GameBench: Evaluating Strategic Reasoning Abilities of LLM Agents
2406.06613
0
0

Abstract
Large language models have demonstrated remarkable few-shot performance on many natural language understanding tasks. Despite several demonstrations of using large language models in complex, strategic scenarios, there lacks a comprehensive framework for evaluating agents' performance across various types of reasoning found in games. To address this gap, we introduce GameBench, a cross-domain benchmark for evaluating strategic reasoning abilities of LLM agents. We focus on 9 different game environments, where each covers at least one axis of key reasoning skill identified in strategy games, and select games for which strategy explanations are unlikely to form a significant portion of models' pretraining corpuses. Our evaluations use GPT-3 and GPT-4 in their base form along with two scaffolding frameworks designed to enhance strategic reasoning ability: Chain-of-Thought (CoT) prompting and Reasoning Via Planning (RAP). Our results show that none of the tested models match human performance, and at worse GPT-4 performs worse than random action. CoT and RAP both improve scores but not comparable to human levels.
Create account to get full access
Overview
- This paper introduces a new game-based benchmark called GameBench to evaluate the strategic reasoning abilities of large language model (LLM) agents.
- The authors argue that existing benchmarks do not adequately assess the strategic decision-making capabilities of LLMs, which are crucial for real-world applications.
- GameBench presents a suite of strategy games that require agents to reason about long-term consequences and make trade-offs, aiming to uncover the limitations of current LLM reasoning abilities.
Plain English Explanation
The paper introduces a new way to test the strategic reasoning skills of AI language models. Current tests often focus on language understanding or basic problem-solving, but don't really assess the models' ability to think ahead and make complex decisions. The authors created a set of strategy games that require the AI to consider long-term consequences and weigh different options to achieve the best outcome. By having the AI play these games, the researchers can better understand the limits of its strategic decision-making capabilities, which is crucial for real-world applications where AI needs to make thoughtful, high-stakes choices. The goal is to uncover the strengths and weaknesses of today's language models when it comes to reasoning about complex scenarios and planning ahead.
Technical Explanation
The paper proposes a new benchmark called GameBench to evaluate the strategic reasoning abilities of large language model (LLM) agents. GameBench consists of a suite of strategy games that require agents to reason about long-term consequences and make trade-offs, in contrast to existing benchmarks that primarily assess language understanding or basic problem-solving skills.
The games in GameBench are designed to probe different aspects of strategic reasoning, such as planning, resource management, and adversarial thinking. For example, one game involves managing a colony's resources and making decisions that balance short-term gains with long-term sustainability. Another game pits two agents against each other in a competitive scenario that requires anticipating the opponent's moves.
The authors evaluate a range of LLM agents, including GPT-3 and GPT-4, on the GameBench tasks. The results reveal significant limitations in the agents' strategic reasoning abilities, as they often struggle to formulate coherent long-term plans or effectively navigate the trade-offs inherent in the games.
The paper also introduces a novel technique called "AlphaZero-style training" to fine-tune LLM agents on the GameBench tasks, which leads to improved performance but still falls short of human-level strategic reasoning.
Critical Analysis
The GameBench benchmark represents an important step forward in the evaluation of LLM reasoning abilities, as it goes beyond language understanding and basic problem-solving to assess more complex, strategic decision-making. The authors acknowledge that the games in GameBench may not fully capture all the nuances of real-world strategic reasoning, and they encourage further development and refinement of the benchmark.
One potential limitation of the current study is that it focuses primarily on evaluating LLM agents, which may not be representative of the full range of AI systems capable of strategic reasoning. Future research could explore the performance of other AI architectures, such as those based on reinforcement learning or hybrid approaches, on the GameBench tasks.
Additionally, the paper does not delve deeply into the specific cognitive processes or knowledge representations that underlie the LLMs' successes and failures in the GameBench games. A more detailed analysis of the models' decision-making strategies and the factors that influence their performance could provide valuable insights for improving strategic reasoning capabilities.
