Consistency Regularisation for Unsupervised Domain Adaptation in Monocular Depth Estimation
2405.17704
0
0

Abstract
In monocular depth estimation, unsupervised domain adaptation has recently been explored to relax the dependence on large annotated image-based depth datasets. However, this comes at the cost of training multiple models or requiring complex training protocols. We formulate unsupervised domain adaptation for monocular depth estimation as a consistency-based semi-supervised learning problem by assuming access only to the source domain ground truth labels. To this end, we introduce a pairwise loss function that regularises predictions on the source domain while enforcing perturbation consistency across multiple augmented views of the unlabelled target samples. Importantly, our approach is simple and effective, requiring only training of a single model in contrast to the prior work. In our experiments, we rely on the standard depth estimation benchmarks KITTI and NYUv2 to demonstrate state-of-the-art results compared to related approaches. Furthermore, we analyse the simplicity and effectiveness of our approach in a series of ablation studies. The code is available at url{https://github.com/AmirMaEl/SemiSupMDE}.
Create account to get full access
Overview
- This document provides formatting instructions for authors submitting papers to the CoLLAs 2024 conference.
- It covers guidelines for the structure, length, and layout of submitted papers.
- The instructions ensure a consistent format across all accepted submissions, making the review and publication process more efficient.
Plain English Explanation
This paper outlines the formatting requirements for authors who want to submit their research to the CoLLAs 2024 conference. The goal is to have all the papers look and feel similar, which makes it easier for the conference organizers to review the submissions and get them ready for publication.
The instructions cover things like:
- How long the paper should be
- The structure the paper should follow (e.g. sections, headings, etc.)
- The layout and formatting of the text, figures, and other elements
By following these guidelines, authors can ensure their paper fits the expected format for the conference. This helps create a cohesive proceedings that is easy for attendees to navigate and understand.
Technical Explanation
The formatting instructions outline the expected structure and layout for papers submitted to the CoLLAs 2024 conference. This includes guidelines for the overall length of the paper, the use of sections and headings, the formatting of text and figures, and other technical details.
The instructions specify that papers should be no more than [X] pages long, including the main text, references, and any appendices. The paper should be structured with clear section headings, following a standard organizational pattern.
For the text formatting, the instructions provide guidance on font size, line spacing, margin widths, and other typesetting details. They also cover the presentation of figures, tables, equations, and citations to ensure a consistent look and feel across all accepted submissions.
Additionally, the guidelines address specific requirements for the paper metadata, such as the title, author names, and affiliations. There are also instructions for how to properly format the references section.
By adhering to these formatting rules, authors can ensure their submissions are prepared in the expected format for the CoLLAs 2024 conference. This streamlines the review and publication process for the organizers.
Critical Analysis
The formatting instructions provided are comprehensive and well-structured, covering the key elements needed to ensure a consistent paper format for the CoLLAs 2024 conference. The guidelines appear to be thorough and detailed, which should help authors prepare their submissions correctly.
One potential limitation is the lack of flexibility - the strict formatting rules may make it challenging for authors to express their research in their preferred style. However, the consistency across submissions is likely more important for the conference organizers and attendees.
Additionally, the instructions do not address potential issues that could arise, such as how to handle papers that exceed the page limit or papers that do not strictly adhere to the formatting guidelines. It would be helpful if the instructions provided some guidance on how such cases would be handled.
Overall, the formatting instructions seem well-designed to support the efficient review and publication of papers for the CoLLAs 2024 conference. With clear guidance on the expected structure and layout, authors should be able to prepare their submissions accordingly.
Conclusion
The formatting instructions for the CoLLAs 2024 conference provide authors with a clear set of guidelines to follow when preparing their paper submissions. By adhering to these rules, authors can ensure their work is presented in a consistent format that aligns with the conference's expectations.
The instructions cover key aspects such as paper length, section structure, text formatting, and figure/table presentation. This standardization helps the conference organizers review the submissions and compile the proceedings more efficiently.
