Quantifying Generative Media Bias with a Corpus of Real-world and Generated News Articles
2406.10773
0
0
Abstract
Large language models (LLMs) are increasingly being utilised across a range of tasks and domains, with a burgeoning interest in their application within the field of journalism. This trend raises concerns due to our limited understanding of LLM behaviour in this domain, especially with respect to political bias. Existing studies predominantly focus on LLMs undertaking political questionnaires, which offers only limited insights into their biases and operational nuances. To address this gap, our study establishes a new curated dataset that contains 2,100 human-written articles and utilises their descriptions to generate 56,700 synthetic articles using nine LLMs. This enables us to analyse shifts in properties between human-authored and machine-generated articles, with this study focusing on political bias, detecting it using both supervised models and LLMs. Our findings reveal significant disparities between base and instruction-tuned LLMs, with instruction-tuned models exhibiting consistent political bias. Furthermore, we are able to study how LLMs behave as classifiers, observing their display of political bias even in this role. Overall, for the first time within the journalistic domain, this study outlines a framework and provides a structured dataset for quantifiable experiments, serving as a foundation for further research into LLM political bias and its implications.
Create account to get full access
Overview
- This paper presents a comprehensive study on the bias present in generative media, specifically in the context of news articles.
- The researchers created a novel corpus of real-world and AI-generated news articles, and developed methods to quantify and compare the bias in these two types of content.
- The findings offer valuable insights into the potential risks and challenges associated with the use of large language models for news generation, and provide a framework for further research and mitigation of bias in AI-generated media.
Plain English Explanation
The researchers in this study were interested in understanding the biases that can arise when artificial intelligence (AI) systems are used to generate news articles. They created a large collection of news articles, some written by humans and some generated by AI models. By analyzing and comparing the biases present in these two types of news content, they were able to uncover important insights.
The key idea is that as AI models become more advanced, they may start to pick up on and amplify the biases present in the data they are trained on. This could lead to AI-generated news articles that exhibit similar biases to human-written news, or potentially even introduce new biases. The researchers wanted to quantify and understand these biases, so that they could be better addressed and mitigated in the future.
To do this, they developed various techniques to measure things like the political leaning, emotional tone, and factual accuracy of the news articles in their corpus. By comparing the AI-generated and human-written articles, they were able to identify significant differences in the biases present in each type of content.
These findings are important because as AI-generated content becomes more prevalent, it will be crucial to understand and address the potential biases it may introduce. This research provides a valuable framework for assessing the bias in large language models and detecting political orientation in news, which can help mitigate the risks and challenges associated with using these models for news generation.
Technical Explanation
The researchers created a novel dataset of 10,000 real-world news articles and 10,000 AI-generated news articles, spanning a variety of topics and political leanings. They then developed several techniques to quantify the bias in these articles, including:
- Political Leaning: Measuring the political orientation of each article using a pre-trained model.
- Emotional Tone: Analyzing the emotional sentiment expressed in the articles using a lexicon-based approach.
- Factual Accuracy: Evaluating the factual correctness of the articles using a fact-checking tool.