Conclusion
The GameBench benchmark represents a significant advancement in the evaluation of large language model (LLM) agents' strategic reasoning abilities. By presenting a suite of strategy games that require long-term planning and trade-off considerations, the authors have uncovered fundamental limitations in the current generation of LLMs. This research highlights the need for continued progress in developing AI systems with more robust and flexible reasoning capabilities, which will be crucial for real-world applications that demand thoughtful, high-stakes decision-making. The GameBench framework provides a valuable tool for researchers and developers to assess and improve the strategic reasoning of AI agents.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
GTBench: Uncovering the Strategic Reasoning Limitations of LLMs via Game-Theoretic Evaluations
Jinhao Duan, Renming Zhang, James Diffenderfer, Bhavya Kailkhura, Lichao Sun, Elias Stengel-Eskin, Mohit Bansal, Tianlong Chen, Kaidi Xu
0
0
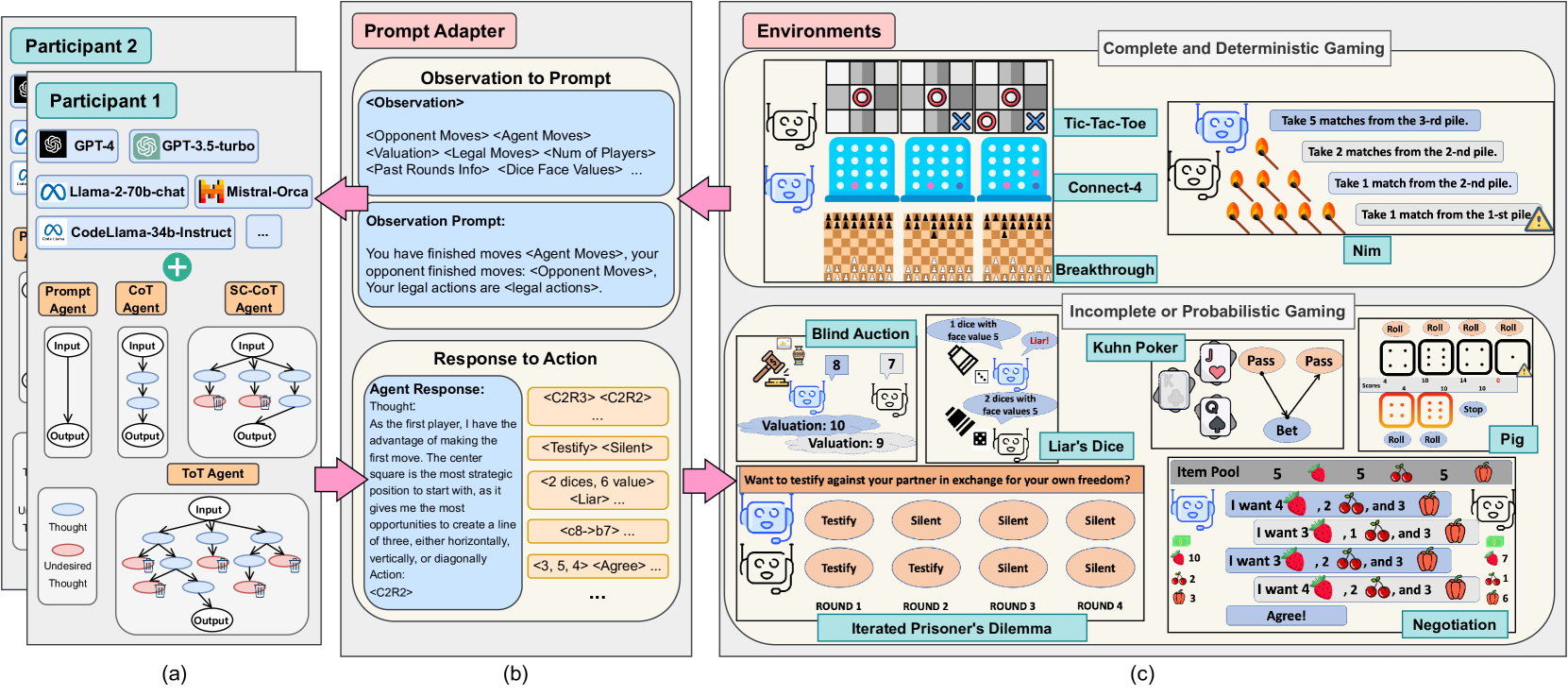
As Large Language Models (LLMs) are integrated into critical real-world applications, their strategic and logical reasoning abilities are increasingly crucial. This paper evaluates LLMs' reasoning abilities in competitive environments through game-theoretic tasks, e.g., board and card games that require pure logic and strategic reasoning to compete with opponents. We first propose GTBench, a language-driven environment composing 10 widely recognized tasks, across a comprehensive game taxonomy: complete versus incomplete information, dynamic versus static, and probabilistic versus deterministic scenarios. Then, we (1) Characterize the game-theoretic reasoning of LLMs; and (2) Perform LLM-vs.-LLM competitions as reasoning evaluation. We observe that (1) LLMs have distinct behaviors regarding various gaming scenarios; for example, LLMs fail in complete and deterministic games yet they are competitive in probabilistic gaming scenarios; (2) Most open-source LLMs, e.g., CodeLlama-34b-Instruct and Llama-2-70b-chat, are less competitive than commercial LLMs, e.g., GPT-4, in complex games, yet the recently released Llama-3-70b-Instruct makes up for this shortcoming. In addition, code-pretraining greatly benefits strategic reasoning, while