While the strict formatting requirements may pose some challenges for authors, the overall benefits of a cohesive proceedings likely outweigh any limitations. The guidelines appear to be comprehensive and well-designed to support a successful CoLLAs 2024 conference.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
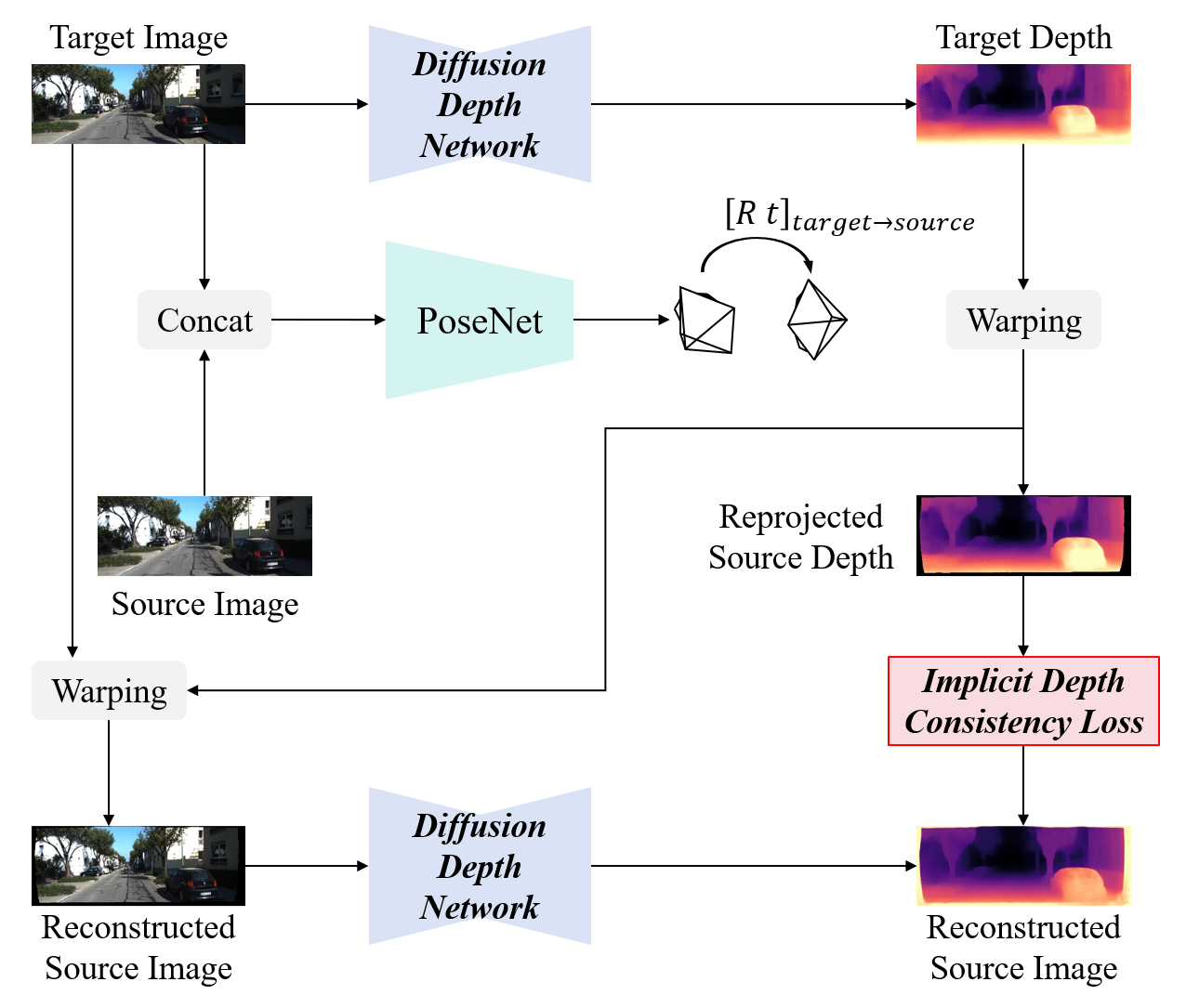
Unsupervised Monocular Depth Estimation Based on Hierarchical Feature-Guided Diffusion
Runze Liu, Dongchen Zhu, Guanghui Zhang, Yue Xu, Wenjun Shi, Xiaolin Zhang, Lei Wang, Jiamao Li
0
0
Unsupervised monocular depth estimation has received widespread attention because of its capability to train without ground truth. In real-world scenarios, the images may be blurry or noisy due to the influence of weather conditions and inherent limitations of the camera. Therefore, it is particularly important to develop a robust depth estimation model. Benefiting from the training strategies of generative networks, generative-based methods often exhibit enhanced robustness. In light of this, we employ a well-converging diffusion model among generative networks for unsupervised monocular depth estimation. Additionally, we propose a hierarchical feature-guided denoising module. This model significantly enriches the model's capacity for learning and interpreting depth distribution by fully leveraging image features to guide the denoising process. Furthermore, we explore the implicit depth within reprojection and design an implicit depth consistency loss. This loss function serves to enhance the performance of the model and ensure the scale consistency of depth within a video sequence. We conduct experiments on the KITTI, Make3D, and our self-collected SIMIT datasets. The results indicate that our approach stands out among generative-based models, while also showcasing remarkable robustness.
