Constructing the CORD-19 Vaccine Dataset

0

Sign in to get full access
Overview
- The paper describes the process of constructing the CORD-19 Vaccine Dataset, a dataset that contains information related to COVID-19 vaccines extracted from the COVID-19 Open Research Dataset (CORD-19).
- The dataset includes user and contextual information extracted from the CORD-19 corpus, which can be used for various tasks such as vaccine sentiment analysis, policy-making, and vaccine hesitancy research.
- The extraction process involved identifying relevant articles, extracting user and contextual information, and preparing the data for analysis.
Plain English Explanation
The researchers wanted to create a dataset that could be used to study people's attitudes and opinions about COVID-19 vaccines. They took information from a large collection of research papers on COVID-19, called the CORD-19 dataset, and extracted specific details that could be useful for this purpose.
For example, they looked for information on who was writing about the vaccines (the "user" information) and the context around the vaccine discussion (the "contextual" information). This could include things like the author's background, the purpose of the paper, and the overall sentiment expressed towards the vaccines.
Technical Explanation
The extraction phase involved the following steps:
-
Identifying relevant articles: The researchers first identified articles from the CORD-19 corpus that were related to COVID-19 vaccines. This was done using keyword searches and filtering techniques.
-
Extracting user and contextual information: For the selected articles, the researchers extracted various user and contextual features, such as the author's background, the purpose of the paper, and the overall sentiment expressed towards the vaccines.
-
Preparing the data: The extracted information was then organized and formatted into a structured dataset, making it ready for further analysis and research.
The resulting CORD-19 Vaccine Dataset can be used for a variety of tasks, such as vaccine sentiment analysis, policy-making, and vaccine hesitancy research.
Critical Analysis
The paper provides a thorough and well-documented approach to constructing the CORD-19 Vaccine Dataset. The researchers have clearly identified the need for such a dataset and have carefully designed the extraction process to ensure the quality and relevance of the extracted information.
However, the paper does not address potential limitations or biases in the dataset. For example, the dataset may be skewed towards certain demographic groups or geographical regions, depending on the distribution of the original CORD-19 corpus. Additionally, the accuracy and completeness of the extracted user and contextual information may vary, depending on the quality of the source data and the robustness of the extraction methods.