advanced reasoning methods such as Chain-of-Thought (CoT) and Tree-of-Thought (ToT) do not always help. We further characterize the game-theoretic properties of LLMs, such as equilibrium and Pareto Efficiency in repeated games. Detailed error profiles are provided for a better understanding of LLMs' behavior. We hope our research provides standardized protocols and serves as a foundation to spur further explorations in the strategic reasoning of LLMs.
6/11/2024
LogicBench: Towards Systematic Evaluation of Logical Reasoning Ability of Large Language Models
Mihir Parmar, Nisarg Patel, Neeraj Varshney, Mutsumi Nakamura, Man Luo, Santosh Mashetty, Arindam Mitra, Chitta Baral
0
0
Recently developed large language models (LLMs) have been shown to perform remarkably well on a wide range of language understanding tasks. But, can they really reason over the natural language? This question has been receiving significant research attention and many reasoning skills such as commonsense, numerical, and qualitative have been studied. However, the crucial skill pertaining to 'logical reasoning' has remained underexplored. Existing work investigating this reasoning ability of LLMs has focused only on a couple of inference rules (such as modus ponens and modus tollens) of propositional and first-order logic. Addressing the above limitation, we comprehensively evaluate the logical reasoning ability of LLMs on 25 different reasoning patterns spanning over propositional, first-order, and non-monotonic logics. To enable systematic evaluation, we introduce LogicBench, a natural language question-answering dataset focusing on the use of a single inference rule. We conduct detailed analysis with a range of LLMs such as GPT-4, ChatGPT, Gemini, Llama-2, and Mistral using chain-of-thought prompting. Experimental results show that existing LLMs do not fare well on LogicBench; especially, they struggle with instances involving complex reasoning and negations. Furthermore, they sometimes overlook contextual information necessary for reasoning to arrive at the correct conclusion. We believe that our work and findings facilitate future research for evaluating and enhancing the logical reasoning ability of LLMs. Data and code are available at https://github.com/Mihir3009/LogicBench.
