Fine-Grained Named Entities for Corona News
2404.13439
0
0
Abstract
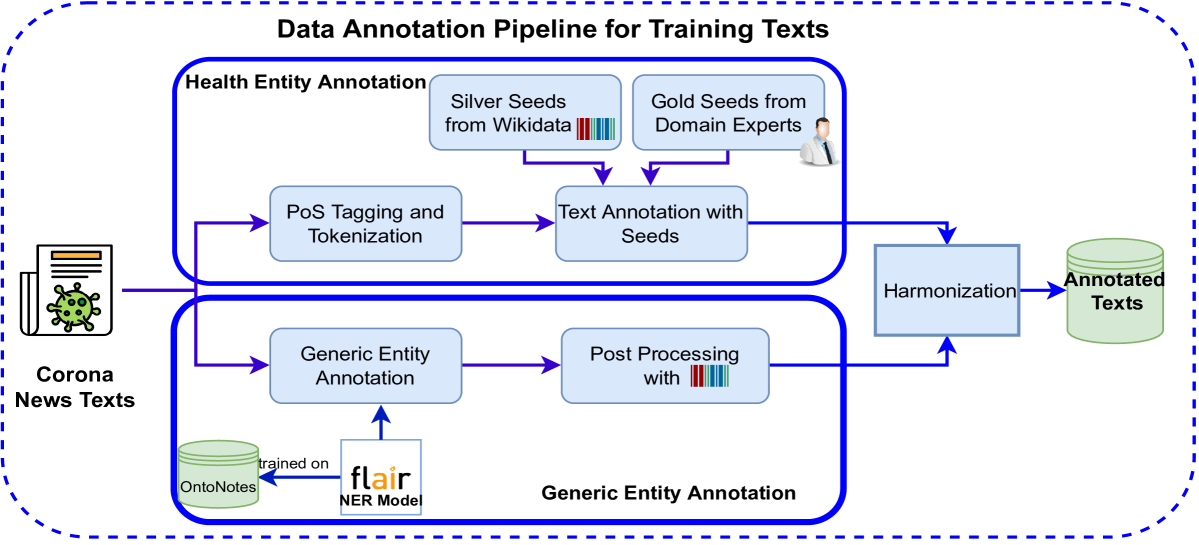
Information resources such as newspapers have produced unstructured text data in various languages related to the corona outbreak since December 2019. Analyzing these unstructured texts is time-consuming without representing them in a structured format; therefore, representing them in a structured format is crucial. An information extraction pipeline with essential tasks -- named entity tagging and relation extraction -- to accomplish this goal might be applied to these texts. This study proposes a data annotation pipeline to generate training data from corona news articles, including generic and domain-specific entities. Named entity recognition models are trained on this annotated corpus and then evaluated on test sentences manually annotated by domain experts evaluating the performance of a trained model. The code base and demonstration are available at https://github.com/sefeoglu/coronanews-ner.git.
Create account to get full access
Overview
- This paper focuses on developing a fine-grained named entity recognition (NER) system for extracting relevant information from news articles related to the COVID-19 pandemic.
- The researchers aim to capture a wide range of entity types that are crucial for understanding the impact and context of the pandemic, going beyond the typical named entity categories.
- The proposed approach leverages state-of-the-art NER models and customizes them to the COVID-19 domain, using a large corpus of news articles to train and evaluate the system.
Plain English Explanation
The paper presents a method for identifying and categorizing different types of named entities, such as people, organizations, and locations, within news articles about the COVID-19 pandemic. This is relevant to the task of intent detection and entity extraction from biomedical literature.
The researchers recognized that the typical named entity categories used in general-purpose NER systems might not capture all the relevant information needed to understand the context and impact of the pandemic. So, they developed a more fine-grained NER system that can identify a wider range of entity types, such as specific diseases, medical treatments, and government policies.
By training their NER model on a large dataset of COVID-19-related news articles, the researchers aimed to create a system that can accurately identify and classify a diverse set of named entities relevant to the pandemic. This is similar to the approach used in the paper on automatic detection of relevant information for financial predictions and forecasts.
The fine-grained NER system developed in this paper can be used to extract valuable information from news reports, helping researchers, policymakers, and the public better understand the evolving situation surrounding the COVID-19 outbreak.
Technical Explanation
The researchers developed a fine-grained NER system specifically tailored to the COVID-19 domain. This builds on the work in the paper on leveraging contextual information for effective entity salience detection.
They started with a state-of-the-art NER model as the base and then customized it to recognize a more extensive set of entity types relevant to the pandemic, such as specific diseases, medical treatments, government policies, and economic impacts. The approach is similar to the structure-aware text-to-graph model presented in the Grapher paper.
