Connecting the Dots: Evaluating Abstract Reasoning Capabilities of LLMs Using the New York Times Connections Word Game
2406.11012
2
0

Abstract
The New York Times Connections game has emerged as a popular and challenging pursuit for word puzzle enthusiasts. We collect 200 Connections games to evaluate the performance of state-of-the-art large language models (LLMs) against expert and novice human players. Our results show that even the best-performing LLM, GPT-4o, which has otherwise shown impressive reasoning abilities on a wide variety of benchmarks, can only fully solve 8% of the games. Compared to GPT-4o, novice and expert players perform better, with expert human players significantly outperforming GPT-4o. To deepen our understanding we create a taxonomy of the knowledge types required to successfully categorize words in the Connections game, revealing that LLMs struggle with associative, encyclopedic, and linguistic knowledge. Our findings establish the New York Times Connections game as a challenging benchmark for evaluating abstract reasoning capabilities in humans and AI systems.
Create account to get full access
Overview
- This paper evaluates the abstract reasoning capabilities of large language models (LLMs) using the New York Times Connections word game.
- The researchers designed an experiment to test LLMs' ability to solve lateral thinking puzzles, which require making unexpected connections between seemingly unrelated concepts.
- The results provide insights into the strengths and limitations of current LLM architectures in tasks that involve flexible and creative reasoning.
Plain English Explanation
The paper examines how well large language models, which are advanced AI systems trained on vast amounts of text data, can solve a specific type of puzzle called the "New York Times Connections" game. This game requires players to find hidden connections between seemingly unrelated words or concepts, a skill known as "lateral thinking."
The researchers wanted to see how capable these powerful language models are at this kind of abstract reasoning and problem-solving. They designed an experiment to test the models' performance on Connections puzzles and analyzed the results to better understand the models' strengths and weaknesses.
The findings offer insights into the current state of language model technology and its potential for tasks that require flexible, creative thinking beyond just understanding and generating natural language. This could have important implications for the development of more capable and versatile AI systems in the future.
Technical Explanation
The paper presents an experimental evaluation of the abstract reasoning capabilities of large language models (LLMs) using the New York Times Connections word game. Connections puzzles require making unexpected conceptual leaps to find hidden links between seemingly unrelated words or concepts, a skill known as "lateral thinking."
The researchers designed an experiment to test the performance of several prominent LLM architectures, including GPT-3, BERT, and T5, on a set of Connections puzzles. The models were given the starting and ending words of each puzzle and asked to generate the sequence of intermediate words that form the connection.
The results provide insights into the strengths and limitations of current LLM models in tasks that involve flexible and creative reasoning, as opposed to more straightforward language understanding and generation. The models performed reasonably well on simpler puzzles but struggled with more complex ones that required more abstract and lateral thinking.
The paper discusses potential reasons for these performance differences, such as the models' reliance on statistical patterns in the training data versus deeper conceptual understanding. The findings also suggest avenues for future research to develop more capable reasoning abilities in LLMs, potentially through architectures that better capture relational and causal knowledge.
Critical Analysis
The paper provides a valuable contribution to the ongoing research on evaluating the reasoning capabilities of large language models beyond traditional language tasks. The use of the Connections word game as a benchmark is an interesting and relevant approach, as it challenges the models' ability to make unexpected conceptual leaps, which is an important aspect of human-level intelligence.
However, the paper does acknowledge some limitations in the experimental design and the interpretation of the results. For example, the researchers note that the performance of the models may be influenced by the specific set of puzzles used, and that further testing with a larger and more diverse set of puzzles would be beneficial.
Additionally, the paper does not fully explore the potential reasons behind the performance differences observed between the models, and more in-depth analysis of the models' internal representations and reasoning processes could provide further insights.
Future research could also explore the application of these findings to other types of reasoning tasks, such as puzzle solving using reasoning, strategic reasoning, or logical reasoning, to gain a more comprehensive understanding of the abstract reasoning capabilities of LLMs.
Conclusion
The paper presents an innovative evaluation of the abstract reasoning capabilities of large language models using the New York Times Connections word game. The findings demonstrate that while LLMs can perform reasonably well on some lateral thinking puzzles, they still struggle with more complex tasks that require flexible, creative reasoning.
These insights have important implications for the development of more capable and versatile AI systems that can engage in human-like problem-solving and decision-making. The research also highlights the need for continued advancements in areas such as reasoning and knowledge representation to push the boundaries of what current language models can achieve.