Further research could be conducted to assess the representativeness and generalizability of the CORD-19 Vaccine Dataset, as well as to explore ways to improve the extraction and curation processes to address any identified limitations.
Conclusion
The CORD-19 Vaccine Dataset is a valuable resource for researchers and policymakers interested in understanding public perception and attitudes towards COVID-19 vaccines. By extracting user and contextual information from the CORD-19 corpus, the researchers have created a dataset that can be used for a variety of tasks, such as sentiment analysis, policy-making, and vaccine hesitancy research.
While the paper presents a robust approach to constructing the dataset, further work may be needed to address potential limitations and biases. Nonetheless, the CORD-19 Vaccine Dataset represents an important contribution to the field and has the potential to inform and improve public health efforts related to COVID-19 vaccination.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Constructing the CORD-19 Vaccine Dataset
Manisha Singh, Divy Sharma, Alonso Ma, Bridget Tyree, Margaret Mitchell
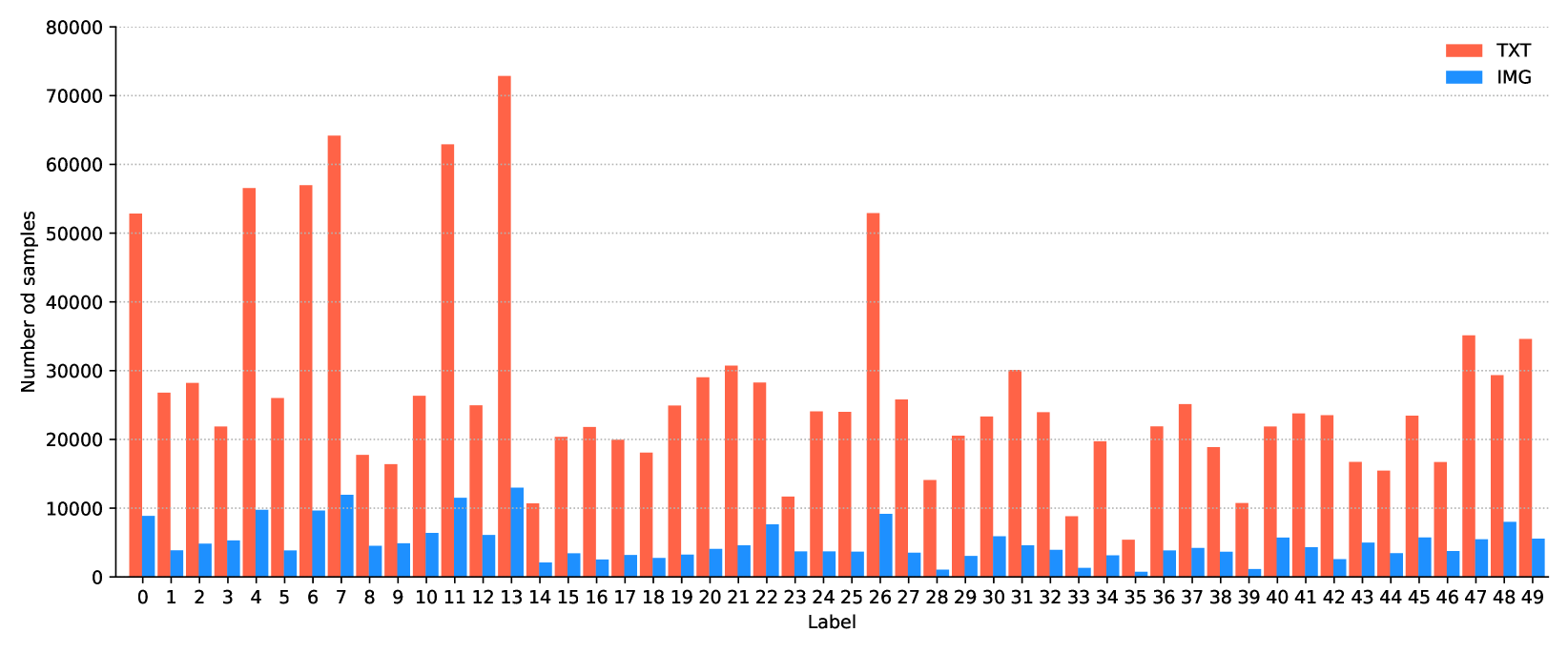
We introduce new dataset 'CORD-19-Vaccination' to cater to scientists specifically looking into COVID-19 vaccine-related research. This dataset is extracted from CORD-19 dataset [Wang et al., 2020] and augmented with new columns for language detail, author demography, keywords, and topic per paper. Facebook's fastText model is used to identify languages [Joulin et al., 2016]. To establish author demography (author affiliation, lab/institution location, and lab/institution country columns) we processed the JSON file for each paper and then further enhanced using Google's search API to determine country values. 'Yake' was used to extract keywords from the title, abstract, and body of each paper and the LDA (Latent Dirichlet Allocation) algorithm was used to add topic information [Campos et al., 2020, 2018a,b]. To evaluate the dataset, we demonstrate a question-answering task like the one used in the CORD-19 Kaggle challenge [Goldbloom et al., 2022]. For further evaluation, sequential sentence classification was performed on each paper's abstract using the model from Dernoncourt et al. [2016]. We partially hand annotated the training dataset and used a pre-trained BERT-PubMed layer. 'CORD- 19-Vaccination' contains 30k research papers and can be immensely valuable for NLP research such as text mining, information extraction, and question answering, specific to the domain of COVID-19 vaccine research.