6/7/2024
How Far Are We on the Decision-Making of LLMs? Evaluating LLMs' Gaming Ability in Multi-Agent Environments
Jen-tse Huang, Eric John Li, Man Ho Lam, Tian Liang, Wenxuan Wang, Youliang Yuan, Wenxiang Jiao, Xing Wang, Zhaopeng Tu, Michael R. Lyu
0
0
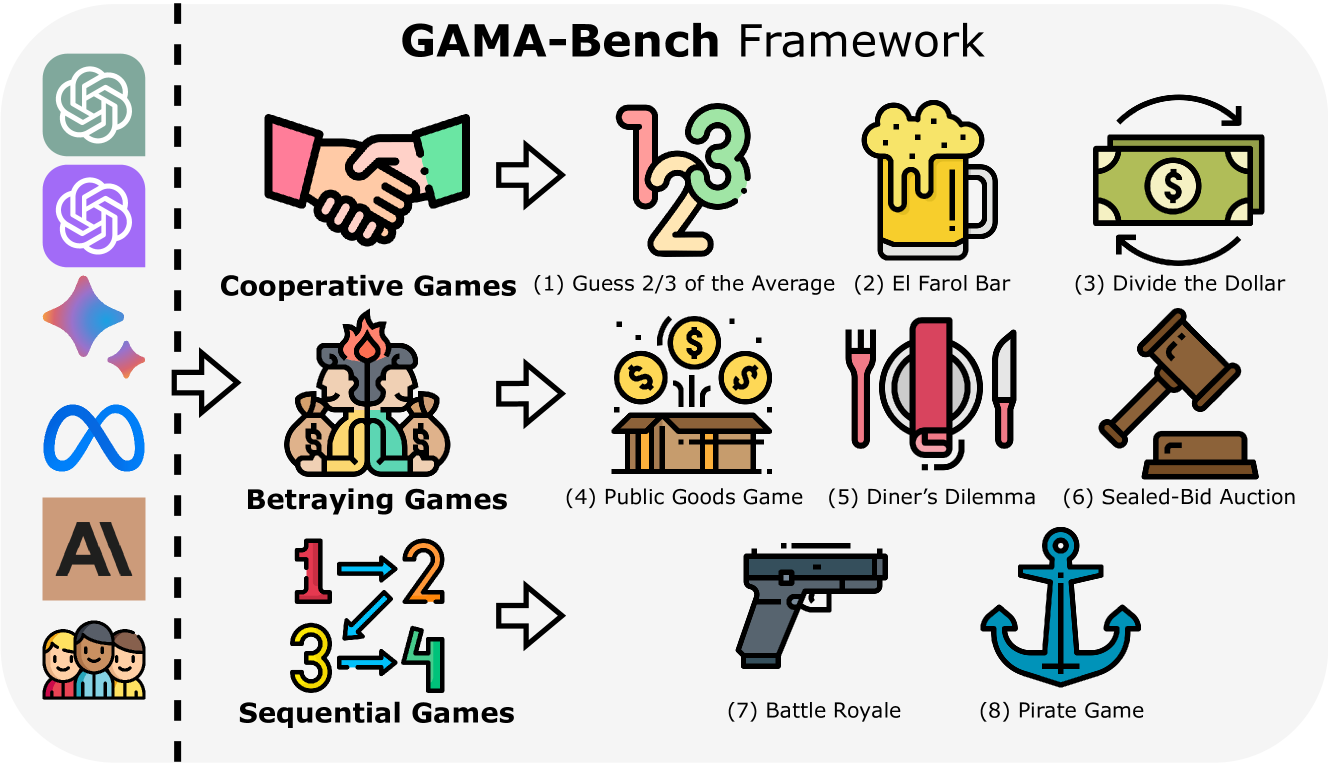
Decision-making, a complicated task requiring various types of abilities, presents an excellent framework for assessing Large Language Models (LLMs). Our research investigates LLMs' decision-making capabilities through the lens of a well-established field, Game Theory. We focus specifically on games that support the participation of more than two agents simultaneously. Subsequently, we introduce our framework, GAMA-Bench, including eight classical multi-agent games. We design a scoring scheme to assess a model's performance in these games quantitatively. Through GAMA-Bench, we investigate LLMs' robustness, generalizability, and enhancement strategies. Results reveal that while GPT-3.5 shows satisfying robustness, its generalizability is relatively limited. However, its performance can be improved through approaches such as Chain-of-Thought. Additionally, we conduct evaluations across various LLMs and find that GPT-4 outperforms other models on GAMA-Bench, achieving a score of 60.5. Moreover, Gemini-1.0-Pro and GPT-3.5 (0613, 1106, 0125) demonstrate similar intelligence on GAMA-Bench. The code and experimental results are made publicly available via https://github.com/CUHK-ARISE/GAMABench.