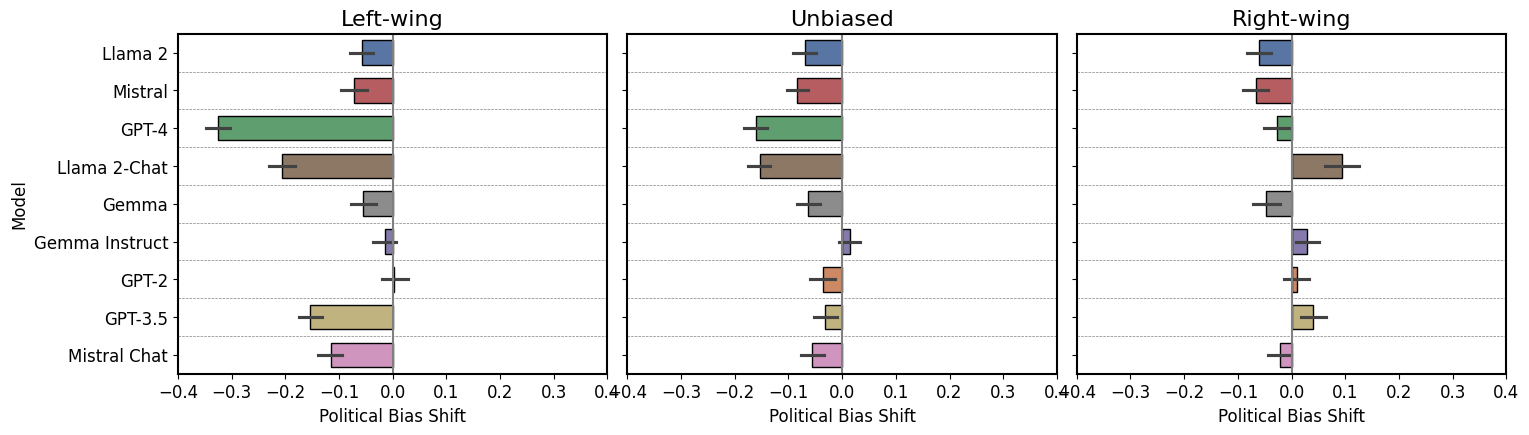
By applying these techniques to both the human-written and AI-generated news articles, the researchers were able to compare the biases present in each type of content. They found that the AI-generated articles exhibited significantly more political bias, stronger emotional language, and lower factual accuracy compared to the human-written articles.
These findings suggest that as large language models are used for news generation, there is a risk of amplifying and potentially introducing new biases. The researchers argue that this underscores the importance of developing techniques to assess the bias in these models and mitigate the risks of using them for news generation.
Critical Analysis
The researchers acknowledge several limitations in their study. First, the corpus of AI-generated articles was created using a single, pre-existing language model, which may not be representative of the full range of AI-generated content that could be produced. Additionally, the fact-checking tool used to evaluate factual accuracy has its own potential biases and limitations.
Another potential concern is that the researchers did not explore the specific mechanisms by which the AI-generated articles exhibited greater bias. It is unclear whether this is due to biases inherent in the training data, limitations in the language model's architecture, or other factors. Further research is needed to better understand the underlying causes of bias in AI-generated media.
Finally, while the researchers provide a comprehensive framework for quantifying bias, it is important to note that bias is a complex and multifaceted phenomenon. The metrics used in this study, while informative, may not capture the full range of biases present in news content. Adapting fake news detection to the era of large language models may be an important next step in addressing these challenges.
Conclusion
This study offers valuable insights into the potential biases that can arise in AI-generated news articles, and provides a robust methodology for quantifying and comparing these biases to human-written content. The findings underscore the need for continued research and development of techniques to detect and mitigate bias in AI-generated media, as the use of large language models for news generation becomes more prevalent.
By understanding the biases present in AI-generated news, researchers and developers can work to improve the reliability and trustworthiness of this type of content, ultimately supporting more informed and balanced public discourse.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Assessing Political Bias in Large Language Models
Luca Rettenberger, Markus Reischl, Mark Schutera
0
0
The assessment of bias within Large Language Models (LLMs) has emerged as a critical concern in the contemporary discourse surrounding Artificial Intelligence (AI) in the context of their potential impact on societal dynamics. Recognizing and considering political bias within LLM applications is especially important when closing in on the tipping point toward performative prediction. Then, being educated about potential effects and the societal behavior LLMs can drive at scale due to their interplay with human operators. In this way, the upcoming elections of the European Parliament will not remain unaffected by LLMs. We evaluate the political bias of the currently most popular open-source LLMs (instruct or assistant models) concerning political issues within the European Union (EU) from a German voter's perspective. To do so, we use the Wahl-O-Mat, a voting advice application used in Germany. From the voting advice of the Wahl-O-Mat we quantize the degree of alignment of LLMs with German political parties. We show that larger models, such as Llama3-70B, tend to align more closely with left-leaning political parties, while smaller models often remain neutral, particularly when prompted in English. The central finding is that LLMs are similarly biased, with low variances in the alignment concerning a specific party. Our findings underline the importance of rigorously assessing and making bias transparent in LLMs to safeguard the integrity and trustworthiness of applications that employ the capabilities of performative prediction and the invisible hand of machine learning prediction and language generation.
