabling them to adapt to more specialized applications.
This work has important implications for the field of generative modeling, as it suggests a path forward for making these powerful models more versatile and accessible for a wide range of real-world applications, from content creation to scientific modeling and beyond. As the authors note, further research is needed to fully understand the limitations and potential of their approach, but this paper represents an important step forward in bridging the gap between model-based optimization and generative modeling.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
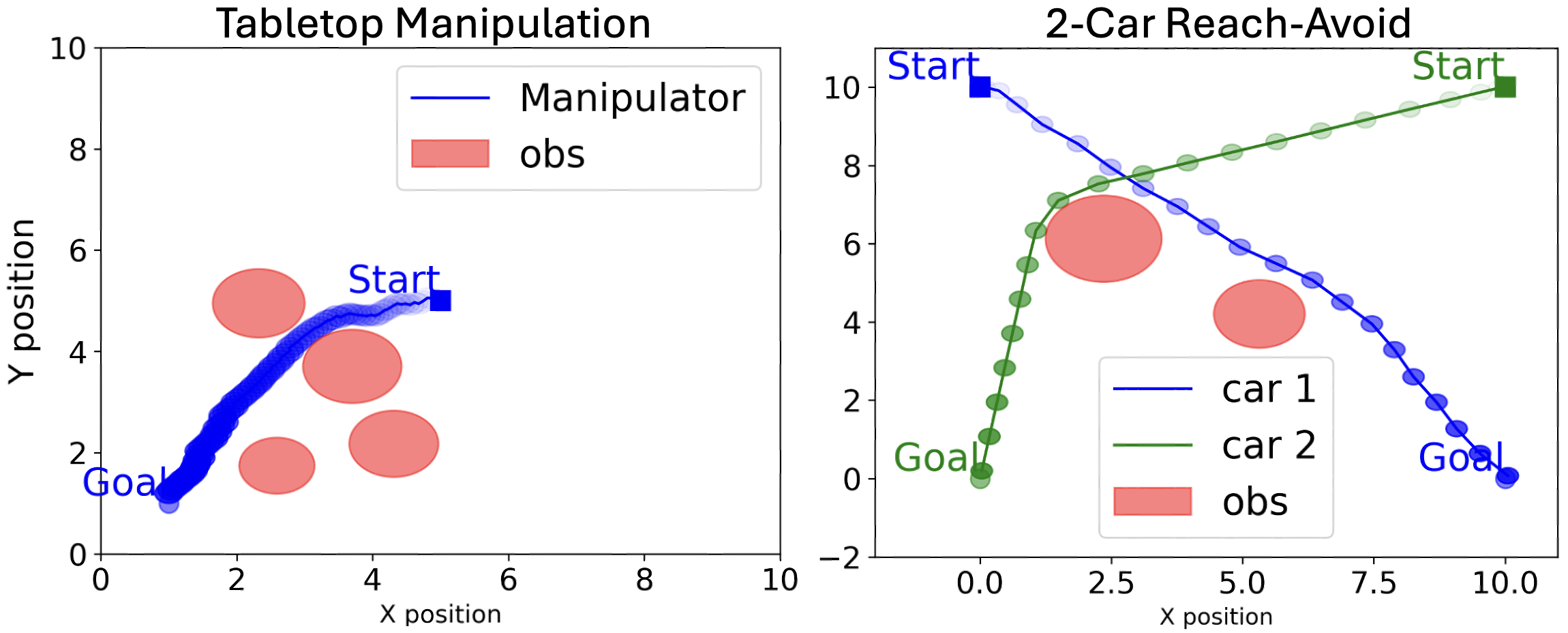
Constraint-Aware Diffusion Models for Trajectory Optimization
Anjian Li, Zihan Ding, Adji Bousso Dieng, Ryne Beeson
0
0
The diffusion model has shown success in generating high-quality and diverse solutions to trajectory optimization problems. However, diffusion models with neural networks inevitably make prediction errors, which leads to constraint violations such as unmet goals or collisions. This paper presents a novel constraint-aware diffusion model for trajectory optimization. We introduce a novel hybrid loss function for training that minimizes the constraint violation of diffusion samples compared to the groundtruth while recovering the original data distribution. Our model is demonstrated on tabletop manipulation and two-car reach-avoid problems, outperforming traditional diffusion models in minimizing constraint violations while generating samples close to locally optimal solutions.
6/4/2024
📊
Directly Fine-Tuning Diffusion Models on Differentiable Rewards
Kevin Clark, Paul Vicol, Kevin Swersky, David J Fleet
0
0
We present Direct Reward Fine-Tuning (DRaFT), a simple and effective method for fine-tuning diffusion models to maximize differentiable reward functions, such as scores from human preference models. We first show that it is possible to backpropagate the reward function gradient through the full sampling procedure, and that doing so achieves strong performance on a variety of rewards, outperforming reinforcement learning-based approaches. We then propose more efficient variants of DRaFT: DRaFT-K, which truncates backpropagation to only the last K steps of sampling, and DRaFT-LV, which obtains lower-variance gradient estimates for the case when K=1. We show that our methods work well for a variety of reward functions and can be used to substantially improve the aesthetic quality of images generated by Stable Diffusion 1.4. Finally, we draw connections between our approach and prior work, providing a unifying perspective on the design space of gradient-based fine-tuning algorithms.
6/24/2024
🐍
Confronting Reward Overoptimization for Diffusion Models: A Perspective of Inductive and Primacy Biases
Ziyi Zhang, Sen Zhang, Yibing Zhan, Yong Luo, Yonggang Wen, Dacheng Tao
0
0
Bridging the gap between diffusion models and human preferences is crucial for their integration into practical generative workflows. While optimizing downstream reward models has emerged as a promising alignment strategy, concerns arise regarding the risk of excessive optimization with learned reward models, which potentially compromises ground-truth performance. In this work, we confront the reward overoptimization problem in diffusion model alignment through the lenses of both inductive and primacy biases. We first identify a mismatch between current methods and the temporal inductive bias inherent in the multi-step denoising process of diffusion models, as a potential source of reward overoptimization. Then, we surprisingly discover that dormant neurons in our critic model act as a regularization against reward overoptimization while active neurons reflect primacy bias. Motivated by these observations, we propose Temporal Diffusion Policy Optimization with critic active neuron Reset (TDPO-R), a policy gradient algorithm that exploits the temporal inductive bias of diffusion models and mitigates the primacy bias stemming from active neurons. Empirical results demonstrate the superior efficacy of our methods in mitigating reward overoptimization. Code is avaliable at https://github.com/ZiyiZhang27/tdpo.
6/6/2024
✅
Physics-Informed Diffusion Models
Jan-Hendrik Bastek, WaiChing Sun, Dennis M. Kochmann
0
0
Generative models such as denoising diffusion models are quickly advancing their ability to approximate highly complex data distributions. They are also increasingly leveraged in scientific machine learning, where samples from the implied data distribution are expected to adhere to specific governing equations. We present a framework to inform denoising diffusion models of underlying constraints on such generated samples during model training. Our approach improves the alignment of the generated samples with the imposed constraints and significantly outperforms existing methods without affecting inference speed. Additionally, our findings suggest that incorporating such constraints during training provides a natural regularization against overfitting. Our framework is easy to implement and versatile in its applicability for imposing equality and inequality constraints as well as auxiliary optimization objectives.
5/24/2024