6/17/2024

Self-Supervised Monocular Depth Estimation in the Dark: Towards Data Distribution Compensation
Haolin Yang, Chaoqiang Zhao, Lu Sheng, Yang Tang
0
0
Nighttime self-supervised monocular depth estimation has received increasing attention in recent years. However, using night images for self-supervision is unreliable because the photometric consistency assumption is usually violated in the videos taken under complex lighting conditions. Even with domain adaptation or photometric loss repair, performance is still limited by the poor supervision of night images on trainable networks. In this paper, we propose a self-supervised nighttime monocular depth estimation method that does not use any night images during training. Our framework utilizes day images as a stable source for self-supervision and applies physical priors (e.g., wave optics, reflection model and read-shot noise model) to compensate for some key day-night differences. With day-to-night data distribution compensation, our framework can be trained in an efficient one-stage self-supervised manner. Though no nighttime images are considered during training, qualitative and quantitative results demonstrate that our method achieves SoTA depth estimating results on the challenging nuScenes-Night and RobotCar-Night compared with existing methods.
4/23/2024
📈
Mining Supervision for Dynamic Regions in Self-Supervised Monocular Depth Estimation
Hoang Chuong Nguyen, Tianyu Wang, Jose M. Alvarez, Miaomiao Liu
0
0
This paper focuses on self-supervised monocular depth estimation in dynamic scenes trained on monocular videos. Existing methods jointly estimate pixel-wise depth and motion, relying mainly on an image reconstruction loss. Dynamic regions1 remain a critical challenge for these methods due to the inherent ambiguity in depth and motion estimation, resulting in inaccurate depth estimation. This paper proposes a self-supervised training framework exploiting pseudo depth labels for dynamic regions from training data. The key contribution of our framework is to decouple depth estimation for static and dynamic regions of images in the training data. We start with an unsupervised depth estimation approach, which provides reliable depth estimates for static regions and motion cues for dynamic regions and allows us to extract moving object information at the instance level. In the next stage, we use an object network to estimate the depth of those moving objects assuming rigid motions. Then, we propose a new scale alignment module to address the scale ambiguity between estimated depths for static and dynamic regions. We can then use the depth labels generated to train an end-to-end depth estimation network and improve its performance. Extensive experiments on the Cityscapes and KITTI datasets show that our self-training strategy consistently outperforms existing self/unsupervised depth estimation methods.
4/24/2024
🤷
Unsupervised Domain Adaptation for Low-dose CT Reconstruction via Bayesian Uncertainty Alignment
Kecheng Chen, Jie Liu, Renjie Wan, Victor Ho-Fun Lee, Varut Vardhanabhuti, Hong Yan, Haoliang Li
0
0
Low-dose computed tomography (LDCT) image reconstruction techniques can reduce patient radiation exposure while maintaining acceptable imaging quality. Deep learning is widely used in this problem, but the performance of testing data (a.k.a. target domain) is often degraded in clinical scenarios due to the variations that were not encountered in training data (a.k.a. source domain). Unsupervised domain adaptation (UDA) of LDCT reconstruction has been proposed to solve this problem through distribution alignment. However, existing UDA methods fail to explore the usage of uncertainty quantification, which is crucial for reliable intelligent medical systems in clinical scenarios with unexpected variations. Moreover, existing direct alignment for different patients would lead to content mismatch issues. To address these issues, we propose to leverage a probabilistic reconstruction framework to conduct a joint discrepancy minimization between source and target domains in both the latent and image spaces. In the latent space, we devise a Bayesian uncertainty alignment to reduce the epistemic gap between the two domains. This approach reduces the uncertainty level of target domain data, making it more likely to render well-reconstructed results on target domains. In the image space, we propose a sharpness-aware distribution alignment to achieve a match of second-order information, which can ensure that the reconstructed images from the target domain have similar sharpness to normal-dose CT images from the source domain. Experimental results on two simulated datasets and one clinical low-dose imaging dataset show that our proposed method outperforms other methods in quantitative and visualized performance.
6/4/2024