Read more7/29/2024
0
WarCov -- Large multilabel and multimodal dataset from social platform
Weronika Borek-Marciniec, Pawel Zyblewski, Jakub Klikowski, Pawel Ksieniewicz
In the classification tasks, from raw data acquisition to the curation of a dataset suitable for use in evaluating machine learning models, a series of steps - often associated with high costs - are necessary. In the case of Natural Language Processing, initial cleaning and conversion can be performed automatically, but obtaining labels still requires the rationalized input of human experts. As a result, even though many articles often state that the world is filled with data, data scientists suffer from its shortage. It is crucial in the case of natural language applications, which is constantly evolving and must adapt to new concepts or events. For example, the topic of the COVID-19 pandemic and the vocabulary related to it would have been mostly unrecognizable before 2019. For this reason, creating new datasets, also in languages other than English, is still essential. This work presents a collection of 3~187~105 posts in Polish about the pandemic and the war in Ukraine published on popular social media platforms in 2022. The collection includes not only preprocessed texts but also images so it can be used also for multimodal recognition tasks. The labels define posts' topics and were created using hashtags accompanying the posts. The work presents the process of curating a dataset from acquisition to sample pattern recognition experiments.
Read more6/18/2024
⚙️
0
A Labelled Dataset for Sentiment Analysis of Videos on YouTube, TikTok, and Other Sources about the 2024 Outbreak of Measles
Nirmalya Thakur, Vanessa Su, Mingchen Shao, Kesha A. Patel, Hongseok Jeong, Victoria Knieling, Andrew Bian
The work of this paper presents a dataset that contains the data of 4011 videos about the ongoing outbreak of measles published on 264 websites on the internet between January 1, 2024, and May 31, 2024. The dataset is available at https://dx.doi.org/10.21227/40s8-xf63. These websites primarily include YouTube and TikTok, which account for 48.6% and 15.2% of the videos, respectively. The remainder of the websites include Instagram and Facebook as well as the websites of various global and local news organizations. For each of these videos, the URL of the video, title of the post, description of the post, and the date of publication of the video are presented as separate attributes in the dataset. After developing this dataset, sentiment analysis (using VADER), subjectivity analysis (using TextBlob), and fine-grain sentiment analysis (using DistilRoBERTa-base) of the video titles and video descriptions were performed. This included classifying each video title and video description into (i) one of the sentiment classes i.e. positive, negative, or neutral, (ii) one of the subjectivity classes i.e. highly opinionated, neutral opinionated, or least opinionated, and (iii) one of the fine-grain sentiment classes i.e. fear, surprise, joy, sadness, anger, disgust, or neutral. These results are presented as separate attributes in the dataset for the training and testing of machine learning algorithms for performing sentiment analysis or subjectivity analysis in this field as well as for other applications. Finally, this paper also presents a list of open research questions that may be investigated using this dataset.
Read more7/19/2024
🏷️
0
COVID-19 Twitter Sentiment Classification Using Hybrid Deep Learning Model Based on Grid Search Methodology
Jitendra Tembhurne, Anant Agrawal, Kirtan Lakhotia
In the contemporary era, social media platforms amass an extensive volume of social data contributed by their users. In order to promptly grasp the opinions and emotional inclinations of individuals regarding a product or event, it becomes imperative to perform sentiment analysis on the user-generated content. Microblog comments often encompass both lengthy and concise text entries, presenting a complex scenario. This complexity is particularly pronounced in extensive textual content due to its rich content and intricate word interrelations compared to shorter text entries. Sentiment analysis of public opinion shared on social networking websites such as Facebook or Twitter has evolved and found diverse applications. However, several challenges remain to be tackled in this field. The hybrid methodologies have emerged as promising models for mitigating sentiment analysis errors, particularly when dealing with progressively intricate training data. In this article, to investigate the hesitancy of COVID-19 vaccination, we propose eight different hybrid deep learning models for sentiment classification with an aim of improving overall accuracy of the model. The sentiment prediction is achieved using embedding, deep learning model and grid search algorithm on Twitter COVID-19 dataset. According to the study, public sentiment towards COVID-19 immunization appears to be improving with time, as evidenced by the gradual decline in vaccine reluctance. Through extensive evaluation, proposed model reported an increased accuracy of 98.86%, outperforming other models. Specifically, the combination of BERT, CNN and GS yield the highest accuracy, while the combination of GloVe, BiLSTM, CNN and GS follows closely behind with an accuracy of 98.17%. In addition, increase in accuracy in the range of 2.11% to 14.46% is reported by the proposed model in comparisons with existing works.
Read more6/18/2024