To train and evaluate the fine-grained NER system, the researchers compiled a large corpus of news articles related to COVID-19, manually annotating a subset of the data with the expanded set of entity types. They then fine-tuned the base NER model on this annotated dataset, using techniques like transfer learning to leverage the model's general language understanding capabilities.
The resulting fine-grained NER system demonstrated improved performance in identifying and classifying a wide range of pandemic-related entities compared to general-purpose NER models. This aligns with the findings from the cross-lingual named entity corpus for Slavic languages paper.
Critical Analysis
The paper presents a valuable contribution to the field of NER, particularly in the context of the COVID-19 pandemic. By developing a more fine-grained and specialized NER system, the researchers have shown the potential to extract richer and more contextual information from news reports.
However, the study is limited to a specific domain (COVID-19) and may not generalize well to other types of news or text. The researchers acknowledge that the performance of the fine-grained NER system could be influenced by the quality and breadth of the training data, and further research may be needed to understand its applicability to other domains.
Additionally, the paper does not provide a detailed analysis of the potential biases or errors that may arise in the NER system's predictions. It would be helpful to understand the limitations and potential pitfalls of the approach, as well as strategies for addressing them.
Conclusion
This paper presents a novel approach to named entity recognition for COVID-19-related news articles, going beyond the typical entity types to capture a more fine-grained set of information relevant to understanding the pandemic. The researchers have demonstrated the potential of this specialized NER system to extract valuable insights from news reports, which could be beneficial for researchers, policymakers, and the general public.
The findings of this study highlight the importance of domain-specific NER models in unlocking the full potential of textual data, particularly in rapidly evolving and high-impact scenarios like the COVID-19 pandemic. Further research and refinement of the approach could lead to even more powerful tools for information extraction and analysis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Scalable Detection of Salient Entities in News Articles
Eliyar Asgarieh, Kapil Thadani, Neil O'Hare
0
0
News articles typically mention numerous entities, a large fraction of which are tangential to the story. Detecting the salience of entities in articles is thus important to applications such as news search, analysis and summarization. In this work, we explore new approaches for efficient and effective salient entity detection by fine-tuning pretrained transformer models with classification heads that use entity tags or contextualized entity representations directly. Experiments show that these straightforward techniques dramatically outperform prior work across datasets with varying sizes and salience definitions. We also study knowledge distillation techniques to effectively reduce the computational cost of these models without affecting their accuracy. Finally, we conduct extensive analyses and ablation experiments to characterize the behavior of the proposed models.
6/3/2024
A Continual Relation Extraction Approach for Knowledge Graph Completeness
Sefika Efeoglu
0
0
Representing unstructured data in a structured form is most significant for information system management to analyze and interpret it. To do this, the unstructured data might be converted into Knowledge Graphs, by leveraging an information extraction pipeline whose main tasks are named entity recognition and relation extraction. This thesis aims to develop a novel continual relation extraction method to identify relations (interconnections) between entities in a data stream coming from the real world. Domain-specific data of this thesis is corona news from German and Austrian newspapers.
4/30/2024
Intent Detection and Entity Extraction from BioMedical Literature
Ankan Mullick, Mukur Gupta, Pawan Goyal
0
0
Biomedical queries have become increasingly prevalent in web searches, reflecting the growing interest in accessing biomedical literature. Despite recent research on large-language models (LLMs) motivated by endeavours to attain generalized intelligence, their efficacy in replacing task and domain-specific natural language understanding approaches remains questionable. In this paper, we address this question by conducting a comprehensive empirical evaluation of intent detection and named entity recognition (NER) tasks from biomedical text. We show that Supervised Fine Tuned approaches are still relevant and more effective than general-purpose LLMs. Biomedical transformer models such as PubMedBERT can surpass ChatGPT on NER task with only 5 supervised examples.
4/5/2024
📊
Developing an efficient corpus using Ensemble Data cleaning approach
Md Taimur Ahad
0
0
Despite the observable benefit of Natural Language Processing (NLP) in processing a large amount of textual medical data within a limited time for information retrieval, a handful of research efforts have been devoted to uncovering novel data-cleaning methods. Data cleaning in NLP is at the centre point for extracting validated information. Another observed limitation in the NLP domain is having limited medical corpora that provide answers to a given medical question. Realising the limitations and challenges from two perspectives, this research aims to clean a medical dataset using ensemble techniques and to develop a corpus. The corpora expect that it will answer the question based on the semantic relationship of corpus sequences. However, the data cleaning method in this research suggests that the ensemble technique provides the highest accuracy (94%) compared to the single process, which includes vectorisation, exploratory data analysis, and feeding the vectorised data. The second aim of having an adequate corpus was realised by extracting answers from the dataset. This research is significant in machine learning, specifically data cleaning and the medical sector, but it also underscores the importance of NLP in the medical field, where accurate and timely information extraction can be a matter of life and death. It establishes text data processing using NLP as a powerful tool for extracting valuable information like image data.
6/4/2024