4/26/2024
Can only LLMs do Reasoning?: Potential of Small Language Models in Task Planning
Gawon Choi, Hyemin Ahn
0
0
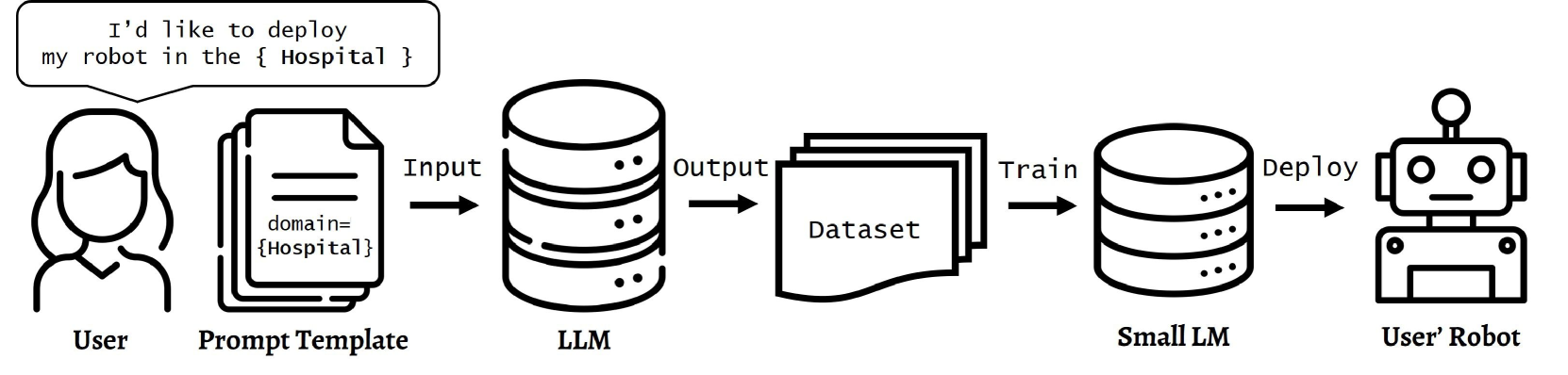
In robotics, the use of Large Language Models (LLMs) is becoming prevalent, especially for understanding human commands. In particular, LLMs are utilized as domain-agnostic task planners for high-level human commands. LLMs are capable of Chain-of-Thought (CoT) reasoning, and this allows LLMs to be task planners. However, we need to consider that modern robots still struggle to perform complex actions, and the domains where robots can be deployed are limited in practice. This leads us to pose a question: If small LMs can be trained to reason in chains within a single domain, would even small LMs be good task planners for the robots? To train smaller LMs to reason in chains, we build `COmmand-STeps datasets' (COST) consisting of high-level commands along with corresponding actionable low-level steps, via LLMs. We release not only our datasets but also the prompt templates used to generate them, to allow anyone to build datasets for their domain. We compare GPT3.5 and GPT4 with the finetuned GPT2 for task domains, in tabletop and kitchen environments, and the result shows that GPT2-medium is comparable to GPT3.5 for task planning in a specific domain. Our dataset, code, and more output samples can be found in https://github.com/Gawon-Choi/small-LMs-Task-Planning
4/8/2024