Overall, the paper contributes to the ongoing effort to better understand the strengths and limitations of large language models, and it serves as a valuable resource for researchers and developers working to create more intelligent and capable AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Missed Connections: Lateral Thinking Puzzles for Large Language Models
Graham Todd, Tim Merino, Sam Earle, Julian Togelius
0
0
The Connections puzzle published each day by the New York Times tasks players with dividing a bank of sixteen words into four groups of four words that each relate to a common theme. Solving the puzzle requires both common linguistic knowledge (i.e. definitions and typical usage) as well as, in many cases, lateral or abstract thinking. This is because the four categories ascend in complexity, with the most challenging category often requiring thinking about words in uncommon ways or as parts of larger phrases. We investigate the capacity for automated AI systems to play Connections and explore the game's potential as an automated benchmark for abstract reasoning and a way to measure the semantic information encoded by data-driven linguistic systems. In particular, we study both a sentence-embedding baseline and modern large language models (LLMs). We report their accuracy on the task, measure the impacts of chain-of-thought prompting, and discuss their failure modes. Overall, we find that the Connections task is challenging yet feasible, and a strong test-bed for future work.
4/23/2024
💬
Puzzle Solving using Reasoning of Large Language Models: A Survey
Panagiotis Giadikiaroglou, Maria Lymperaiou, Giorgos Filandrianos, Giorgos Stamou
0
0
Exploring the capabilities of Large Language Models (LLMs) in puzzle solving unveils critical insights into their potential and challenges in AI, marking a significant step towards understanding their applicability in complex reasoning tasks. This survey leverages a unique taxonomy -- dividing puzzles into rule-based and rule-less categories -- to critically assess LLMs through various methodologies, including prompting techniques, neuro-symbolic approaches, and fine-tuning. Through a critical review of relevant datasets and benchmarks, we assess LLMs' performance, identifying significant challenges in complex puzzle scenarios. Our findings highlight the disparity between LLM capabilities and human-like reasoning, particularly in those requiring advanced logical inference. The survey underscores the necessity for novel strategies and richer datasets to advance LLMs' puzzle-solving proficiency and contribute to AI's logical reasoning and creative problem-solving advancements.
4/23/2024

GameBench: Evaluating Strategic Reasoning Abilities of LLM Agents
Anthony Costarelli, Mat Allen, Roman Hauksson, Grace Sodunke, Suhas Hariharan, Carlson Cheng, Wenjie Li, Arjun Yadav
0
0
Large language models have demonstrated remarkable few-shot performance on many natural language understanding tasks. Despite several demonstrations of using large language models in complex, strategic scenarios, there lacks a comprehensive framework for evaluating agents' performance across various types of reasoning found in games. To address this gap, we introduce GameBench, a cross-domain benchmark for evaluating strategic reasoning abilities of LLM agents. We focus on 9 different game environments, where each covers at least one axis of key reasoning skill identified in strategy games, and select games for which strategy explanations are unlikely to form a significant portion of models' pretraining corpuses. Our evaluations use GPT-3 and GPT-4 in their base form along with two scaffolding frameworks designed to enhance strategic reasoning ability: Chain-of-Thought (CoT) prompting and Reasoning Via Planning (RAP). Our results show that none of the tested models match human performance, and at worse GPT-4 performs worse than random action. CoT and RAP both improve scores but not comparable to human levels.
