Connecting the Dots in News Analysis: Bridging the Cross-Disciplinary Disparities in Media Bias and Framing
2309.08069
0
0
👨🏫
Abstract
The manifestation and effect of bias in news reporting have been central topics in the social sciences for decades, and have received increasing attention in the NLP community recently. While NLP can help to scale up analyses or contribute automatic procedures to investigate the impact of biased news in society, we argue that methodologies that are currently dominant fall short of addressing the complex questions and effects addressed in theoretical media studies. In this survey paper, we review social science approaches and draw a comparison with typical task formulations, methods, and evaluation metrics used in the analysis of media bias in NLP. We discuss open questions and suggest possible directions to close identified gaps between theory and predictive models, and their evaluation. These include model transparency, considering document-external information, and cross-document reasoning rather than single-label assignment.
Create account to get full access
Overview
- This paper examines the challenges of using natural language processing (NLP) to analyze media bias in news reporting.
- The authors argue that current NLP methods fall short of addressing the complex questions and effects addressed in theoretical media studies.
- The paper reviews social science approaches to studying media bias and compares them to typical NLP task formulations, methods, and evaluation metrics.
- The authors discuss open questions and suggest possible directions to bridge the gap between theory and predictive models, and their evaluation.
Plain English Explanation
The issue of bias in news reporting has been a topic of interest in the social sciences for a long time. Recently, the field of natural language processing (NLP) has also started to explore ways to analyze and understand media bias. While NLP can help scale up these analyses or provide automated tools to investigate the impact of biased news, the authors of this paper believe that the current NLP approaches are not fully addressing the complex questions and effects that have been studied in media studies theory.
The paper looks at how social scientists have approached the study of media bias and compares that to the typical ways NLP researchers have tried to tackle this problem. The authors suggest that there are gaps between the theoretical understanding of media bias and the predictive models and evaluation metrics used in NLP.
To bridge these gaps, the authors propose several directions for future research, such as: • Increasing the transparency of NLP models to better understand how they are making decisions about media bias. • Incorporating information beyond just the text of news articles, such as the broader context and connections between different news sources. • Moving beyond just labeling individual articles as biased or unbiased, and instead looking at how bias plays out across multiple news stories and documents.
By addressing these issues, the authors hope that NLP can become a more effective tool for studying and understanding the complex phenomenon of media bias.
Technical Explanation
The paper begins by reviewing the rich history of research on media bias in the social sciences, which has explored a variety of theoretical frameworks and empirical approaches to understand the manifestation and effects of bias in news reporting.
The authors then compare this to the typical task formulations, methods, and evaluation metrics used in NLP research on media bias analysis. Common NLP approaches often involve training machine learning models to classify news articles as biased or unbiased, based on the textual content alone. The authors argue that these methods fall short of fully capturing the nuanced, contextual, and cross-document nature of media bias as understood in media studies theory.
To address this gap, the authors propose several key directions for future NLP research on media bias:
-
Model Transparency: Developing more transparent NLP models that can explain their decision-making process, rather than treating them as black boxes.
-
Incorporating Document-External Information: Leveraging information beyond just the text of individual news articles, such as the source, author, publication date, and broader context.
-
Cross-Document Reasoning: Moving away from single-label assignments (biased vs. unbiased) and instead looking at how bias manifests across multiple related news stories and documents.
The authors also discuss the potential benefits of developing interactive frameworks that allow users to explore and understand media bias, rather than just relying on automated predictions.
Critical Analysis
The authors raise valid concerns about the limitations of current NLP approaches to media bias analysis. They rightly point out that the dominant task formulations and evaluation metrics used in NLP research may not fully capture the complex, contextual nature of bias as understood in media studies theory.
One key limitation highlighted is the tendency of NLP models to treat news articles in isolation, without considering the broader context and connections between different sources. This could lead to oversimplified or inaccurate assessments of media bias. The authors' suggestions to incorporate document-external information and enable cross-document reasoning are promising directions to address this issue.
The authors also emphasize the importance of model transparency, which is crucial for building trust and understanding in real-world applications of media bias analysis. Pitfalls of conversational LLMs for news debiasing also highlight the challenges of achieving transparency in complex NLP systems.
While the paper provides a thoughtful critique of current NLP approaches, it would have been beneficial to see the authors delve deeper into specific examples or case studies to illustrate the gaps they have identified. Additionally, a more comprehensive discussion of the trade-offs and challenges involved in implementing the proposed research directions could have strengthened the analysis.
Conclusion
This paper serves as an important call to action for the NLP community to better align its methods and evaluation with the rich theoretical understanding of media bias developed in the social sciences. By addressing the identified gaps, such as improving model transparency, incorporating contextual information, and enabling cross-document reasoning, NLP researchers can make significant strides towards developing more nuanced and impactful tools for analyzing and understanding the complex phenomenon of media bias.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

A Study on Scaling Up Multilingual News Framing Analysis
Syeda Sabrina Akter, Antonios Anastasopoulos
0
0
Media framing is the study of strategically selecting and presenting specific aspects of political issues to shape public opinion. Despite its relevance to almost all societies around the world, research has been limited due to the lack of available datasets and other resources. This study explores the possibility of dataset creation through crowdsourcing, utilizing non-expert annotators to develop training corpora. We first extend framing analysis beyond English news to a multilingual context (12 typologically diverse languages) through automatic translation. We also present a novel benchmark in Bengali and Portuguese on the immigration and same-sex marriage domains. Additionally, we show that a system trained on our crowd-sourced dataset, combined with other existing ones, leads to a 5.32 percentage point increase from the baseline, showing that crowdsourcing is a viable option. Last, we study the performance of large language models (LLMs) for this task, finding that task-specific fine-tuning is a better approach than employing bigger non-specialized models.