6/6/2024
💬
Large Language Models' Detection of Political Orientation in Newspapers
Alessio Buscemi, Daniele Proverbio
0
0
Democratic opinion-forming may be manipulated if newspapers' alignment to political or economical orientation is ambiguous. Various methods have been developed to better understand newspapers' positioning. Recently, the advent of Large Language Models (LLM), and particularly the pre-trained LLM chatbots like ChatGPT or Gemini, hold disruptive potential to assist researchers and citizens alike. However, little is know on whether LLM assessment is trustworthy: do single LLM agrees with experts' assessment, and do different LLMs answer consistently with one another? In this paper, we address specifically the second challenge. We compare how four widely employed LLMs rate the positioning of newspapers, and compare if their answers align with one another. We observe that this is not the case. Over a woldwide dataset, articles in newspapers are positioned strikingly differently by single LLMs, hinting to inconsistent training or excessive randomness in the algorithms. We thus raise a warning when deciding which tools to use, and we call for better training and algorithm development, to cover such significant gap in a highly sensitive matter for democracy and societies worldwide. We also call for community engagement in benchmark evaluation, through our open initiative navai.pro.
6/4/2024
Breaking News: Case Studies of Generative AI's Use in Journalism
Natalie Grace Brigham, Chongjiu Gao, Tadayoshi Kohno, Franziska Roesner, Niloofar Mireshghallah
0
0
Journalists are among the many users of large language models (LLMs). To better understand the journalist-AI interactions, we conduct a study of LLM usage by two news agencies through browsing the WildChat dataset, identifying candidate interactions, and verifying them by matching to online published articles. Our analysis uncovers instances where journalists provide sensitive material such as confidential correspondence with sources or articles from other agencies to the LLM as stimuli and prompt it to generate articles, and publish these machine-generated articles with limited intervention (median output-publication ROUGE-L of 0.62). Based on our findings, we call for further research into what constitutes responsible use of AI, and the establishment of clear guidelines and best practices on using LLMs in a journalistic context.
6/21/2024
💬
Bias of AI-Generated Content: An Examination of News Produced by Large Language Models
Xiao Fang, Shangkun Che, Minjia Mao, Hongzhe Zhang, Ming Zhao, Xiaohang Zhao
0
0
Large language models (LLMs) have the potential to transform our lives and work through the content they generate, known as AI-Generated Content (AIGC). To harness this transformation, we need to understand the limitations of LLMs. Here, we investigate the bias of AIGC produced by seven representative LLMs, including ChatGPT and LLaMA. We collect news articles from The New York Times and Reuters, both known for their dedication to provide unbiased news. We then apply each examined LLM to generate news content with headlines of these news articles as prompts, and evaluate the gender and racial biases of the AIGC produced by the LLM by comparing the AIGC and the original news articles. We further analyze the gender bias of each LLM under biased prompts by adding gender-biased messages to prompts constructed from these news headlines. Our study reveals that the AIGC produced by each examined LLM demonstrates substantial gender and racial biases. Moreover, the AIGC generated by each LLM exhibits notable discrimination against females and individuals of the Black race. Among the LLMs, the AIGC generated by ChatGPT demonstrates the lowest level of bias, and ChatGPT is the sole model capable of declining content generation when provided with biased prompts.
4/5/2024