6/12/2024
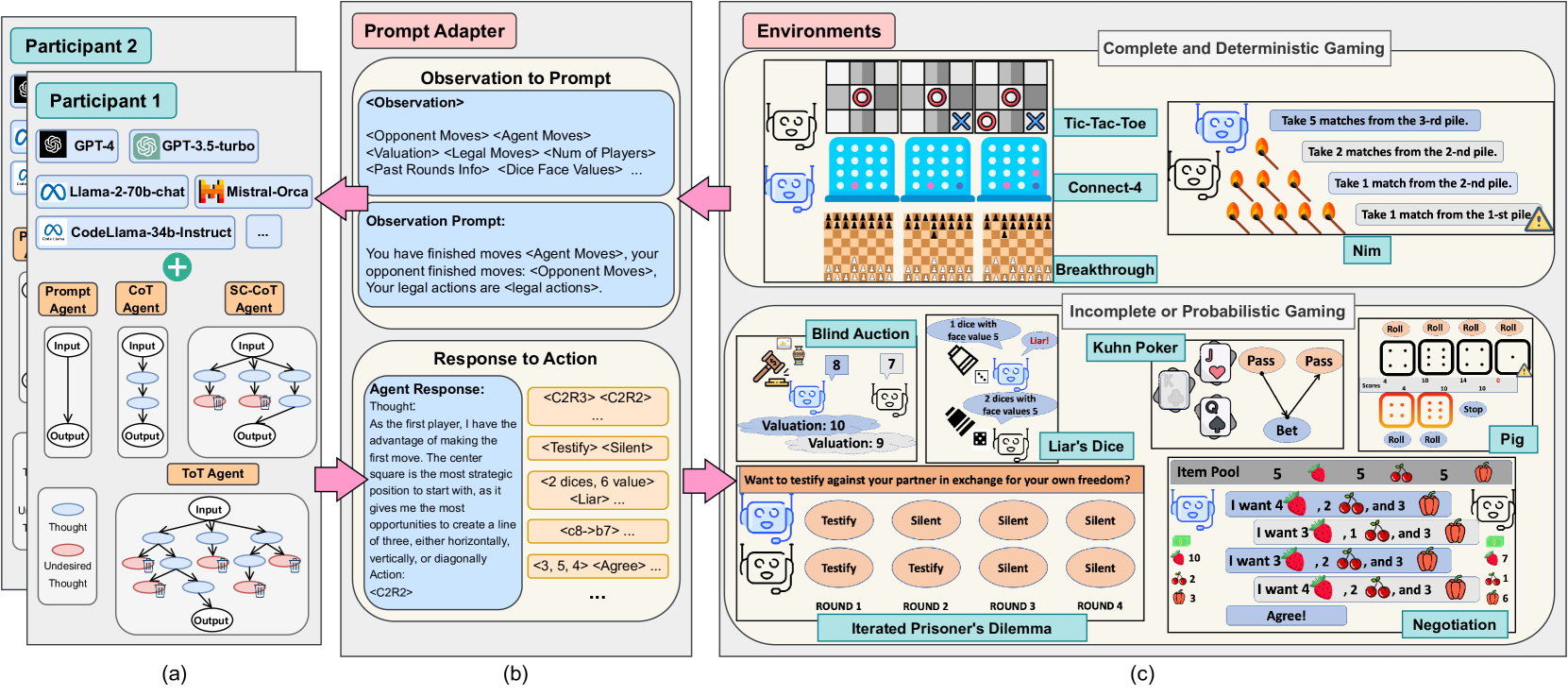
GTBench: Uncovering the Strategic Reasoning Limitations of LLMs via Game-Theoretic Evaluations
Jinhao Duan, Renming Zhang, James Diffenderfer, Bhavya Kailkhura, Lichao Sun, Elias Stengel-Eskin, Mohit Bansal, Tianlong Chen, Kaidi Xu
0
0
As Large Language Models (LLMs) are integrated into critical real-world applications, their strategic and logical reasoning abilities are increasingly crucial. This paper evaluates LLMs' reasoning abilities in competitive environments through game-theoretic tasks, e.g., board and card games that require pure logic and strategic reasoning to compete with opponents. We first propose GTBench, a language-driven environment composing 10 widely recognized tasks, across a comprehensive game taxonomy: complete versus incomplete information, dynamic versus static, and probabilistic versus deterministic scenarios. Then, we (1) Characterize the game-theoretic reasoning of LLMs; and (2) Perform LLM-vs.-LLM competitions as reasoning evaluation. We observe that (1) LLMs have distinct behaviors regarding various gaming scenarios; for example, LLMs fail in complete and deterministic games yet they are competitive in probabilistic gaming scenarios; (2) Most open-source LLMs, e.g., CodeLlama-34b-Instruct and Llama-2-70b-chat, are less competitive than commercial LLMs, e.g., GPT-4, in complex games, yet the recently released Llama-3-70b-Instruct makes up for this shortcoming. In addition, code-pretraining greatly benefits strategic reasoning, while advanced reasoning methods such as Chain-of-Thought (CoT) and Tree-of-Thought (ToT) do not always help. We further characterize the game-theoretic properties of LLMs, such as equilibrium and Pareto Efficiency in repeated games. Detailed error profiles are provided for a better understanding of LLMs' behavior. We hope our research provides standardized protocols and serves as a foundation to spur further explorations in the strategic reasoning of LLMs.
6/11/2024