4/3/2024
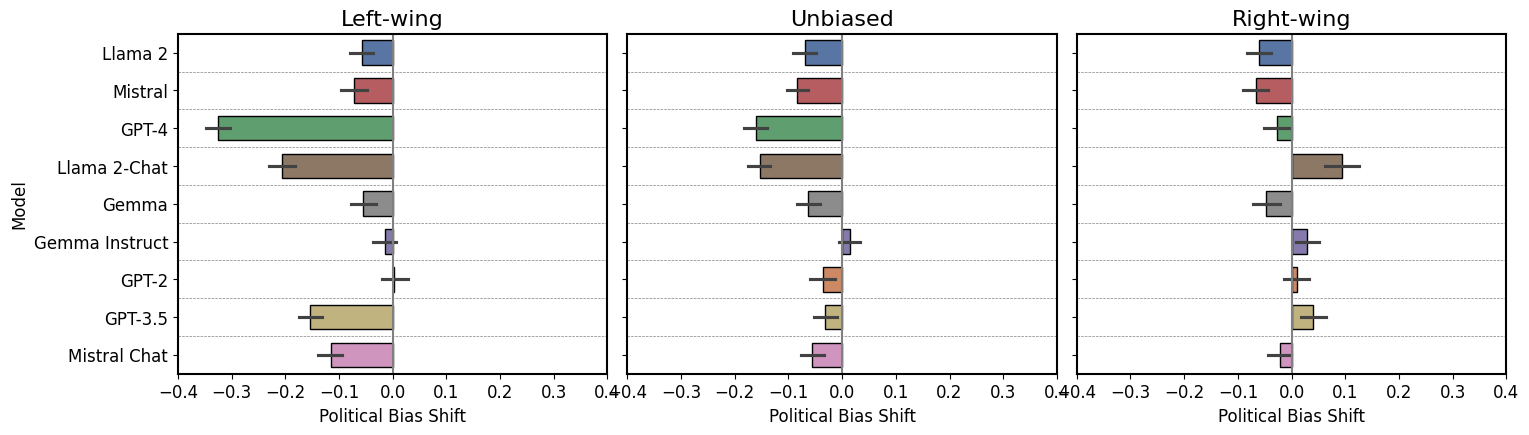
Quantifying Generative Media Bias with a Corpus of Real-world and Generated News Articles
Filip Trhlik, Pontus Stenetorp
0
0
Large language models (LLMs) are increasingly being utilised across a range of tasks and domains, with a burgeoning interest in their application within the field of journalism. This trend raises concerns due to our limited understanding of LLM behaviour in this domain, especially with respect to political bias. Existing studies predominantly focus on LLMs undertaking political questionnaires, which offers only limited insights into their biases and operational nuances. To address this gap, our study establishes a new curated dataset that contains 2,100 human-written articles and utilises their descriptions to generate 56,700 synthetic articles using nine LLMs. This enables us to analyse shifts in properties between human-authored and machine-generated articles, with this study focusing on political bias, detecting it using both supervised models and LLMs. Our findings reveal significant disparities between base and instruction-tuned LLMs, with instruction-tuned models exhibiting consistent political bias. Furthermore, we are able to study how LLMs behave as classifiers, observing their display of political bias even in this role. Overall, for the first time within the journalistic domain, this study outlines a framework and provides a structured dataset for quantifiable experiments, serving as a foundation for further research into LLM political bias and its implications.
6/18/2024
🔎
Experiments in News Bias Detection with Pre-Trained Neural Transformers
Tim Menzner, Jochen L. Leidner
0
0
The World Wide Web provides unrivalled access to information globally, including factual news reporting and commentary. However, state actors and commercial players increasingly spread biased (distorted) or fake (non-factual) information to promote their agendas. We compare several large, pre-trained language models on the task of sentence-level news bias detection and sub-type classification, providing quantitative and qualitative results.
6/17/2024
🏷️
An Interactive Framework for Profiling News Media Sources
Nikhil Mehta, Dan Goldwasser
0
0
The recent rise of social media has led to the spread of large amounts of fake and biased news, content published with the intent to sway beliefs. While detecting and profiling the sources that spread this news is important to maintain a healthy society, it is challenging for automated systems. In this paper, we propose an interactive framework for news media profiling. It combines the strengths of graph based news media profiling models, Pre-trained Large Language Models, and human insight to characterize the social context on social media. Experimental results show that with as little as 5 human interactions, our framework can rapidly detect fake and biased news media, even in the most challenging settings of emerging news events, where test data is unseen.
4/30/2024